原创: AI加速
引言
硬件描述语言(verilog,systemVerilog,VHDL等)不同于软件语言(C,C++等)的一点就是,代码对应于硬件实现,不同的代码风格影响硬件的实现效果。好的代码风格能让硬件“跑得更快”,而一个坏的代码风格则给后续时序收敛造成很大负担。你可能要花费很长时间去优化时序,保证时序收敛。拆解你的代码,添加寄存器,修改走线,最后让你原来的代码“遍体鳞伤”。这一篇基于赛灵思的器件来介绍一下如何在开始码代码的时候就考虑时序收敛的问题,写出一手良好的代码。
1. Counter结构
计数器是在FPGA设计中经常要用到的结构,比如在AXI总线中对接收数据量的计算,用计数器来产生地址和last等信号。在计数器中需要用到进位链,进位链是影响时序的主要因素。如果进位链越长,那么组合逻辑的级数就越高,组合逻辑延迟越大,能够支持的最大时钟频率就会越低。在一个CLB中通常会含有一个进位链结构,比如在ultrascale中是CARRY8,在zynq7系列中是CARRY4,CARRY4可以实现4bit进位。如果是一个48bit计数器就需要12个这样的进位结构。一个CARRY4输出有两种CO和O,CO是进位bit,用于级联到下一级的CARRY4的CI,O是结果输出。因此我们可以看到在计数器中最下的进位结构是CARRY4,如果直接让多个进位结构级联,那么组合逻辑就会变大,时序延迟就会增大。如果可以将计数器拆分成小的计数器,那么时序就可以得到改善。
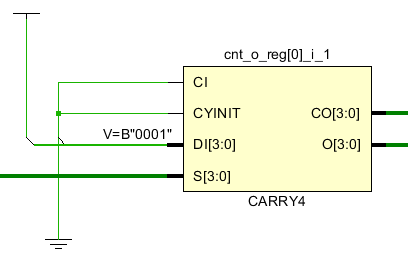
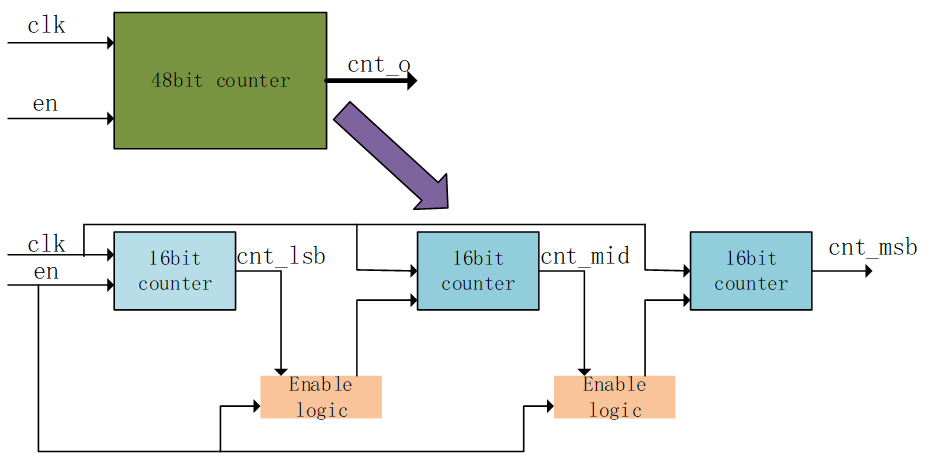
比如一个48bit计数器拆分成3个16bit计数器,那么CARRY4的级联级别就从原来的12个降低到4个。每4个之间增加了FF来进行时序改善。
always @(posedge clk)begin
if(rst)
cnt_o <= 0;
else
cnt_o <= cnt_o + 1;
end 拆分后代码为:
genvar i;
generate
for(i=0;i<3;i=i+1)begin: CNT_LOOP
wire trigger_nxt, trigger_pre;
if(i == 0)begin
always @(posedge clk)begin
if(rst)
cnt_o[i*16 +: 16] <= 0;
else
cnt_o[i*16 +: 16] <= cnt_o[i*16 +: 16] + 1;
end
assign trigger_nxt = (cnt_o[i*16 +: 16] == 16'hFFFF) ? 1 : 0;
end//if
else begin
assign trigger_pre = CNT_LOOP[i-1].trigger_nxt;
always @(posedge clk)begin
if(rst)
cnt_o[i*16 +: 16] <= 0;
else if(trigger_pre)
cnt_o[i*16 +: 16] <= cnt_o[i*16 +: 16] + 1;
end
assign trigger_nxt = CNT_LOOP[i-1].trigger_nxt && (cnt_o[i*16 +: 16] == 16'hFFFF);
end//else
end//for
endgenerate综合后我们就可以看到它的schematic每4个CARRY4都被FF隔开了,可以降低逻辑延时。但是代价是增加了LUT的数量,这些LUT是用来判断前一个16bit计数器的数值的,从而驱动后边16bit寄存器计数。
2. 逻辑拆分
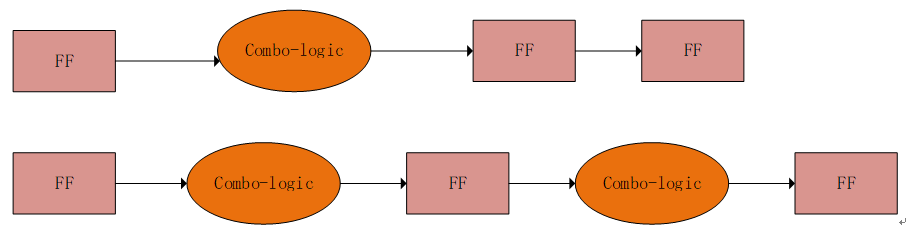
在上一节中拆解计数器本质上就是在拆分组合逻辑。当一个组合逻辑过大的时候,延时较大。将其拆解成两个或者两个以上逻辑,中间增加寄存器可以来提高能跑得时钟频率。比如下图有一个较大的组合逻辑,前边有一个FF,后边连续接2个FF。组合逻辑的延时就成为了整体时钟频率的一个关键路径。如果我们可以将其拆分成两个,中间用一级寄存器连接,这样总共的时钟周期还是3个,但是时钟频率明显会好于前一种。
3. 改善扇出
扇出是指某个信号驱动的信号的数量。驱动的信号越多,那么要求其产生的电流越大。学过数字电路就会知道,当一个信号输出连接的越多的时候,其输出负载就会越小,那么输出电压就会减小。所以如果信号扇出过大就会影响到高低电平,最终就会导致时序不收敛。另外一个原因是如果信号扇出过大,那么由于FPGA上走线路径的差异,就可能造成这个信号到达不同地址的延迟不同,造成时序不同步。一种解决办法是复制,将扇出较大的信号复制几份,这样就可以减小扇出。比如一个输入d_i需要和3个数进行求和。那么这个信号扇出就是3.如果将其复制3份,给每个数输送一份,那么扇出就变为1。
always @(posedge clk)begin
data1_o <= data_i + data1_o;
data2_o <= data_i + data2_o;
data3_o <= data_i + data3_o;
end
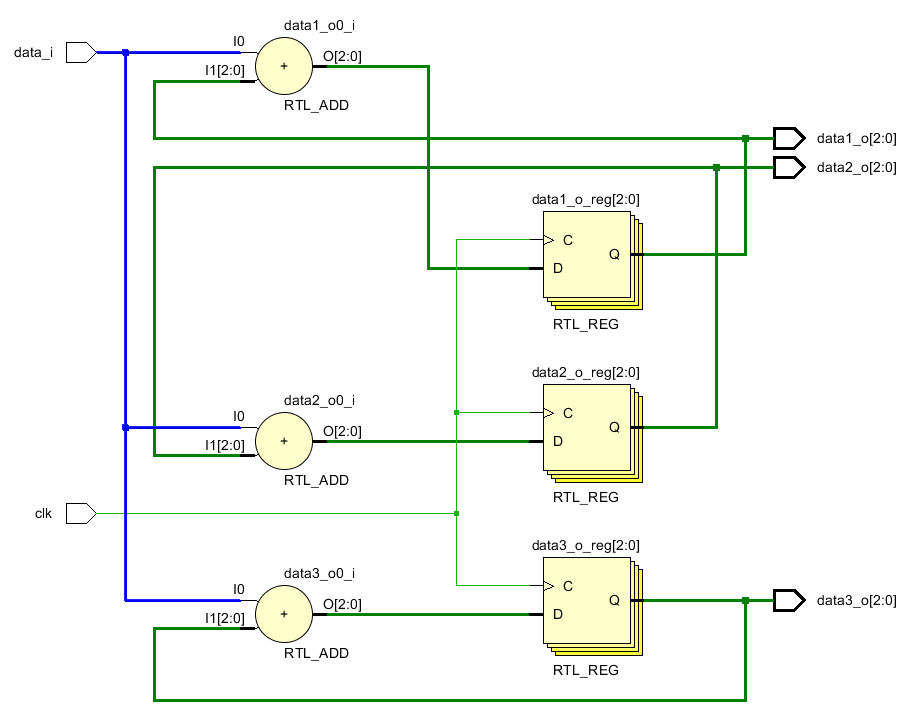
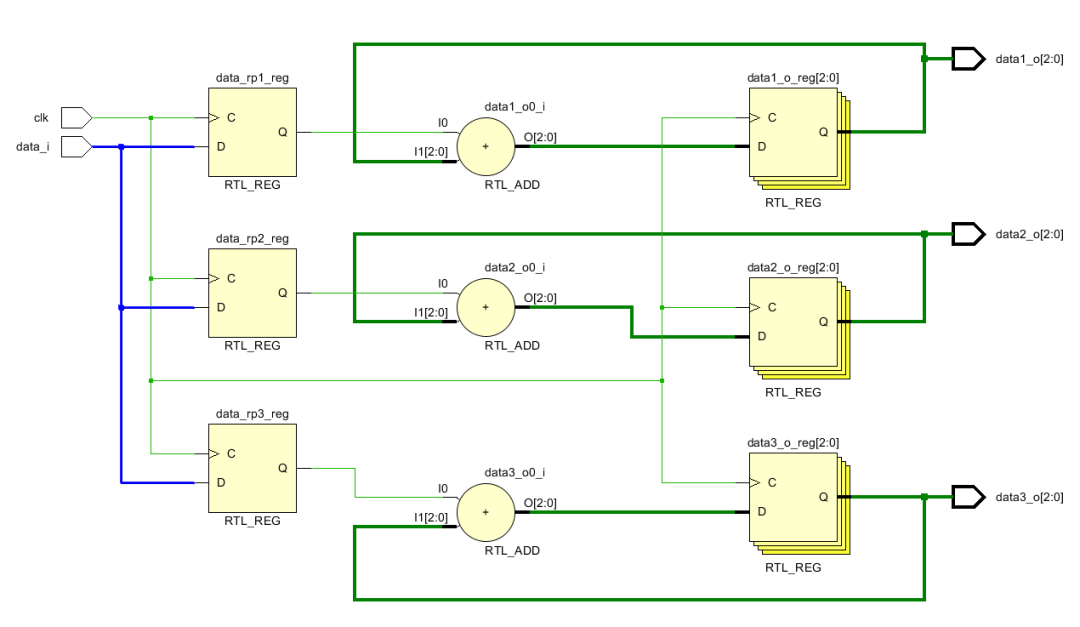
如果我们复制输入数据,如下图,从中可以看出输入信号复制了三份,分别接给三个加法器。
(* keep = "true" *)reg data_rp1;
(* keep = "true" *)reg data_rp2;
(* keep = "true" *)reg data_rp3;
always @(posedge clk)begin
data_rp1 <= data_i;
data_rp2 <= data_i;
data_rp3 <= data_i;
data1_o <= data_rp1 + data1_o;
data2_o <= data_rp2 + data2_o;
data3_o <= data_rp3 + data3_o;
end
4. URAM和BRAM使用
Xilinx器件中BRAM的大小是36Kbit,如果不使用校验位,可以配置成1-32bit位宽的存储。比如32x1K。在RTL代码中使用存储的时候,需要适配BRAM大小,这样可以不浪费BRAM存储空间。比如你需要使用一个FIFO,那么这个FIFO位宽32bit,那么它的深度512和1024配置,都消耗了一个BRAM。
BRAM输出中最好用register,不要直接接组合逻辑,这样会增加延时。BRAM中含有register,如果代码中输出有用到register,那么这个register在综合时会被移到BRAM内部。如果BRAM外要连接组合逻辑,最好在BRAM的register的外部在添加一个register,这样有更好的时序。
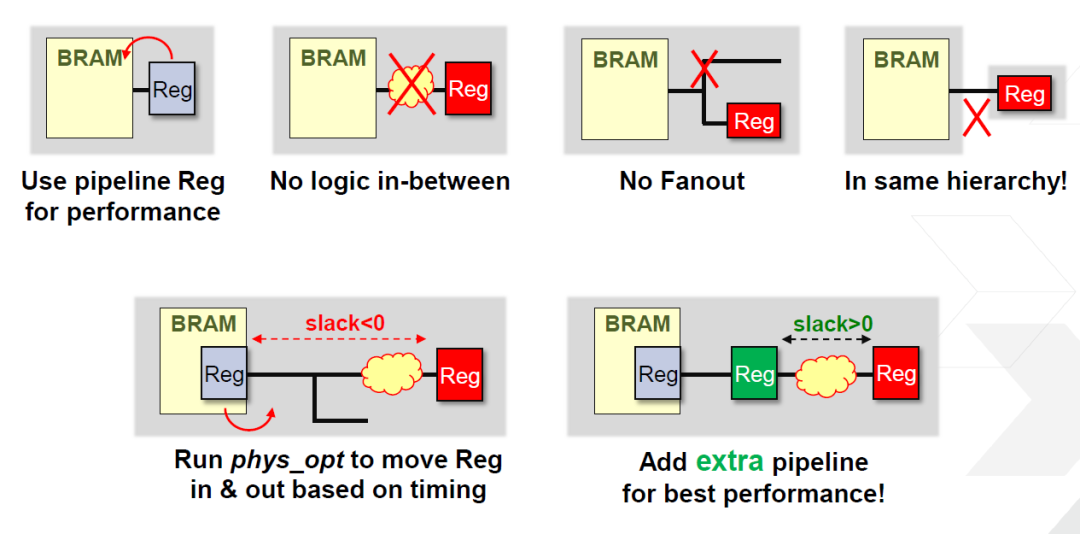
当我们需要的存储空间和位宽都超过了一个BRAM的时候,就涉及到多个BRAM的级联问题。如何选择单个BRAM的位宽拼接和级联BRAM的个数呢?比如我们要一个32bit位宽,深度为2**15大小的存储。有两种极限方式来配置BRAM。一种是将每个BRAM配置为1x32K,那么32个拼接组成32x32K的存储。另外一种是将每个BRAM设置为32x1K,那么32个级联形成32K深度。前一种不需要多余逻辑来对不同BRAM进行选择操作,但是32个BRAM同时读写,这样会增加power。而后一种32个BRAM级联在一起造成延时路径较长,同时需要增加组合逻辑来选择不同BRAM。但是每次只读写一个BRAM,power较低。可以选择这两个极限的中间值来即降低power也不会有太长的逻辑延时。可以通过约束条件来进行设置。如下图。级联设置为4,这样每次只有8个BRAM同时使能。
(* ram_style = "block", cascade_height = 4 *)
reg [31:0] mem[2**15-1:0];
reg [14:0] addr_reg;
always @(posedge clk)begin
addr_reg <= addr;
dout <= mem[addr_reg];
if(we)
mem[addr_reg] <= din;
end

URAM的使用方式类似,只不过URAM存储空间比BRAM大,其可以配置为72x64K大小。
5. 其它
1) 进行条件判定的时候,如果条件过多,尽量减少if-else语句的使用,尽可能用case替代。因为if-else是有优先级的,而case条件判断的平等的。前者会用掉更多逻辑;
2) 在一个always块中尽量对一个信号赋值,不要对具有不同判断条件的信号同时赋值,这样可以减少不必要的逻辑;
3) 尽量使用时钟同步复位,不要使用异步复位。即要用:
always @(posedge clk)begin
If(rst)
End
而不是
always @(posedge clk or posedge rst)
4) 在使用乘法较多的时候,使用DSP原语是最好的。一个DSP除了有乘法功能外,还有前加法器和后加法器,这两个是经常用到的,可以用来计算很多功能。DSP的具体使用可以参考DSP的手册。
总结
以上总结了几点在进行RTL代码设计时,最需要考虑的几种情况。这些对时序影响很大,需要注意。另外从整体来讲,如何选择一个好的算法,然后设计出一个简洁的架构更加重要。因为这些是从整体让你的设计有更多灵活的空间。
文章转载自: AI加速,转载此文目的在于传递更多信息,版权归原作者所有。