作者:Stephen Evanczuk,Digi-Key 北美编辑
过去,设计人员倾向于使用现场可编程门阵列 (FPGA) 在硬件设计中提升计算密集型应用的性能,例如计算机视觉、通信、工业嵌入式系统,以及越来越多的物联网 (IoT)。然而,传统 FPGA 编程中涉及的繁琐步骤一直让人望而却步,促使设计人员到目前都还在寻求替代处理解决方案。
基于 Jupyter 笔记本的 Python Productivity for Zynq (PYNQ) 开发环境的问世,解决了 FPGA 的可编程性问题。使用专为支持 PYNQ 而设计的开发板,即使 FPGA 经验很少的开发人员也可快速实现相关设计,从而充分利用 FPGA 性能来加快计算密集型应用。
本文将说明典型的 FPGA 方法,然后介绍并演示如何开始使用 Digilent 的开发板。该开发板为快速开发基于 FPGA 的系统提供了一种强大的开源替代方法。
为何使用 FPGA?
若需要使用计算密集型复杂算法,工程师常常依赖 FPGA 提高执行速度,同时又不影响紧张的功率预算。实际上,FPGA 已成为在边缘计算系统中提高人工智能算法速度的主流平台。
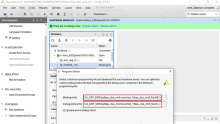
更先进的 FPGA 片上系统 (SoC) 器件专为嵌入式应用而设计,将可编程逻辑 (PL) 结构与微控制器集成在一起。例如,Xilinx 的 Zynq-7000 SoC 在集成式可编程逻辑 (PL) 结构中结合了一个 Arm® Cortex®-A9 双核处理器系统,以及最多 444,000 个逻辑单元(图 1)。除了内置处理器和全套外设外,Zynq SoC 还提供最多 2,020 个数字信号处理 (DSP) 块(或称切片)。开发人员使用这些资源,便可将 PL 结构配置到专用的处理链中,以便在复杂的计算密集型算法中提高吞吐量。
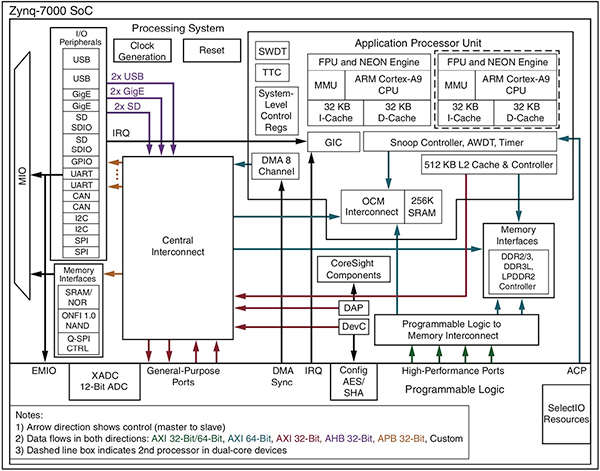
图 1:Xilinx 的 Zynq-7000 SoC 结合了 Arm Cortex-A9 双核处理器、可编程逻辑结构,以及很多嵌入式应用中所需的全套外设和接口。(图片来源:Xilinx)
除了可减少元器件数量外,处理器与 PL 结构的集成还允许通过片上总线而不是片外访问来执行运算。这种集成也进一步简化了在上电或复位序列期间,加载 PL 结构的关键任务。
在使用 FPGA 构建的基于微控制器的典型系统中,开发人员需要管理用于加载 FPGA 编程比特流的序列和安全性。在 Zynq SoC 中,集成的处理器负责执行常规微控制器的任务,包括管理 PL 结构和其他片上外设。因此,与传统的 FPGA 比特流初始化相比,该 FPGA 加载过程更接近于常规微控制器的引导过程。
该引导过程通过由其中一个 Zynq 处理器管理的短步骤序列完成(图 2)。上电或复位时,如果 Zynq 处理器执行其只读 BootROM 中的一小段代码,以从引导设备获取实际引导代码,则引导过程开始。除了用于配置处理器系统组件的代码外,引导代码还包含 PL 比特流以及用户应用。当引导代码加载完成时,处理器使用其中包含的比特流来配置 PL。而完成组件和 PL 的配置后,该器件开始执行引导代码中包含的应用。

图 2:在类似于常规微控制器的引导序列中,Xilinx 的 Zynq-7000 SoC 运行 Boot ROM 中的代码来加载和执行引导加载程序,该加载程序负责处理后续阶段,包括使用引导代码中封装的比特流来配置可编程逻辑结构。(图片来源:Xilinx)
即使有了简化的 PL 加载处理,开发人员在过去仍需自行处理复杂的 FPGA 开发过程,才能生成所需比特流。对于希望利用 FPGA 性能的开发人员来说,传统的 FGPA 开发过程仍然是他们实现设计的一大障碍。Xilinx 通过其 PYNQ 环境有效地消除了这一障碍。
PYNQ 环境
在 PYNQ 中,PL 比特流封装在预先构建的库中。这些库称为覆盖层,在开发过程和执行环境中,其角色与软件库类似。在引导加载过程中,与所需覆盖层相关联的比特流将配置 PL 结构。不过,对于通过与每个覆盖层关联的 Python 应用程序编程接口 (API) 来利用覆盖层功能的开发人员而言,该过程保持透明。在开发过程中,工程师可以根据需要组合软件库和覆盖层,通过其各自 API 来实现应用。在执行过程中,处理器系统像往常一样执行软件库代码,而 PL 结构负责实现覆盖层中提供的功能。这样做的结果是可以提升性能,从而进一步促使开发人员对日益严苛应用进行 FPGA 设计的兴趣。
顾名思义,PYNQ 利用了与 Python 编程语言相关的更高开发生产力。Python 之所以能够成为顶级语言之一,不仅是因为其相对简单,还因为它具有庞大且不断扩增的生态系统。开发人员可能会在 Python 开源模块的存储库中,找到支持服务或专用算法所需的软件库。与此同时,开发人员可以使用 C 语言实现关键功能,因为 PYNQ 使用常见 C 语言实现 Python 解释器。该实现允许轻松访问数千个现有 C 语言库,并简化开发人员提供的 C 语言库的使用。尽管经验丰富的开发人员可以使用专用硬件覆盖层和 C 语言软件库来扩展 PYNQ,但是 PYNQ 的真正优势在于,它可为任何能够构建 Python 程序的开发人员提供高生产力开发环境。
PYNQ 本身是一个开源项目,基于另一个开源项目(Jupyter 笔记本)而构建。针对通过交互方式探索算法,以及使用 Python 或任何其他受支持的编程语言(目前超过 40 种)对复杂应用进行原型开发,Jupyter 笔记本可提供极其有效的环境。Jupyter 笔记本由 Project Jupyter 基于社区共识而开发,将可执行代码行与描述文本和图形结合在一起。这一功能使各开发人员能够更有效地记录进展,而无需转到其他开发环境。例如,开发人员可以使用笔记本,将查看数据所需的数行代码与代码生成的图形结合起来(图 3)。

图 3:来自 Xilinx 样例存储库的 Jupyter 笔记本将描述文本、可执行代码以及与应用相关的输出结合起来。(图片来源:Xilinx)
Jupyter 笔记本之所以能够同时包含代码、输出和描述文本,是因为它是一种活动文档,并在 Jupyter 笔记本服务器提供的交互式开发环境中进行维护(图 4)。在 Jupyter 会话中,服务器使用 HTTP 协议在常规 Web 浏览器中呈现笔记本文件,并对所呈现文档中的静态和动态内容应用 HTTP 和 Websocket 协议。在后端,服务器使用 ZeroMQ (ØMQ) 开源消息传递协议与代码执行内核通信。
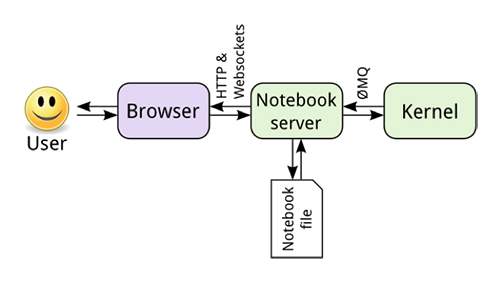
图 4:在 Jupyter 会话中,笔记本服务器将笔记本文件的内容呈现到 Web 浏览器,同时与执行代码的后端内核进行交互。(图片来源:Project Jupyter)
在编辑模式下,用户可以修改文本和代码。然后,服务器会更新相应的笔记本文件 — 一种包含一系列 JSON 键/值对的文本文件。在 Jupyter 环境中,这些键/值对称为单元。例如,上述 Jupyter 笔记本的 Web 浏览器显示内容包含一些码元和 Markdown 文本(清单 1)。
{ "cell_type": "markdown", "metadata": {}, "source": [ "## Error plot with Matplotlib\n", "This example shows plots in notebook (rather than in separate window)."] }, { "cell_type": "code", "execution_count": null, "metadata": { "scrolled": true }, "outputs": [ { "data": { "image/png": "iVBORw0KGgoAAAA[truncated]", "text/plain": [ "
清单 1:Jupyter 笔记本是一种包含一系列 JSON 键/值对的文本文件,这些键/值对则包含代码段、标记和输出,对应于图 3 所示的呈现页面。请注意,为便于显示,在这里截断了与该图中的 .png 图像对应的字符串。(代码来源:Xilinx)
除了具备文档特性之外,Jupyter 环境的强大之处还在于,它能够交互地执行码元。开发人员只需在浏览器中选择相关单元(图 3 中的蓝色边框),然后在浏览器窗口顶部的 Jupyter 菜单中单击运行按钮即可。然后,Jupyter 笔记本服务器将相应的码元传递给代码执行内核 — 在 PYNQ 环境中是交互式 Python (IPython) 内核。代码执行完成后,服务器将根据该内核生成的任何输出,来异步更新呈现的网页和笔记本文件。
通过在 Zynq SoC 的 Arm 处理器上嵌入 Jupyter 框架(包括 IPython 内核和笔记本 Web 服务器),PYNQ 将这种方法扩展到基于 FPGA 的开发。该环境中包含的 PYNQ Python 模块为程序员提供了所需 Python API,以便访问 Python 程序中的 PYNQ 服务。
FPGA 开发环境
Digilent 的 PYNQ-Z1 开发套件专为支持 PYNQ 而设计,使开发人员只需通过加载可用的 PYNQ 可引导 Linux 映像,即可快速开始探索 FPGA 加速型应用。PYNQ-Z1 开发板结合了 Xilinx 的 XC7Z020 Zynq SoC 与 512 MB RAM、16 MB 闪存,以及用于添加外部闪存的 microSD 插槽。除了开关、按钮、LED 和多个输入/输出端口外,该开发板还配备连接器,用以通过 Digilent Pmod(外设模块)接口和 Arduino 的 盾板以及 Digilent 的 chipKIT 盾板来连接第三方硬件,从而扩展功能。PYNQ-Z1 开发板还提供 Zynq SoC 的模数转换器 (ADC)(称为 XADC),作为六个单端模拟输入端口或四个差分模拟输入端口。Digilent 也提供单独的 PYNQ-Z1 生产力套件,其中包含电源、微型 USB 电缆、预装有 PYNQ 映像的 microSD 卡,以及用于更新或添加 Python 模块的以太网电缆。
对于开发人员来说,SoC 和 PYNQ-Z1 开发板的全部功能都可以通过 Jupyter 笔记本提供。例如,在回送测试中,要访问该开发板的 Pmod 接口,以读取数模转换器 (DAC) 的数值,只需编写几行代码即可(图 5)。在导入所需的 Python 模块后,SoC PL 将使用“base”覆盖层进行初始化(图 5 中的第 2 个单元)。与常规的板级支持包类似,此 base 覆盖层也提供了对开发板外设的访问。
图 5:Xilinx 样例存储库中包含的 Jupyter 笔记本,演示了有关访问硬件服务以执行输入/输出事务的简单设计模式。(图片来源:Xilinx)
开发人员只需调用导入的模块,即可读写数值(图中的第 3 个单元)。在显示的样例笔记本中,笔记本服务器按顺序发出每个单元,并基于生成的结果更新笔记本。在本例中,0.3418 是唯一的输出值,但是任何执行错误都将以一般的 Python 回溯堆栈显示出来,并与这些堆栈各自的码元保持一致。
构建复杂应用
这种嵌入式应用开发方法虽然看似简单,但它与各种可用的 Python 模块相结合,实际上是一种能够快速实现计算密集型复杂应用的强大平台。例如,开发人员可以使用 PYNQ-Z1 HDMI 输入和流行的 OpenCV 计算机视觉库,快速实现人脸检测网络摄像头。在加载 base 覆盖层和网络摄像头接口后,开发人员需要初始化 OpenCV 摄像头对象 videoIn(图 6)。这样,要读取视频图像,只需简单地调用 videoIn.read() 即可,在本例中将返回 frame_vga。
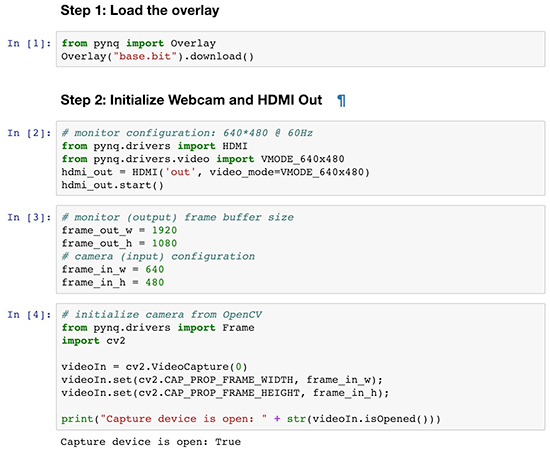
图 6:Xilinx 样例存储库中提供的 Jupyter 笔记本,显示了开发人员可如何通过将 PYNQ-Z1 开发板的硬件资源与 OpenCV 库 (cv2) 中的强大图像处理功能相结合,快速构建网络摄像头人脸识别系统。(图片来源:Xilinx)
在后续步骤中,开发人员在笔记本的一个单独单元中,使用预设条件创建 OpenCV (cv2) 分类器对象,并添加边框用于识别特征(在本例中绿色框用于识别眼睛,蓝色框用于识别面部)。在另一对单元中,在使用开发板的 HDMI 输出显示输出后,该应用即完成构建(图 7)。
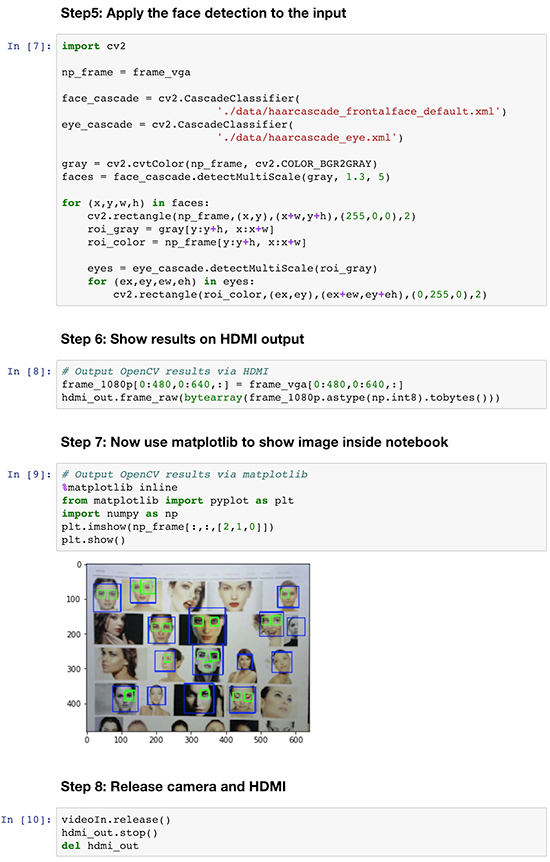
图 7:Xilinx 网络摄像头人脸检测笔记本中的最后几个单元演示了 OpenCV 分类器的使用,分类器的结果用于向原始图像添加边框,并通过 PYNQ-Z1 开发板的 HDMI 输出端口显示出来。(图片来源:Xilinx)
Jupyter 笔记本能够以交互方式构建和测试复杂软件并分享关于复杂软件的讨论,因此深受致力于为人工智能应用优化算法的科学家和工程师的青睐。随着工作的进展,笔记本不仅能显示代码及其输出,还可显示开发人员对结果的分析,从而提供了一种计算叙事,可以在团队成员和同事之间分享。
然而,开发人员必须清楚,笔记本不太可能成为生产型开发过程的存储库。例如,笔记本包含用于图像数据的较长十六进制编码字符串(参见清单 1 中的截断部分),这不仅会增加文档的大小,而且会使典型的源代码版本控制系统使用的各种方法变得复杂。代码与非功能文本的交织,可能会导致将初期分析阶段中创建的代码迁移到生产级开发过程的工作变得更加复杂。但是,对于代码探索和快速原型开发,Jupyter 笔记本提供了强大的开发环境。
总结
物联网、计算机视觉、工业自动化和汽车等诸多应用对嵌入式系统设计的需求日益增长,而 FPGA 可实现必要的性能提升,从而满足这些需求。虽然传统的 FPGA 开发方法对于许多开发人员来说仍然是个难题,但是基于 Python 和 Jupyter 笔记本的 PYNQ 开发环境的出现,为他们提供了一种有效的替代方案。使用专为支持 PYNQ 而设计的开发板,即使 FPGA 经验很少的开发人员也可快速实现相关设计,从而充分利用 FPGA 性能来加快计算密集型应用。