(一)AXI接口
如何设计高效的 PL 和 PS 数据交互通路是 ZYNQ 芯片设计的重中之重。AXI 全称 Advanced eXtensible Interface,是 Xilinx 从 6 系列的 FPGA 开始引入的一个接口协议,主要描述了主设备和从设备之间的数据传输方式。在 ZYNQ 中继续使用,版本是 AXI4,所以我们经常会看到 AXI4.0, ZYNQ 内部设备都有 AXI 接口。其实 AXI 就是 ARM 公司提出的AMBA(Advanced Microcontroller Bus Architecture)的一个部分,是一种高性能、高带宽、低延迟的片内总线。
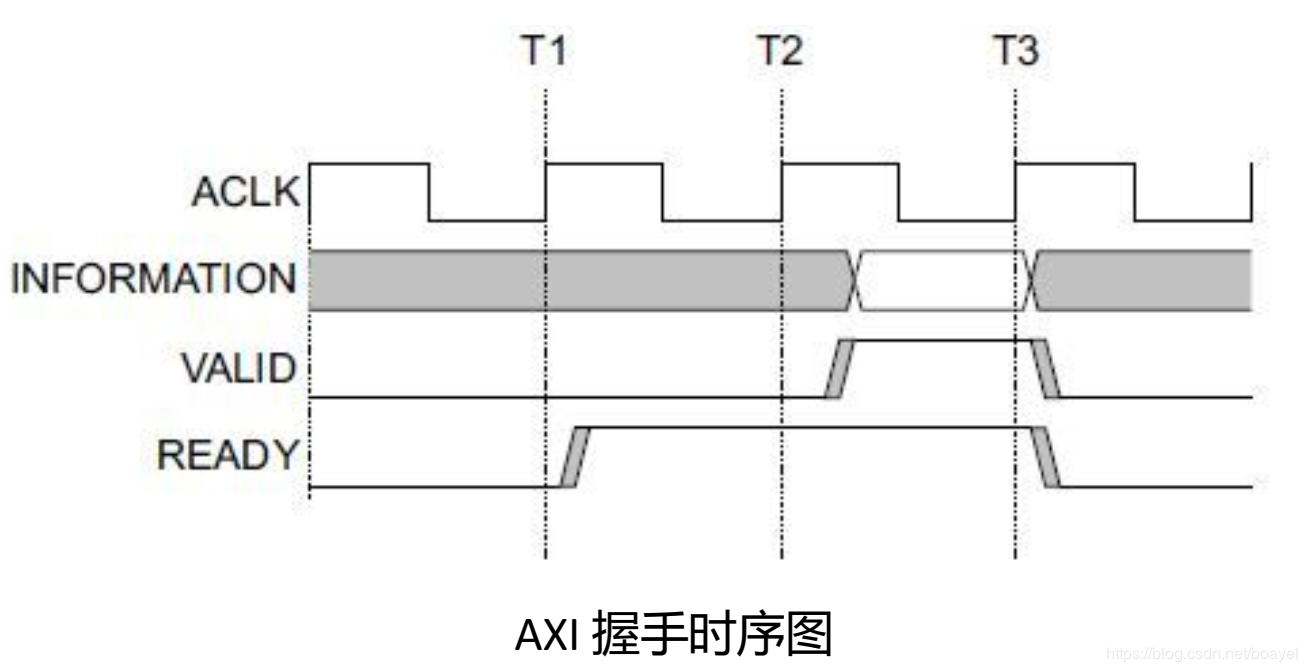
AXI 协议主要描述了主设备和从设备之间的数据传输方式,主设备和从设备之间通过握手信号建立连接。当从设备准备好接收数据时,会发出 READY 信号。当主设备的数据准备好时,会发出和维持 VALID 信号,表示数据有效。数据只有在 VALID 和 READY 信号都有效的时候才开始传输。当这两个信号持续保持有效,主设备会继续传输下一个数据。主设备可以撤销VALID 信号,或者从设备撤销 READY 信号终止传输。 AXI 的协议如图, T2 时,从设备的 READY信号有效, T3 时主设备的 VILID 信号有效,数据传输开始。
在 ZYNQ 中,支持 AXI-Lite, AXI4 和 AXI-Stream 三种总线,通过表以看到这三种AXI 接口的特性。

1、AXI4-Lite:
具有轻量级,结构简单的特点,适合小批量数据、简单控制场合。不支持批量传输,读写时一次只能读写一个字(32bit)。主要用于访问一些低速外设和外设的控制。
2、AXI4:
接口和 AXI-Lite 差不多,只是增加了一项功能就是批量传输,可以连续对一片地址进行一次性读写。也就是说具有数据读写的 burst 功能。
上面两种均采用内存映射控制方式,即 ARM 将用户自定义 IP 编入某一地址进行访问,读写时就像在读写自己的片内 RAM,编程也很方便,开发难度较低。代价就是资源占用过多,需要额外的读地址线、写地址线、读数据线、写数据线、写应答线。
3、AXI4-Stream:
这是一种连续流接口,不需要地址线(很像 FIFO,一直读或一直写就行)。对于这类 IP,ARM 不能通过上面的内存映射方式控制(FIFO 根本没有地址的概念),必须有一个转换装置,例如 AXI-DMA 模块来实现内存映射到流式接口的转换。 AXI-Stream 适用的场合有很多:视频流处理;通信协议转换;数字信号处理;无线通信等。其本质都是针对数值流构建的数据通路,从信源(例如 ARM 内存、 DMA、无线接收前端等)到信宿(例如 HDMI 显示器、高速 AD 音频输出,等)构建起连续的数据流。这种接口适合做实时信号处理。
在 ZYNQ 芯片内部用硬件实现了 AXI 总线协议,包括 9 个物理接口,分别为 AXI-GP0~AXIGP3, AXI-HP0~AXI-HP3, AXI-ACP 接口。AXI_ACP 接口,是 ARM 多核架构下定义的一种接口,中文翻译为加速器一致性端口,用来管理 DMA 之类的不带缓存的 AXI 外设, PS 端是 Slave 接口。AXI_HP 接口,是高性能/带宽的 AXI3.0 标准的接口,总共有四个, PL 模块作为主设备连接。主要用于 PL 访问 PS 上的存储器(DDR 和 On-Chip RAM)AXI_GP 接口,是通用的 AXI 接口,总共有四个,包括两个 32 位主设备接口和两个 32 位从设备接口。
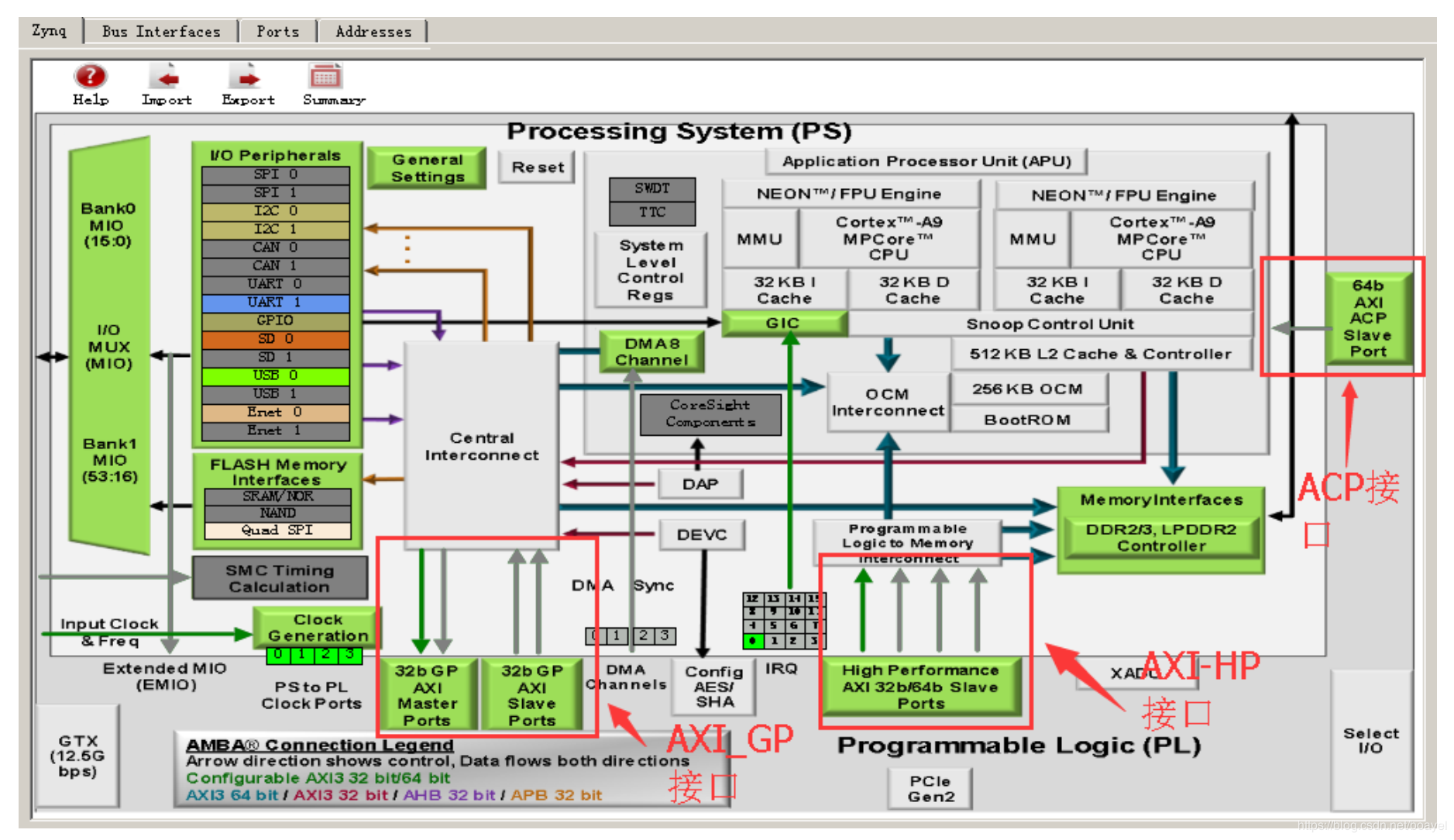
只有两个 AXI-GP 是 Master Port,即主机接口,其余 7 个口都是 Slave Port(从机接口)。主机接口具有发起读写的权限, ARM 可以利用两个 AXI-GP 主机接口主动访问 PL 逻辑,其实就是把 PL 映射到某个地址,读写 PL 寄存器如同在读写自己的存储器。其余从机接口就属于被动接口,接受来自 PL 的读写,逆来顺受。
另外这 9 个 AXI 接口性能也是不同的。 GP 接口是 32 位的低性能接口,理论带宽600MB/s,而 HP 和 ACP 接口为 64 位高性能接口,理论带宽 1200MB/s。
位于 PS 端的 ARM 直接有硬件支持 AXI 接口,而 PL 则需要使用逻辑实现相应的 AXI 协议。Xilinx 在 Vivado 开发环境里提供现成 IP 如 AXI-DMA, AXI-GPIO, AXI-Dataover, AXI-Stream 都实现了相应的接口,使用时直接从 Vivado 的 IP 列表中添加即可实现相应的功能。
下图为 Vivado 下的各种 DMA IP:
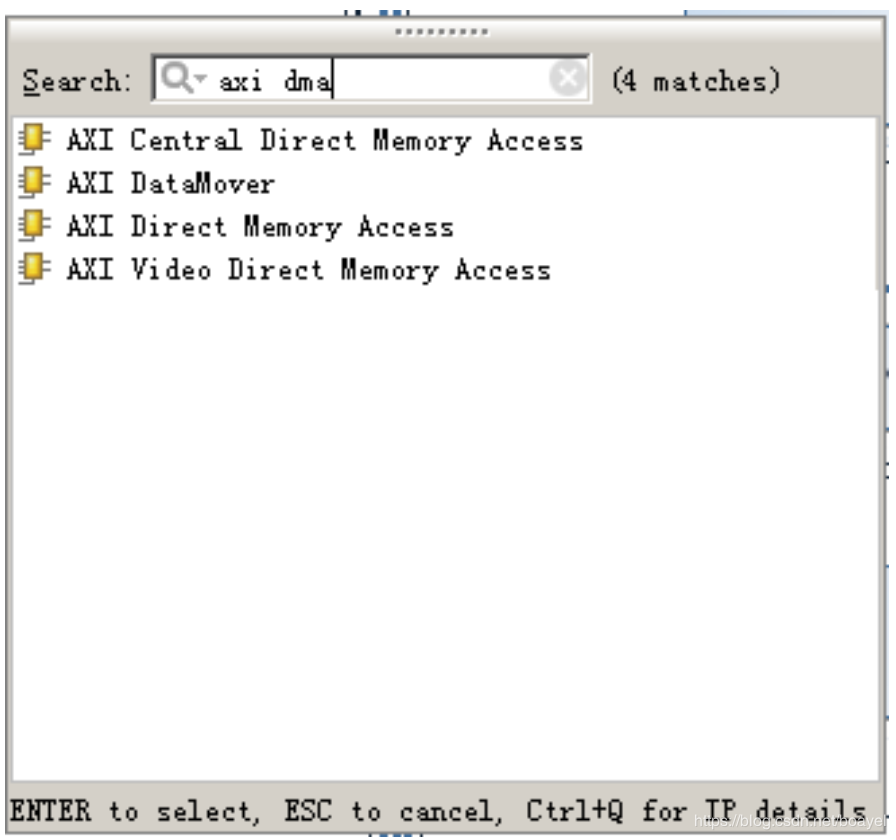
几个常用的 AXI 接口 IP 的功能:
- AXI-DMA:实现从 PS 内存到 PL 高速传输高速通道 AXI-HP<---->AXI-Stream 的转换
- AXI-FIFO-MM2S:实现从 PS 内存到 PL 通用传输通道 AXI-GP<----->AXI-Stream 的转换
- AXI-Datamover:实现从 PS 内存到 PL 高速传输高速通道 AXI-HP<---->AXI-Stream 的转换,只不过这次是完全由 PL 控制的, PS 是完全被动的。
- AXI-VDMA:实现从 PS 内存到 PL 高速传输高速通道 AXI-HP<---->AXI-Stream 的转换,只不过是专门针对视频、图像等二维数据的。
- AXI-CDMA:这个是由 PL 完成的将数据从内存的一个位置搬移到另一个位置,无需 CPU 来插手。
(二)AXI 交换机制
AXI 协议严格的讲是一个点对点的主从接口协议,当多个外设需要互相交互数据时,我们需要加入一个 AXI Interconnect 模块,也就是 AXI 互联矩阵,作用是提供将一个或多个 AXI 主设备连接到一个或多个 AXI 从设备的一种交换机制(有点类似于交换机里面的交换矩阵)。这个 AXI Interconnect IP 核最多可以支持 16 个主设备、 16 个从设备,如果需要更多的接口,可以多加入几个 IP 核。
AXI Interconnect 基本连接模式有以下几种:
- N-to-1 Interconnect
- to-N Interconnect
- N-to-M Interconnect (Crossbar Mode)
- N-to-M Interconnect (Shared Access Mode)

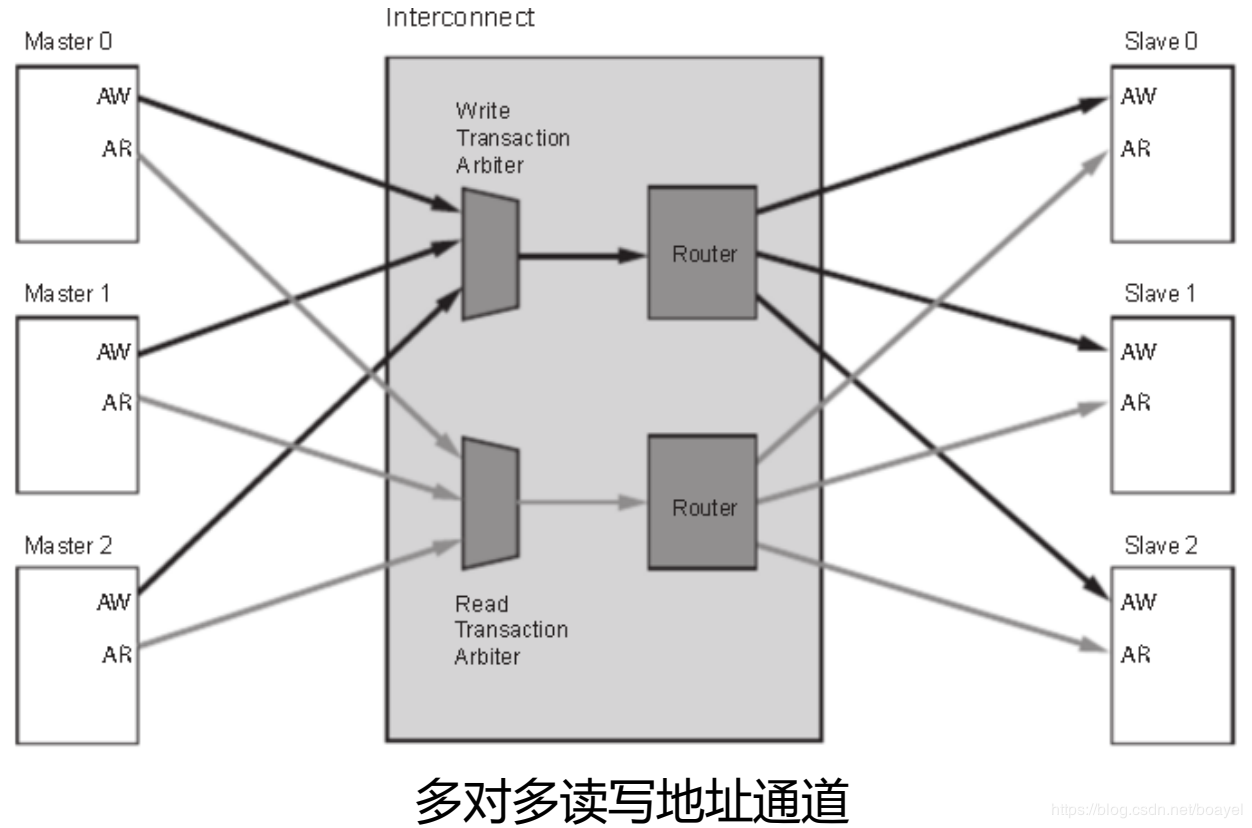
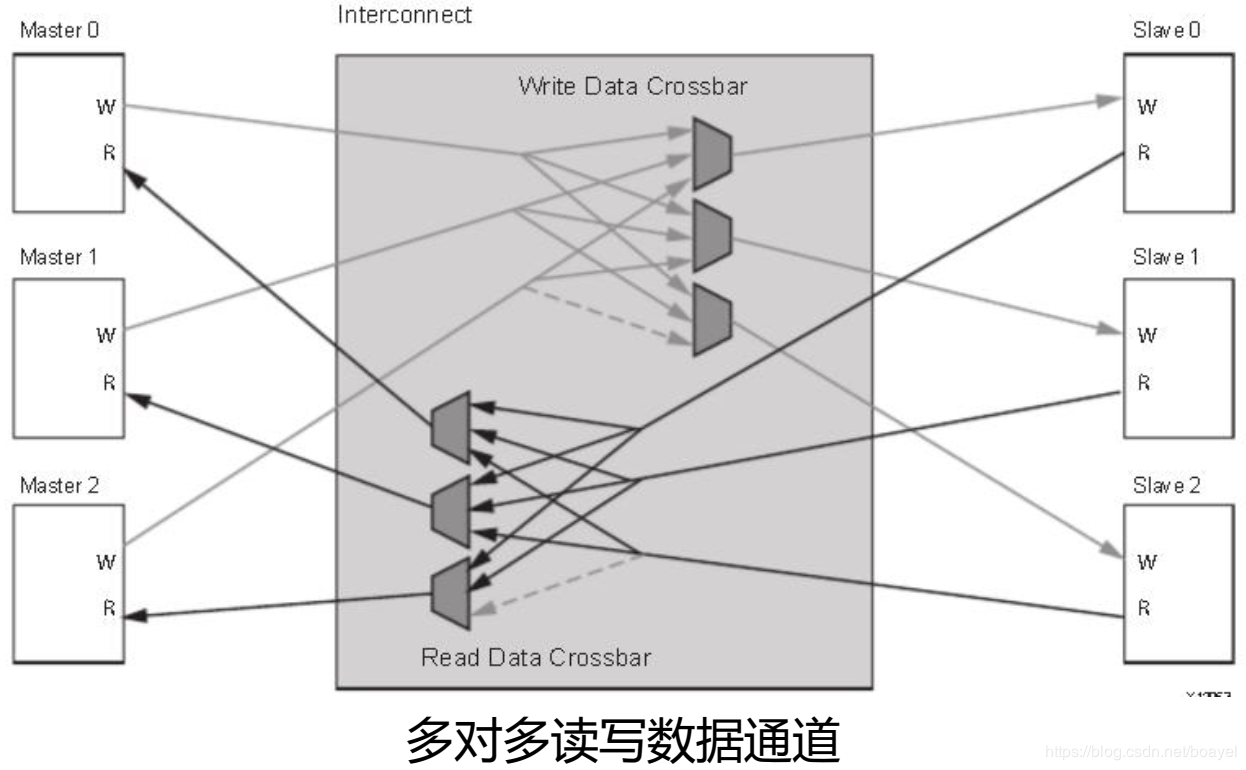
ZYNQ 内部的 AXI 接口设备就是通过互联矩阵的的方式互联起来的,既保证了传输数据的高效性,又保证了连接的灵活性。 Xilinx 在 Vivado 里我们提供了实现这种互联矩阵的 IP 核axi_interconnect,我们只要调用就可以。
版权声明:本文为CSDN博主「肃宁老赵」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/boayel/article/details/104090014





