硬件资源
PYNQ包括有
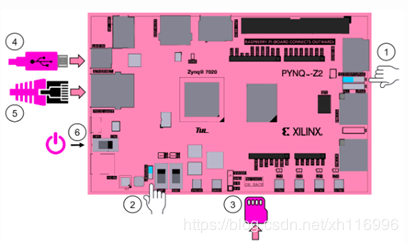
① 选择板子的启动方式,分别从JTAG、QSPI Flash和SD卡启动。
JTAG启动方式:通过④Micro-USB接口连接到电脑上,下载bit文件和elf文件,进行在线调试;
Flash启动方式:将程序烧录到Flash中,断电后从Flash中开始运行程序;
SD启动方式:将镜像文件拷贝到SD卡中,从SD卡中读取运行程序。

② 选择电源供电模式,分为从USB供电运行和从外部电源供电运行。
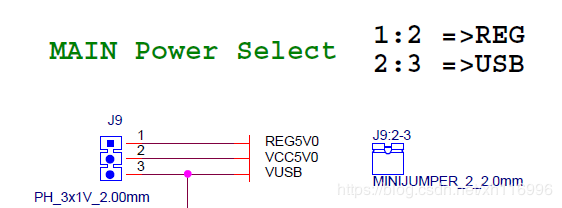
③SD卡配置
PYNQ从SD卡启动,SD卡中配置有启动镜像文件,需要有一块空白的SD卡、读卡器和配置教程。
启动PYNQ
整体认识
PYNQ是利用Python语言对ZYNQ进行开发的项目。PYNQ从SD卡中启动,从镜像文件中加载系统程序,通过网口连接到浏览器上的Jupyter Notebook,在上面进行Python开发。
ZYNQ
ZYNQ包括一个双核ARM Cortex-A9处理器和一个FPGA,即处理器系统(PS)和可编程逻辑(PL),主要通过AXI接口连接。
Python开发环境Jupyter Notebook
PYNQ中集成有Python开发环境,可以利用Jupyter Notebook进行开发。Jupyter是基于浏览器的互动式编程环境,能够实现代码编辑、程序结果实时显示和文本编辑。
启动步骤
将配置好的SD卡放入SK卡槽;
将①跳线帽连接到SD卡启动,②跳线帽连接到USB供电;
连接Micro USB和网线,USB线作为电源线和UART串口线,网线作为系统传输线;
将电源开关拨到ON位置;
现象:红色LED亮起表示板上有电源。几秒钟后,黄色/绿色LED亮起,表示板上设备正常运行。一分钟后两个蓝色LED和四个黄色/绿色 LED同时闪烁,之后蓝色LED关闭,而黄色/绿色发光二极管常亮,系统现已启动并可供使用。
打开web浏览器连接到Jupyter Notebook(http://192.168.2.99),登录账号密码为xilinx。
也可以在主机上访问,打开windows资源管理器,键入“ \\192.168.2.99\xilinx ”,登录账号密码为xilinx。
从底层向上走——熟悉ZYNQ开发
PS中运行程序,利用PL设计相应的模块加速程序算法,最后将编译的程序文件和FPGA配置文件封装成一个独立的、可以在Python开发环境中调用的Overlay。所以从最底层的ZYNQ开发起步,熟悉PS和PL设计流程,然后了解Overlay是怎么生成的,最后学习Python中如何调用底层文件来实现功能,才能对整个系统有一个整体的概念。
ZYNQ开发主要分为PS开发和PL开发,但是二者是相辅相成的,PL开发是为PS服务的,而少了PL部分,PS程序也无法实现。主要开发工具是Vivado,推荐教程为xilinx的Advanced-Embedded-System-Design-Flow-on-Zynq。
FPGA设计基础(《深入浅出玩转fpga》和《Xilinx FPGA设计权威指南》笔记与心得)
应用领域
逻辑粘合与实时控制
信号处理与协议实现
片上系统
开发流程
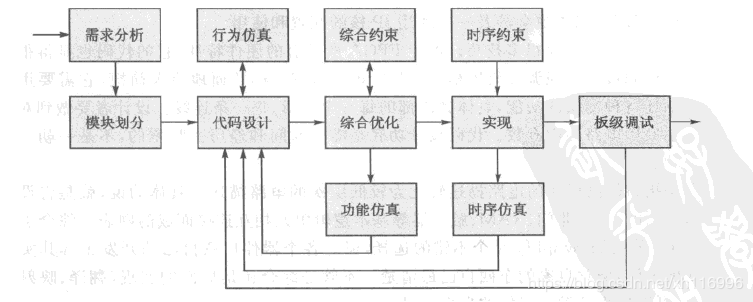
RTL行为级仿真:使用Verilog从行为级来模拟与FPGA接口的外围电路的时序,验证代码所实现的功能是否符合要求。仿真没有延迟信息,一般与器件无关。(绝大部分设计人员将这个阶段的仿真叫功能仿真!)
综合(Synthesis):将较高层次的电路描述转化为较低层次的电路描述。具体地说,就是将设计代码转化为底层的与门、非门、RAM、触发器等基本逻辑单元相互连接的网表。
综合后门级功能仿真(前仿真):利用综合后的Verilog网表进行仿真,需要在仿真过程中加入厂家的器件库。
时序约束:对工程进行全局约束,然后对I/O接口时序进行约束,在对需要的的地方做时序例外约束。
实现(Implementation):翻译、映射和布局,包括优化设计、功耗优化设计、布局设计、物理优化设计、布线设计和写比特流。
时序仿真(Post-Implementation Timing Simulation,后仿真):利用实现完的时序仿真模型和SDF时序标注文件(Standard Delay Format Timing Annotation)进行仿真。仿真带有延迟信息,可能出现时序问题
FPGA的仿真是通过给设计模型添加一个激励,模拟出实际FPGA运行状态输出响应,设计者观察波形进行判断。(不同仿真的区别参考教程)
板级调试:Vivado集成设计环境包含逻辑分析特性和串行I/O分析特性。包括三个阶段:
探测阶段(Probing phase):用于标识需要对设计中的哪个信号进行探测,以及探测的方法;
实现阶段(Implementation phase):实现设计,包括将额外的调试IP连接到被标识为探测的网络。
分析阶段(Analysis phase):通过与设计中的调试IP进行交互,调试和验证设计功能。
深入了解ZYNQ(《The Zynq Book》笔记与心得)
Zynq 的本质特征,是它组合了一个双核ARM Cortex-A9 处理器和一个传统的现场可编程门阵列(Field Programmable Gate Array,FPGA)逻辑部件。
在Zynq上,ARM Cortex-A9 是一个应用级的处理器,能运行完整的像Linux 这样的操作系统,而可编程逻辑是基于Xilinx 7 系列的FPGA 架构。这个架构实现了工业标准的AXI 接口,在芯片的两个部分之间实现了高带宽、低延迟的连接。

具体架构
处理器系统
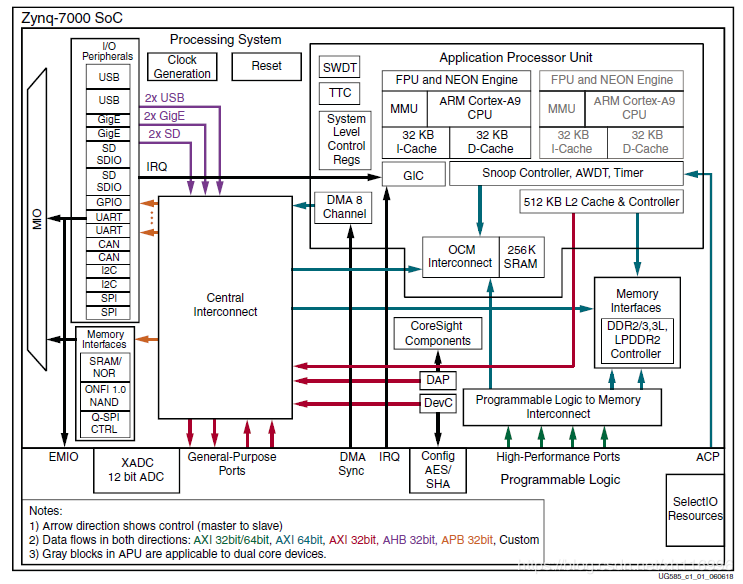
应用处理单元(APU, Application Processor Unit)
NEON:媒体处理引擎(Media Processing Engine,MPE),实现了单指令多数据(Single Instruction Multiple Data,SIMD)功能来实现媒体和DSP 类算法的战略加速。可以对输入向量中的多组数据,同时执行相同的运算来得到对应的输出向量。NEON 支持多种数据类型,但是不支持双精度的。
FPU:浮点运算单元(Floating Point Unit,FPU);
MMU:内存管理单元(Memory Management Unit),在虚拟地址和物理地址之间做翻译。
L1(D)、L1(I):一级cache存储器
SCU:一致性控制单元(Snoop Control Unit)。负责维持两个处理器的数据cache 存储器和共享的二级cache存储器之间的存储一致性;通过加速器一致端口(Accelerator Coherency Port,ACP)来管理在PS 和PL 之间的访问会话。
OCM:片上存储器(On Chip Memory)

处理器系统外部接口
MIO(Multiplexed Input/Output):提供54个灵活配置的引脚,包括SPI、I2C、CAN、UART、GPIO、SD、USB和GigE
EMIO(Extended MIO):通过共用了PL 的I/O 资源来实现的
可编程逻辑
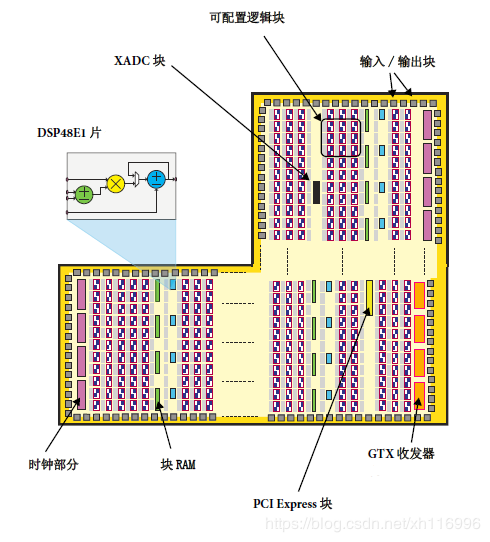
基于Artix-7和Kintex-7的FPGA组件。
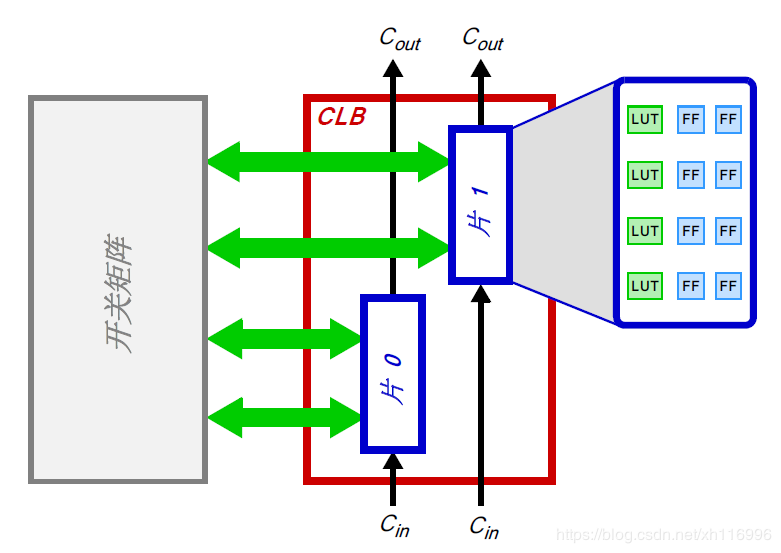
可配置逻辑块(CLB, Configurable Logic Block):由两个逻辑片和一个紧邻的开关矩阵组成。
片(Slice):有实现组合和时序逻辑电路的资源,由4个查找表、8个触发器和其他一些逻辑组成。
查找表(LUT, Lookup Table)
触发器(FF, Flip-flop):一个实现1 位寄存的时序电路,带有复位功能。
开关矩阵(Switch Matrix):连接CLB 内的单元,或把一个CLB 与PL 内的其他资源连接起来。
输入输出块(IOB, Input/Output Block),50个IOB一组,分为高性能(HP, High Performance)或高范围(HR, High Range)
DSP48E1:用于高速算数
块RAM:满足密集存储需要,最多存储36KB的信息
通信接口GTX收发器,包括一个PCI Express块
XADC:专用的模数转换器,由PS里的PS-XADC接口控制块实现。
时钟:PL 接收来自PS 的四个独立的时钟输入,另外还能产生和分发它自己的与PS 无关的时钟信号。
处理器系统与可编程逻辑的接口
AXI接口
ZYNQ中连接PS和PL两部分采用高度定制的AXI(Advanced eXtensible Interface)互联和接口。
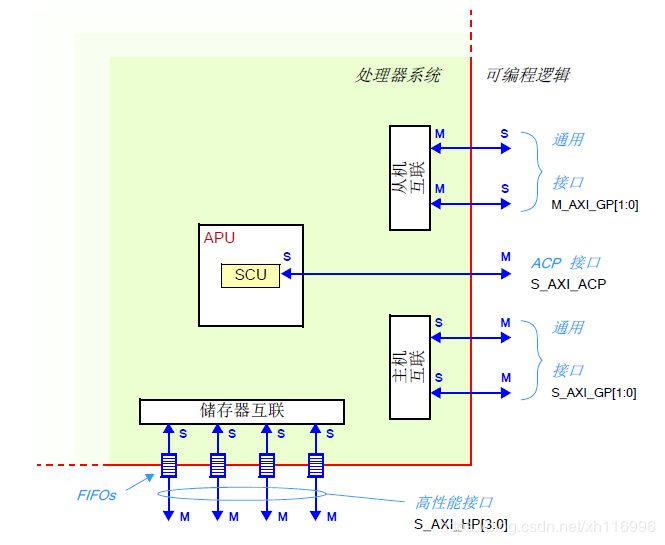
接口分为主机和从机,按照惯例,主机是控制总线并发起会话的,而从机是做响应的。
通用AXI(General Purpose AXI):32 位数据总线,适合PL 和PS 之间的中低速通信。总共有四个通用接口:两个PS 做主机,另两个PL 做主机。
加速器一致性端口(Accelerator Coherency Port):总线宽度为64 位,用来实现APU cache 和PL的单元之间的一致性。PL 是做主机的。
高性能端口(High Performance Ports):数据宽度是32 或64 位,带有FIFO缓冲来提供“ 批量” 读写操作,并支持PL 和PS 中的存储器单元的高速率通信。在所有四个接口中PL 都是做主机的。
EMIO接口
从PS 出来,有几种连接可以经由PL 到外部接口上,这被称作扩展的MIO(Extended MIO),即EMIO。
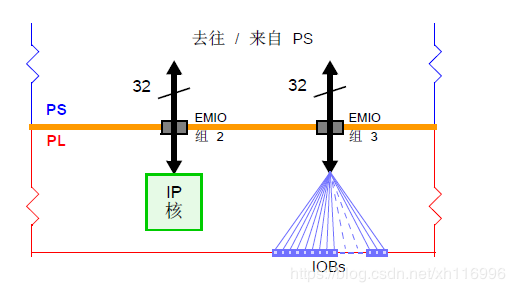
经EMIO 的接口直接连接到所需的PL 的外部引脚上的,由一个约束(描述)文件中的条目所指定的。在这个模式下,EMIO 可以实现额外的64 个输入线和64 个带有输出始能的输出线。
用EMIO 来连接PS 和PL 里的外设模块。
ZYNQ设计层次
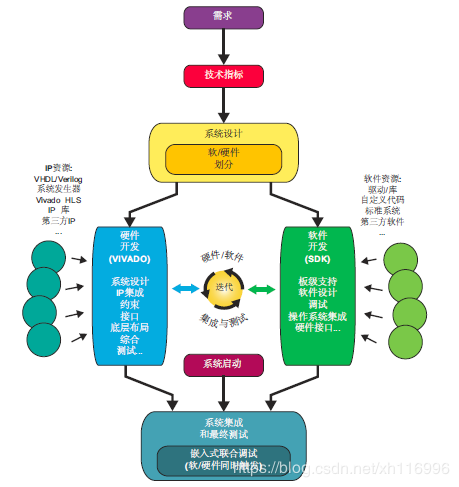
功能划分
软件(在PS 端)常常用来完成一些一般性的顺序执行的任务,比如操作系统、用户应用程序以及图形界面;PL端主要实现数据流计算的任务和具有并行限制的软件算法。
硬件开发和测试
Vivado IDE开发套件,IP库
配置PS
在PL上设计和实现外部模块和逻辑单元
软件开发和测试
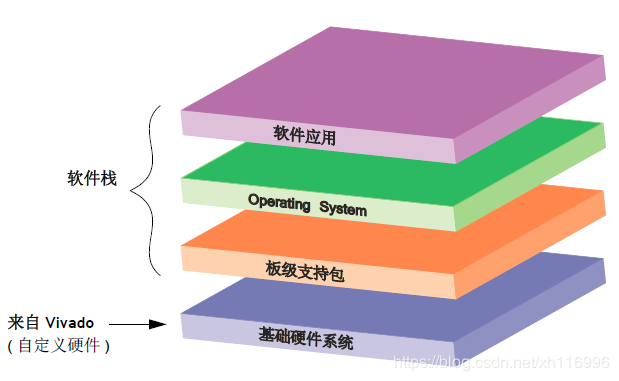
软件系统可以被认为是建立于基于硬件的系统上的一个栈。
板级支持包(BSP):提供底层的驱动和函数供下一层(操作系统)使用和硬件通信。BSP根据基础硬件系统进行调整。
操作系统
软件应用
系统集成和测试
利用软硬件交叉触发器进行嵌入式联合调试。这一过程将PL 上的ILA(Integrated Logic Analyzer)的硬件调试核心和Zynq PS 端的FTM(Fabric Trace Module)通过一对输入输出信号进行连接。
ZYNQ小实验(Advanced-Embedded-System-Design-Flow-on-Zynq)
准备工具
- 板级支持包下载地址
- Vivado 2018.2
lab1:搭建简单的嵌入式系统
本实验利用集成的IP核搭建了PYNQ板上leds、buttons和switches的外部接口,将生成的比特流导入到SDK中,使用c语言编写程序,控制板子上的leds、buttons和switches。
SDK方式和Jupyter notebook方式的区别:SDK方式是使用C或C++语言对ZYNQ进行开发,Juputer notebook是在PYNQ上利用python语言开发。
拓展1:在jupyter notebook中控制leds、buttons和switches
启动PYNQ,将vivado生成的比特流文件(.\lab1\lab1.runs\impl_1\design_1_wrapper.bit)和硬件描述文件(.\lab1\lab1.srcs\sources_1\bd\design_1\hw_handoff\design_1.hwh)拷贝至PYNQ的系统文件目录下,并将两个文件的名称改为lab1.bit和lab1.hwh。
在文件目录下启动一个python3的编译环境,输入并执行代码。
from pynq import Overlay
from pynq.lib.axigpio import *
ol = Overlay("lab1.bit")
ol.download()
print(ol.ip_dict.keys())
btn = ol.buttons
sw = ol.switches
led = ol.leds
btn.setdirection(AxiGPIO.Input)
sw.setdirection(AxiGPIO.Input)
led.setdirection(AxiGPIO.Output)
led.write(4, 0xf)
print("-- Press any of BTN0-BTN3 to see corresponding output on LEDs --\r\n")
print(("-- Set slide switches to 0x03 to exit the program --\r\n"))
while not sw.read(0) & 0xf == 0x3:
mask = btn.read(0) & 0xf
led.write(0, mask)
print("-- End of Program --\r\n")
拓展2:利用verilog制作gpio的ip核
lab2:使用VIO(virtual input/output)和ILA(integrated logic analyzer)调试硬件
本实验利用集成的VIO和ILA IP核在lab1实验的基础上搭建硬件调试平台。利用ILA(Integrated Logic Analyzer)来检测led输出信号;利用System ILA检测定制math IP的S_AXI接口;利用VIO模拟math ip的输入输出信号。
VIO的使用:可以在vivado硬件管理界面手动控制和观察VIO模块的输出和输入,用于测试已经在硬件中实现的ip核的功能。
ILA的使用:可以在vivado硬件管理界面设置触发条件,捕捉硬件端口或AXI接口的波形信号,同时也能在触发后暂停软件程序(主要用于debug中)。
lab3:使用块RAM扩展内存
本实验在硬件电路中例化了一个集成的BRAM IP核,在SDK开发环境中,程序默认跑在BRAM中。可以发现程序比跑在ddr中快了若干倍。
lab4:使用CDMA(AXI Central Direct Memory Access)直接访问内存
本实验在硬件电路中例化了一个CDMA模块,实现了从DDR到BRAM、从DDR到DDR和从BRAM到DDR搬运数据,测试了分别采用正常方式和CDMA模块的方式的快慢。结果表明在大数据的搬运中,采用DMA能够实现更快的搬运速度。
lab5:ZYNQ启动方式的配置
ZYNQ启动方式可以配置为SD卡启动、QSPI flash启动。
理解ZYNQ启动过程、FSBL
lab6:程序分析与性能优化
在SDK中可以对程序进行profile,分析程序中不同函数的运行次数和运行时间,对较长时间的软件功能函数可以考虑利用硬件实现。
高层次综合(HLS)
HLS大实验(High-Level-Synthesis-Flow-on-Zynq-using-Vivado-HLS)
lab1:Vivado HLS设计流程
本实验完整的描述了利用HLS生成IP核的步骤,包括C调试和仿真、C综合和C&RTL联合仿真。另外分析综合报告来了解硬件时延和逻辑资源消耗,分析仿真波形来验证程序功能。
lab2:性能优化设计
优化指令以#pragma语句的形式嵌入到源代码中。
TRIPCOUNT:为了帮助在综合时对循环延迟进行估计,Vivado HLS提供了一个TRIPCOUNT指令,该指令允许限制用户指定的变量的边界。
PIPELINE:PIPELINE指令必须应用于每个函数中最内层的循环——最内层的循环是非变量有界的循环,而外层的循环只会向内层循环提供数据。
DATAFLOW:当执行DATAFLOW优化,自动在函数之间插入内存缓冲区,以确保下一个函数完成之前就可以开始操作之前的函数。允许内存缓冲区包括乒乓缓冲区(默认,可以随机访问缓存数据)和FIFO。
lab3:内存和资源的优化设计
PIPELINE:当PIPELINE指令应用于外循环时,将自动导致内循环展开(unroll)并且并行处理(如果可以的话),导致资源利用率的增加。
Partition和RESHAPE:RESHAPE指令将允许对BRAM进行多次访问,但是,如果单个元素需要修改,则需要小心,因为它将导致对整个字节的读-修改-写操作。
INLINE:当INLINE指令应用于函数时,较低层的层次结构将自动分解并内联到上层函数。
DATAFLOW:只在顶级循环和函数上进行优化。
lab4:IP-XACT实例
以实际工程来训练上述实验中的要点,最后生成一个FIR滤波器的IP核并例化进工程,实现对输入音频的滤波作用。
————————————————
版权声明:本文为CSDN博主「xh116996」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xh116996/article/details/89218766





