密集型计算正使用于有多个深度学习工作负载的数据中心。为了平衡计算效率、性能和总体拥有成本(TCO),使用具有可重配置逻辑资源的现场可编程门阵列(FPGA)提供可接受的加速能力,并与云中的各种计算敏感任务兼容。在本文中,我们开发了一个 FPGA 加速平台,该平台利用统一的framework架构,在数据中心实现通用卷积神经网络(CNN)推断加速。为了克服计算限制,4,096个DSP阵列用于不同类型卷积的超级单元(supertile units, SU),其在500MHz下提供高达4.2 TOP/s 16位定点性能。本文提出使用交织任务调度方法在SU间映射计算,并且通过调度 - 组装缓冲模型和广播高速缓存来解决存储器限制。对于各种非卷积运算符,设计滤波处理单元用于通用filter-like/pointwise运算。在实验中,我们比较了在服务器级CPU、GPU和 FPGA 上运行的 CNN 模型性能。结果表明,我们的设计实现了最佳 FPGA 峰值性能和与数据中心最先进 GPU 同级别的吞吐量,延迟降低了 50 倍以上。
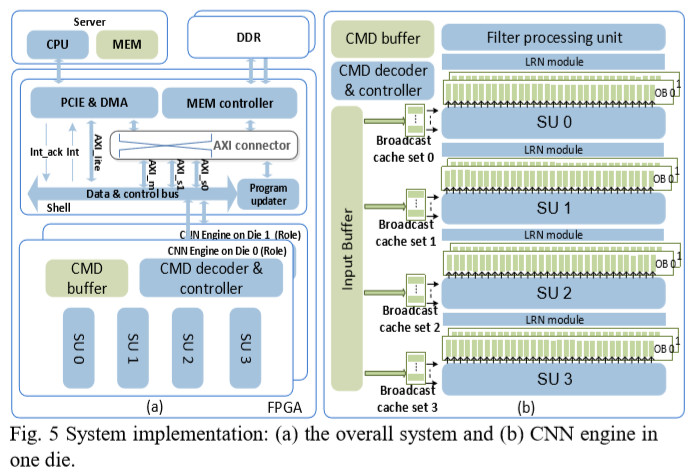
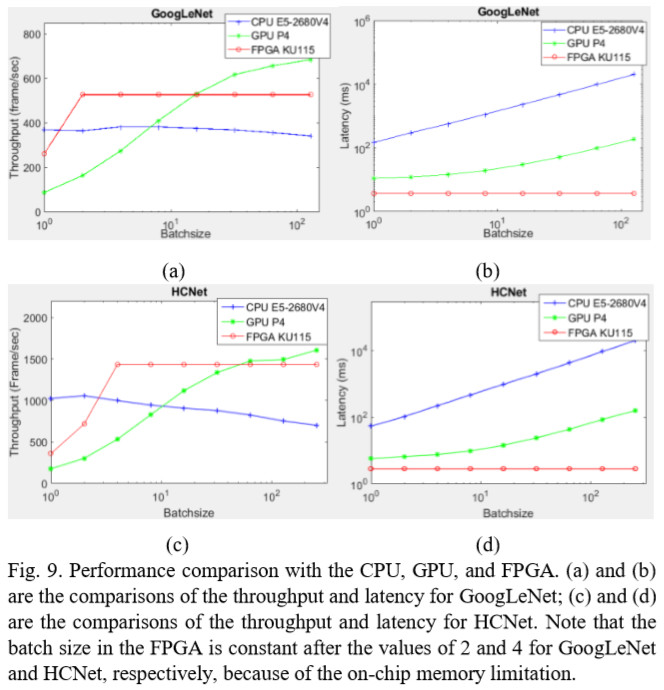
关于supertile技术,大家可以参考paper原文引用文章中的第22篇“A high-throughput reconfigurable processing array for neural networks”
来源:Xilinx学术合作