Block RAM是PL部分的存储器阵列,为了与DRAM(分布式RAM)区分开,所以叫块RAM。ZYNQ的每一个BRAM 36KB,7020的BRAM有140个(4.9M),7030有265个(9.3M),7045有545个(19.2M)。每一个BRAM都有两个共享数据的独立端口,当然是可以配置的,可用于片内数据缓存、FIFO缓冲。
在Vivado里有一个IP核叫Block Memory Generator,它使用FPGA的BRAM资源为我们提供可编程的RAM。
1.读和写由时钟控制,
2.数据宽度是可编程的,
Each port can be configured as 32K ×1, 16K ×2, 8K ×4, 4K ×9 (or x8), 2K ×18 (or x16), 1K ×36 (or 32),
or 512 ×72 (or x64). The two ports can have different widths without any constraints.
Only in simple dual-port (SDP) mode can data widths of greater than 18 bits (18 Kb RAM) or 36 bits
(36 Kb RAM) be accessed. In this mode, one port is dedicated to read operations, the other to write
operations. In SDP mode, one side (read or write) can be variable, while the other is fixed to 32/36 or
64/72.
Both sides of the dual-port 36 Kb RAM can be of variable width.
Two adjacent 36 Kb block RAMs can be configured as one 64K × 1 dual-port RAM without any
additional logic.
3.配置成FIFO,
有一个内置的FIFO Controller,FIFO的宽度和深度是可编程的。
可以配置成如下应用:
• Single-port RAM: Processor scratch RAM, look-up tables
• Simple Dual-port RAM: Content addressable memories, FIFOs
• True Dual-port RAM: Multi-processor storage
• Single-port ROM: Program code storage, initialization ROM
• Dual-port ROM: Single ROM shared between two processors/systems
PS和BRAM之间的事务由AXI BRAM Controller控制,可以是AXI总线形式,也可以是AXILite总线形式。
创建单端口RAM,读/写
新建一个工程,创建一个Block Design,添加zynq核,另外为了使用BRAM,需要添加两个IP核:Block Memory Generator和AXI BRAM Cotroller。
配置成单端口:
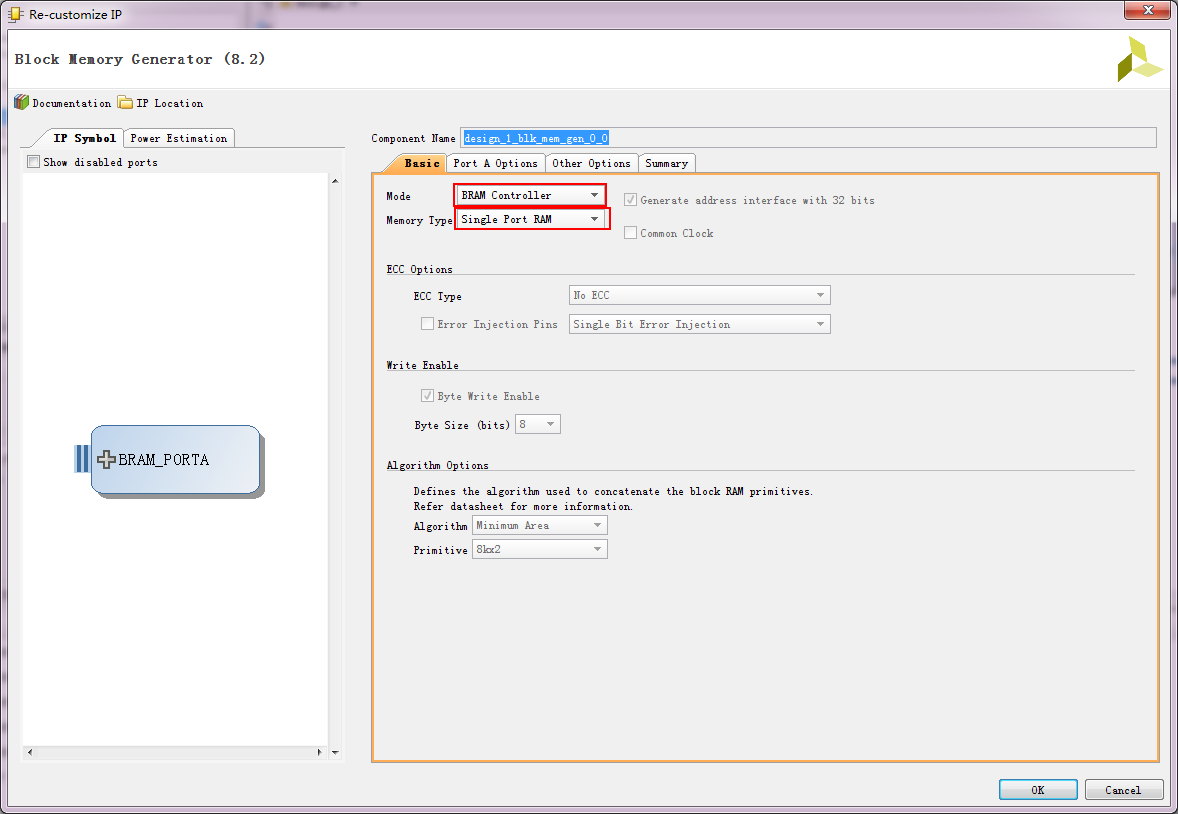
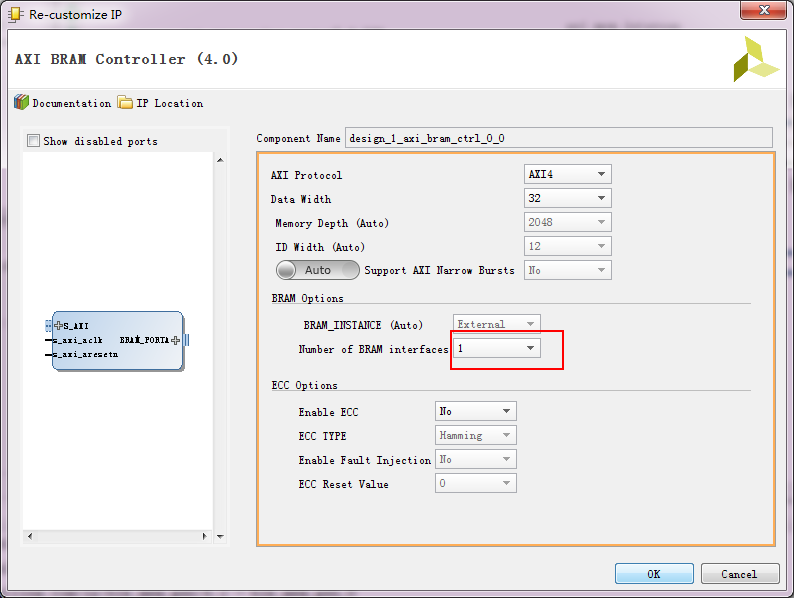
其他配置可以点进去看看。
连接完是这个样子:
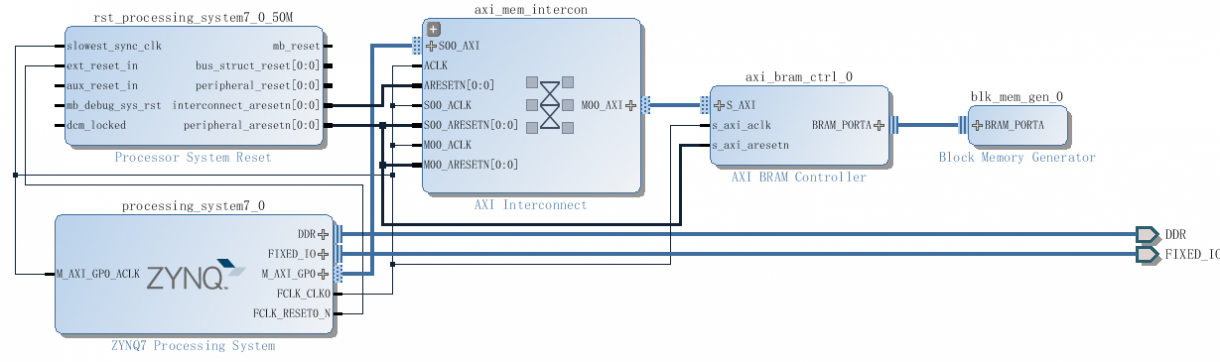
BRAM的大小和首地址可以手动调:

现在PS可以操作这个8M的RAM了。
生成比特流后,打开SDK。
对BRAM的操作是很好理解的,一切通过地址:
#include
#include "platform.h"
#include "xil_io.h"
#include "xparameters.h"
int main(void)
{
int word1,word2,word3,word4;
Xil_Out8(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 0, 0xAB);//第一个字,4字节
Xil_Out8(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 1, 0xFF);
Xil_Out8(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 2, 0x34);
Xil_Out8(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 3, 0x8C);
Xil_Out8(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 4, 0xEF);//第二个字,4字节
Xil_Out8(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 5, 0xBE);
Xil_Out8(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 6, 0xAD);
Xil_Out8(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 7, 0xDE);
Xil_Out16(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 0x10, 0x1209);//第三个字,4字节
Xil_Out16(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 0x12, 0xFE31);
Xil_Out16(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 0x14, 0x6587);//第四个字,4字节
Xil_Out16(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 0x16, 0xAAAA);
Xil_Out32(0xE000A244, 0x0AAA); //第5个字,4字节
word1 = Xil_In32(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR);
word2 = Xil_In32(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 8);
word3 = Xil_In32(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 0x10);
word4 = Xil_In32(0xE000A244);
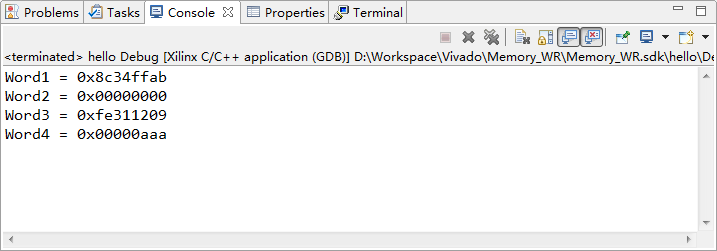
printf("Word1 = 0x%08x\n\r", word1);
printf("Word2 = 0x%08x\n\r", word2);
printf("Word3 = 0x%08x\n\r", word3);
printf("Word4 = 0x%08x\n\r", word4);
return(0);
}
打印结果:
创建真正的双端口RAM,读/写
这里我们实现的功能是利用PS的GP0和GP1接口,一个口负责读,一个口负责写,读写通过RAM独立的Port。同样是添加那些IP核,不过配置要变:
两个Master GP口都要勾选上:

使用True双端口,才可以一个口读,一个口写:

添加两个控制器,BRAM interface都只要1个,分别负责读/写。
在自动连接的时候,要注意系统是否为我们进行了正确的连接,错误的手动改一下:
ctrl1连接到GP0,正确:
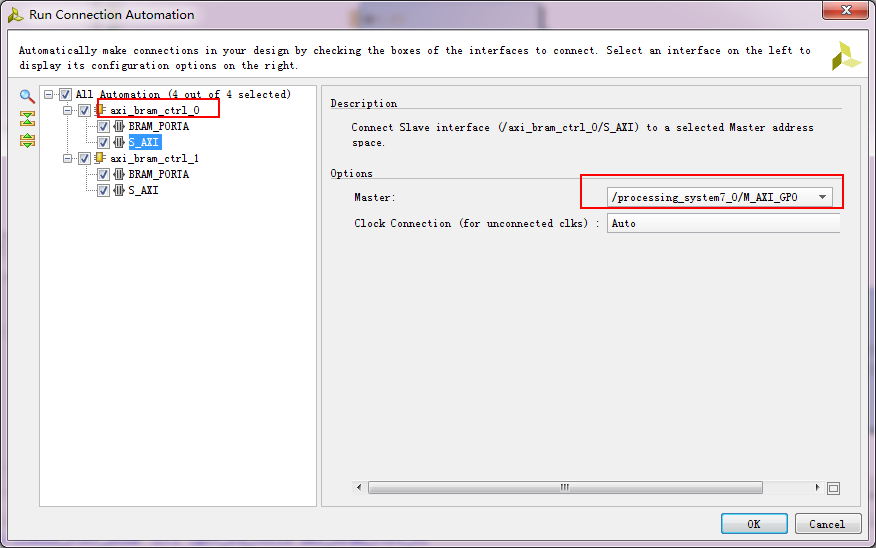
ctrl2连接到GP1,改一下:
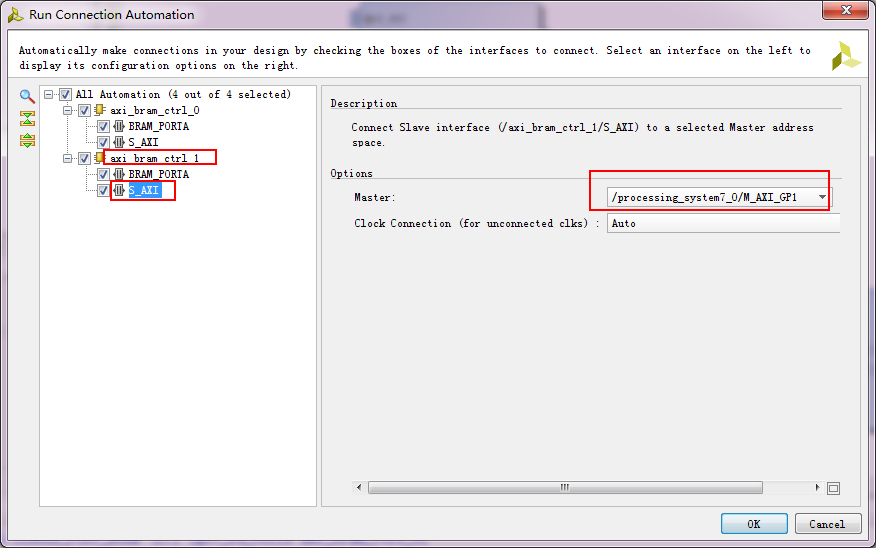
系统搭建完后:

为了后面看效果,这里我们修改了基地址,看看到底是不是可以通过不同的地址对存储进行读写:

生成比特文件,加载到SDJK。
读写方式依然是一样的,唯一要注意的是基地址到底是什么:
#include
#include "platform.h"
#include "xparameters.h"
#include "xil_io.h"
int main()
{
int i;
u32 Value = 0x00;
init_platform();
printf("Hello World\n\r");
for(i = 0 ; i < 3 ; i++)
Xil_Out32(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 4*i, Value + i);
for(i = 0 ; i < 3 ; i++)
{
Value = Xil_In32(XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 4*i);
xil_printf("Address:%x Value:%x\r\n",XPAR_AXI_BRAM_CTRL_0_S_AXI_BASEADDR + 4*i,Value);
}
printf("\r\n");
printf("\r\n");
for(i = 0 ; i < 3 ; i++)
{
Value = Xil_In32(XPAR_AXI_BRAM_CTRL_1_S_AXI_BASEADDR + 4*i);
xil_printf("Address:%x Value:%x\r\n",XPAR_AXI_BRAM_CTRL_1_S_AXI_BASEADDR + 4*i,Value);
}
cleanup_platform();
return 0;
}
打印的结果:
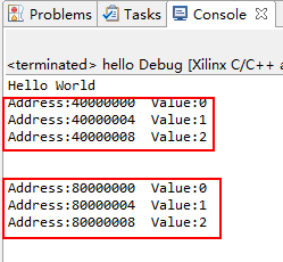
完全正确,我们可以通过两个地址对同一块存储操作,其实这是两个进程完成的,正因为这样双端口效率才高!
BRAM的主要作为计算时的临时存储。除了BRAM(Block RAM)以外,zynq还有一个DRAM((Distributed RAM)),即分布式RAM,这两个功能相似,结构不同,使用场景略有区别。
结构不同:
1.BRAM是使用FPGA中的整块双口RAM资源
2.DRAM是FPGA中的查找表(LUT)拼凑出来的,要占用逻辑资源。
3.物理上看,BRAM 是单纯的存储资源,但是要一块一块的用,不像DRAM 想要多少bit都可以。
4.DRAM可以是纯组合逻辑,即给出地址马上出数据,BRAM是有时钟的。
CLB是xilinx基本逻辑单元,每个CLB包含两个slices,每个slices由4个(A,B,C,D)6输入LUT和8个寄存器组成。

slice分为两种类型 SLICEL, SLICEM 。SLICEL可用于产生逻辑,算术,ROM。 SLICEM除以上作用外还可配置成分布式RAM或32位的移位寄存器。每个CLB可包含两个SLICEL或者一个SLICEL与一个SLICEM.
7系列的LUT可以配置成6输入1输出的LUT,或者两个5输入具有相同地址或逻辑输入的独立输出的LUT。4个这样的LUT+8个Flip Flop+多路选择器和进位链构成1个Slice。
SLICEM可以配置成分布式RAM,一个SLICEM可以配置成以下容量的RAM:
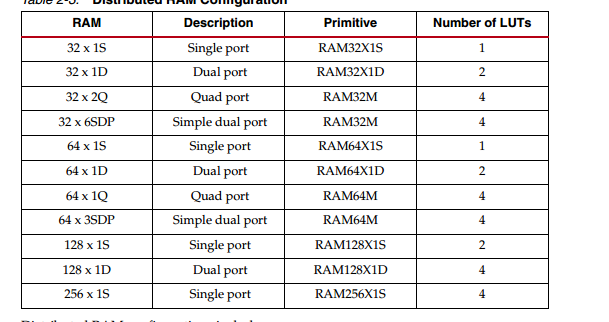
1个LUT最多配置成64位RAM,多bit的情况需要增加相应倍数的LUT进行并联。
另外: SLICEM中的LUT能在不使用触发器的情况下设置成32bit的移位寄存器, 4个LUT可级联成128bit的移位寄存器。并且能够进行SLICEM间的级联形成更大规模的移位寄存器。
如何选择:
1、较大的存储应用,建议用BRAM;零星的小RAM,一般就用DRAM。(小于或等于64bit容量的用分布式实现,深度在64~128之间的,若无额外的block可用分布式RAM。数据宽度大于16时用Block RAM)
2、dram可以是纯组合逻辑,即给出地址马上出数据,也可以加上register变成有时钟的ram。而bram一定是有时钟的。(要求异步读取就使用分布式RAM)
3、如果要产生大的FIFO或timing要求较高,就用Block RAM。否则,就可以用Distributed RAM。块RAM是比较大块的RAM,即使用了它的一小部分,那么整个Block RAM就不能再用了。所以,当你要用的RAM比较小,时序要求不高时,可以用分布式RAM,节省资源。
FPGA中的资源位置是固定的,例如BRAM就是一列一列分布的(存储器阵列),会产生较大的布线时延。在大规模FPGA中,如果用光所有的BRAM,性能一般会下降,甚至出现route不通的情况,就是这个原因。
4.用户申请存储资源,FPGA先提供Block RAM ,当Block RAM 数量不够时再用分布式RAM补充。
总结:灵活的运用B-RAM和D-RAM可以有效利用FPGA资源,提升性能。不管是什么RAM,它都是RAM,用于存储数据,可以随机访问,先用起来再去细究。
---------------------
作者:ChuanjieZhu
来源:CSDN
原文:https://blog.csdn.net/u014485485/article/details/78882027





