作者:安平博,Xilinx高级工程师;来源:AI加速微信公众号
AIX(artificial intelligence aXellerator)是韩国SK公司为语音识别提供的一个解决方案,应用于微软的开源语音识别框架Kaldi。AIX使用了Xilinx的FPGA平台,充分利用了FPGA能提供的外存访问带宽和DSP资源。在自动语言识别(ASR)中,在性能和功耗上超过了分别超过了最领先的CPU 10.2倍和流行的GPU20.1倍。
1. 硬件平台和算法介绍
AIX使用了Xilinx Kintex Ultrascale KCU1500板卡,板卡包括一个KU115芯片,4块4GB DDR4-2400的DRAM,每块芯片有64个DQ引脚。最大可以支持76.8GB/s的带宽。KU115芯片资源如下:
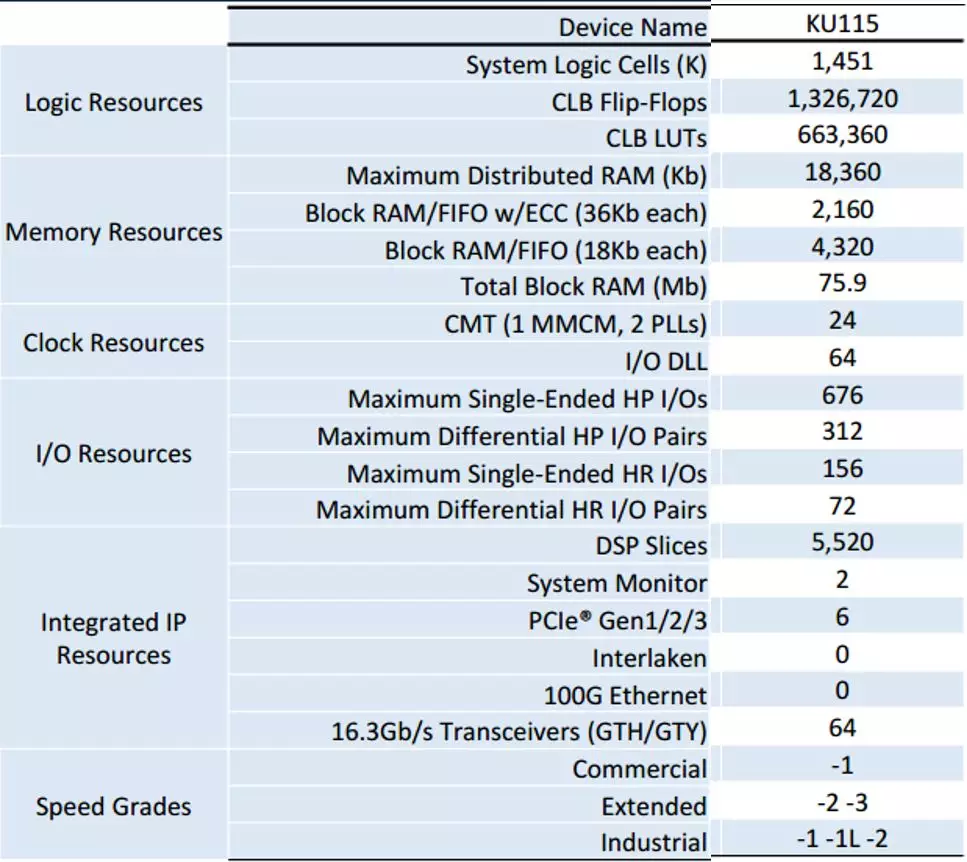
图1.1 KU115资源
Kaldi是一个基于C++编写的用于语音识别的开源工具,它依赖于两个外部工具库:一个是openFst,另外一个是线性计算,包括矩阵乘法,以及矩阵和向量的操作。openFst基于有限状态转换器算法,可以用于语音和语言识别中。所以在ASR中包含了大量的矩阵乘法运算。AIX主要的目的就是加速这些矩阵乘法运算。
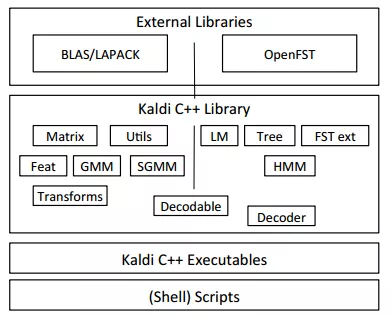
图1.2 Kaldi库
一个基本的语音识别算法过程如下:首先采集人的语音信号,将语音信号分割成一段段向量,每个向量会有一些重叠。将每段语音信号经过FFT等操作,转换为MFCC或者倒谱,实际上就是做了一些向量的转换操作。MFCC或者倒谱的表达能更好的提取语音特征。在论文中每个向量长度为120。为了能够表现不同向量之间的关系,将每个Ci向量最近邻的2n个向量组合为一个整体,然后送到MLP进行运算。通过MLP提取特征,在进行HMM操作进行分类处理。AIX就是加速MLP这部分操作,因为这部分占据了整个算法的大部分运算,涉及到大量矩阵运算。
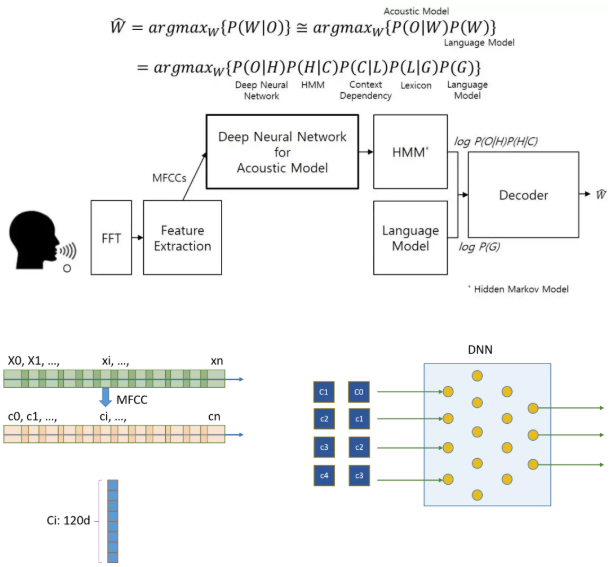
图1.3 ASR算法过程
2. DNN硬件架构
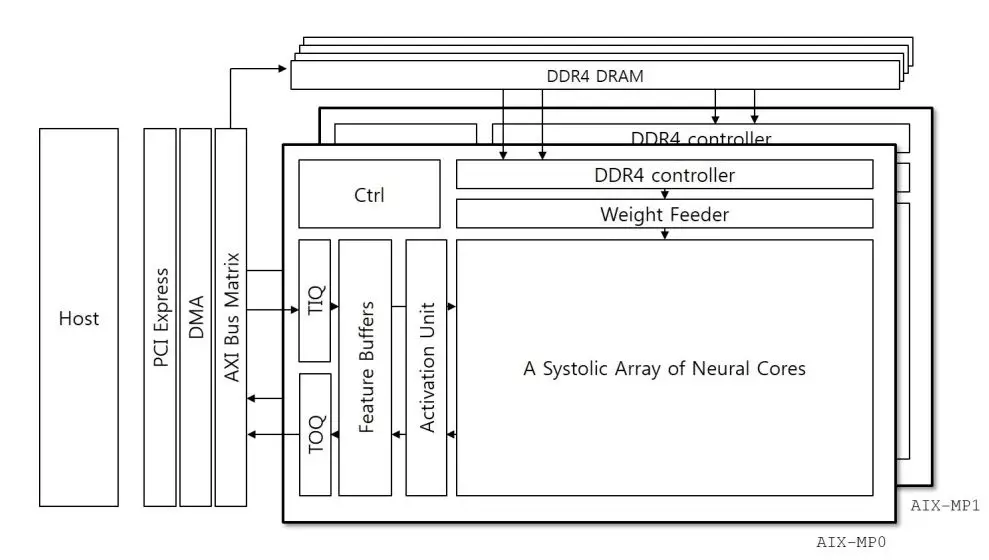
图2.1 AIX硬件架构
在KU115上,AIX由两个核组成,每个核的结构是一样的。这两个核分别分布在芯片的两个die上。每个核使用两个DDR4,每个提供38.4GB/s的带宽。核心计算单元是脉动阵列结构,大小为64x40,总共使用了2560个DSP。语音向量从脉动阵列左侧进入,权重数据从上边脉动进入,然后在每个DSP进行乘法,每个DSP还进行累加。最后可以输出一个64X40大小的矩阵。因此进入的语音向量,每次在缓存中获得了40个120的语音向量后,进行转置操作,得到120X40的向量组合,然后脉动送入阵列。完成矩阵乘法。这种算法在之前的文章《在DNN中FPGA都做了什么?》有详细描述。这对语音向量的带宽要求是一个FPGA时钟周期40x16bit,权重为64x16bit。64的选择可以适配DDR的带宽38.4GB/s。这样既充分利用了DSP资源,也更好的利用了DDR带宽。这种方案适合处理矩阵乘矩阵,但是对于矩阵乘向量的DSP利用率就会很低了。因为权重的IO带宽较低。
图2.2 矩阵x矩阵计算阵列
这个板卡是通过PCIE和主机连接,主机完成DNN之外的HMM,decoder等操作。开始主机通过PCIE将一定量的权重存储到板卡的DDR中,然后AIX主动去获取权重数据。权重数据是不断被复用的,因此初始时刻被加载到DDR中以后,就不需要再加载权重了。除非权重很多超过了DDR的存储空间。主要更新的是语音向量,需要通过PCIE不断下载到片上。当片上向量队列存储了40个后,就可以进行转置送到脉动阵列进行运算。
对于网络中的其他操作,比如sigmoid,tangent,leakyRelu等,都是通过查找表完成的。查找表的方式可以更灵活的用于这些杂七杂八的运算。这些运算数学公式复杂,直接计算会耗费很多逻辑,不如查找表简洁。缺点就是需要较大的存储空间,空间是和数据精度有关的,精度越高消耗存储空间越大。
3. 软件架构
为了能够将AIX更好的融入到基于Kaldi的ASR计算中,需要很好的和数据中心的软件端进行匹配。因此提出三种软件模型来解决这个问题。
一个模型用于对AIX的配置,即在AIX计算前,需要准备好权重和偏置数据。这种准备工作是由NN converter软件来做的,主要就是判定一个网络中哪些层可以被AIX加速,然后将这部分权重发送给AIX。
另外一个是监测模型。为了保证AIX的稳定运行,需要进行大量的边缘条件测试,因此监测软件来检测一些异常情况。主要包括:功耗,温度,资源利用,设备状态。
最后一个是用于处理语音向量的软件。为了保证实时处理语音数据,每8个语音向量组成一个batch,然后一起写入AIX。为了提高脉动阵列的利用效率,语音缓存尽可能收集更多向量,然后开始计算。为了减小收集时间,软件端提供了多个服务通道,同时准备语音向量,并向AIX发送或者接收来自AIX的结果。由于处理不同语音向量是有顺序的,为了保证结果也能够保持顺序不变。每个通道增加了锁机制来保持向量的发送和接收顺序。当需要向AIX写的时候,就产生一个有wlock的写进程,直到wlock被解锁,这个进程才开始往AIX发送数据。同理读进程也有一个rlock。这些锁会保证进程间的依赖和同步。

图3.1 软件架构
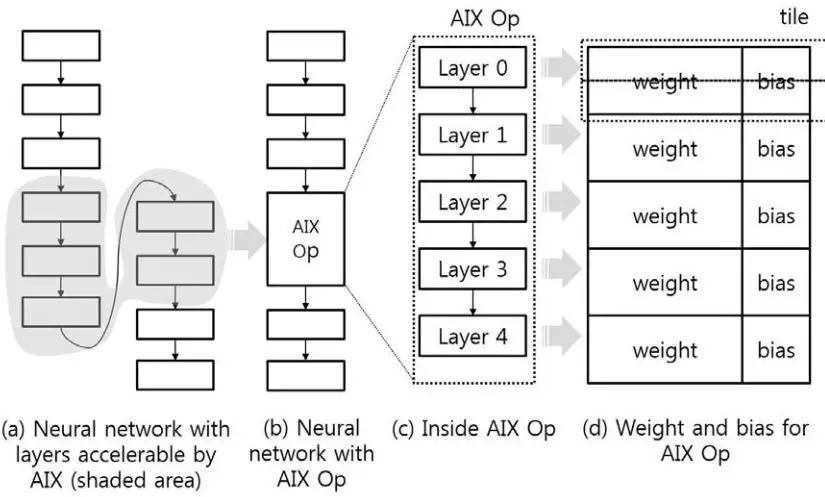
图3.2 NN converter的作用
4. 结果
现在看资源利用率:

图4.1 资源利用率
AIX的性能和Intel的E5-2620和Nvidia的P100 GPU进行了对比。同时考虑上功耗和语音识别时间,AIX都超过了CPU和GPU。

图4.2 AIX和CPU以及GPU的性能对比
总结
AIX采用了脉动阵列的架构,充分利用了矩阵乘法中数据的复用率。能够最大限度利用内存带宽来获得最大性能。
文献
1. Minwook Ahn, S.J.H., Wonsub Kim, Seungrok Jung, Yeonbok Lee, Mookyoung Chung, Woohyung Lim, Youngjoon Kim, AIX A high performance and energy efficient inference accelerator on FPGA for a DNN-based commercial speech recognition. FPGA, 2019.
文章转载自:AI加速





