作者:姚颂,来源:Xilinx学术合作
本文是关于Hot Chips 31大会观察与思考的系列文章的第二部分。整个系列将介绍我在Hot Chips大会上的几点观察与思考,涵盖以下几点内容:
今天将重点介绍中间两个话题,异构与安全。文章也将介绍一些Hot Chips会议上发生的趣事。如没有特殊说明,图片均来自于本人在Hot Chips 31拍摄的照片,PPT版权由原报告人所有。

No.1:异构计算:大势所趋
异构计算, Heterogeneous Computing, 不是一个新鲜的话题,然而真正出现大量使用的异构计算平台,却是从近几年的事情了。异构最重要的涵义,是系统有多种不同功能的部分组成,让每个部分做它最擅长的事情,而不是用统一的平台来做所有的事情。

异构计算的兴起,与AI芯片的兴起,本质上都有一个核心原因,摩尔定律的放缓甚至结束(摩尔定律的话题也是一个稍有争议的话题,在Philip Wong教授的Keynote中,他认为摩尔定律“well live”,这一点我们在下个部分中再讨论)。在过去几十年,芯片性能的增长,过半是由于制造工艺的进步带来的。在上图AMD CEO Lisa Su的报告中,也可以看到对于GPU,过去十年性能进步最重要的因素,也还是制造工艺的进步,占到了40%。而随着摩尔定律的放缓,由制造工艺带来的进步越来越小,我们必须更多地依赖微架构(也即图中占比17%的Microarchitecture部分)和系统层面的进步来实现整体的进步。而这其中,最直接的方式,就是设计Domain-specific architecture(DSA),放弃一部分通用性,来获得更大的性能提升。通常而言,越专用,通用性越差,越容易取得更好的性能。
也正因为此,我们看到了GPU在图像渲染上碾压CPU,我们看到了在不同通用性层次支持深度学习的各类DPU/NPU/NNP/MLU/
DLA/VPU。比如,我们可以选择支持各类机器学习算法、而不仅仅是深度学习的MLU,也可以选择只支持深度学习推理的DPU,而如今又出现了不少专注在深度学习训练的专用芯片。

(在2017年3月GTIC会议报告的PPT截图)
2018年3月份在智东西组织的GTIC大会上,我曾经讲过一个和nVidia VP of BD,Jeff Herbst的小故事。在2017年Hot Chips期间,我约着去拜访了Jeff,也一起吃了个晚餐。在聊到对于AI芯片未来产品时候,我说“I bet that you will sell a chip with no GPU in two years”,我打赌英伟达会在两年内卖一颗没有GPU的芯片。但是没想到其实英伟达的新产品来得如此之快:在2018年2月的CES,英伟达CEO黄仁勋就公布了面向自动驾驶的Drive Xavier芯片,号称30T算力,30W功耗。但是当我们认真的看PPT上的数字时候会发现,这30T算力,有10TOPS INT8来自于DLA,有20TOPS来自于Tensor Core,都不是传统的GPU。GPU部分只有512个CUDA core,只有1.3 CUDA TFLOPS。也就是说,这个GPU的算力几乎可以忽略不计,可能只是用来做大屏幕显示的。在我和Jeff见面仅仅半年之后,远没有到两年,nVidia就已经开始推出几乎没有GPU的芯片了,而似乎许多人没有注意到——这也充分说明了软件接口的重要性,当nVidia把所有的都做成兼容CUDA,再加上上层的Library和各类Framework进行封装,大家已经关注不到底层的改变了。

(Hot Chips 31现场nVidia的报告)
在这次Hot Chips大会上介绍的Turing GPU,虽然还挂着GPU的名字,其实也已经是一颗异构计算芯片,不仅仅是传统那些SIMD单元,总共由Turing SM, RT Core,与Tensor Core三个部分组成。报告人John Burgess介绍,传统做光线追踪,对于每一条光线,要反复花费数千个时钟周期,才能正确计算和物体的交界点在哪里,而一次渲染会有非常多条光线要计算,因此他们才想要设计RT Core来专门解决光线追踪的问题。这就是典型的异构与DSA解决问题的方式:为一个计算复杂的任务设计专用加速器,用异构的系统来做整体的计算。

(Hot Chips 31现场Xilinx的报告)
而异构计算一个特别极致的案例就是Xilinx本次介绍的Versal,Xilinx的第一款ACAP产品。Versal上同时有两个arm A72核,两个arm R5核,可编程逻辑也即FPGA,还有AI Engine与DSP Engine!这样一颗芯片,可以将应用做非常细致的拆分,AI部分在AI Engine上,信号处理部分在DSP Engine上,主控和通用计算部分在两个不同的CPU,其他需要加速但不能很好利用AI Engine与DSP Engine的部分在中间的可编程逻辑上。这种感觉就很“分而治之”,又很像经济学上的“价格歧视”——同样的产品,为不同购买力的人群分别制订他们能接受的最高价格,整体获得的收益会更大。在这里,我们是,同样一颗芯片,但是为不同应用分别划出专用的一块区域,去实现最好的性能。
毫无疑问,越来越异构化的芯片会是大势所趋。但是,实际上,背后依然有非常多的问题,比如,系统与应用层面的考虑,比如,软件编程的问题。当DSA越来越专用,必须去考虑整个芯片是否合适于使用的应用,必须有更多和行业结合的软件,而不仅仅只是像原来一样提供一个通用的平台而已。而复杂异构系统的编程开发,在业界依旧是一个没有完全解决好的问题。对于这样一颗异构芯片,我怎么去找到每个部分是否适合某个任务,是手动地划分任务、为不同部分单独编程再拼到一起,还是统一的软件界面去编程、之后自动映射?还有很多问题需要去解决。
No.2:安全,是一个越来越重要的话题
在2018年初,CPU行业曝出了两个巨大的安全漏洞,“Spectre”和“Meltdown”,其核心原因是因为为了追求更好的性能,CPU做了很多的优化工作,比如分支跳转预测,和乱序执行,而不是顺序的一条一条执行指令,执行到了再去内存里读取数据。而近几年也有一个很大的趋势,就是原来仅仅用在支付等场景的https协议,开始被越来越多的使用,大部分主流网站,比如常用的百度,微博,等等,已经全站都是https化了。哪怕我不是一个安全方面的专家,但是我也能感受到,各方面的因素,让“安全”这两个词变得越来越重要:我们希望在云计算上运行的任务是安全的,我们希望存储在云端的数据是安全,我们希望与服务器的通信是安全的。
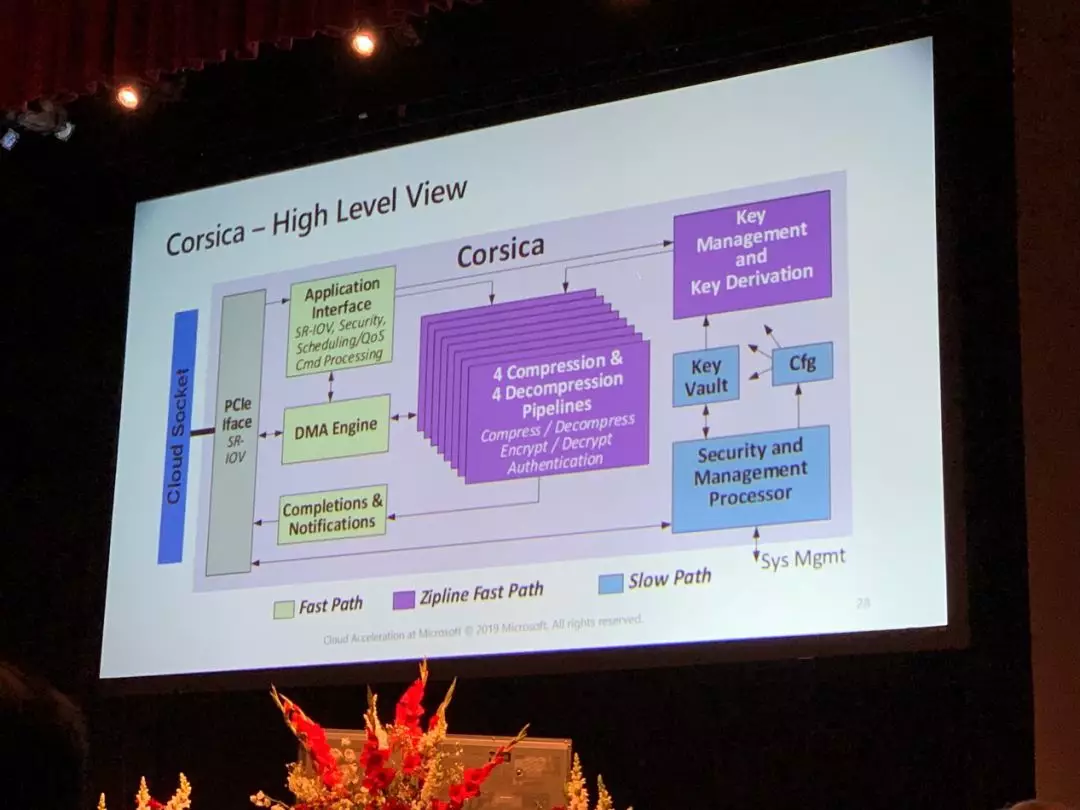
(Hot Chips 31 Tutorial 来自微软Azure团队的报告)

(Hot Chips 31 Tutorial 来自AWS团队的报告)
在本次Hot Chips大会,我们明显也看出了各家互联网公司与芯片公司对于安全的重视,并且把加密变成了产品流程中的重要一环。如上两图,在微软的tutorial中,微软介绍了自己正在开发了Corsica芯片,将文件的压缩解压缩与加解密做到了一起。AWS的Nitro项目中,也开发了自己的安全芯片。而在Intel的Optane项目中,加解密也已经融合到了存储一体。
可以想象,未来的存储一定是和加解密融合到一体的。我们也可以猜想,平头哥是不是也会做阿里自己的安全芯片?
No.3:两个彩蛋
在Hot Chips会场拍摄的两张照片,总计将四位大咖拍摄进去了,大家都认出来了吗?


(未完待续)
文章转载自:Xilinx学术合作