作者:王韵,雪湖科技联合创始人兼 COO
调查数据显示,2019 年区域流量容量提升了100 倍,带宽年复合增长率达到了 51%。面对流量洪峰、面对数据大爆炸,算力不足问题开始凸显并得到越来越多企业的重视。在这样的时代背景下,以出色算力提升企业运作效率的 FPGA 博得了诸多互联网公司的青睐。
作为一家专注于的深度学习加速器和 FPGA 硬件加速的国家高新技术企业,“愿算力与你同在”是雪湖科技的口号,并印在了公司的文化衫上。前不久,赛灵思邀请雪湖科技联合创始人兼 COO 王韵先生,就算力与 FPGA 话题进行了深入分享,同时讲述了雪湖科技如何基于赛灵思 FPGA 做“算力赋能”。
算力缺口不断扩大
全世界电力用上都还不够
“愿算力与你同在”这句话其实致敬了星战里的那句“愿原力与你同在”。熟悉星战的朋友一定知道,“原力”是星球大战里一种超自然的,而又无处不在的神秘力量,是所有生物创造的一个能量场,帮助绝地武士们拥有超越其他人的能力。——雪湖科技联合创始人兼 COO王韵
“算力”在未来,就像当年的蒸汽机、电力一样,俨然已经是生产力发展的核心要素,也就是说,谁拥有超越别人的“算力”,谁就会拥有更高的生产力和效率,谁也就能在创新上实现真正的突破,成为推动产业和时代进步的原动力。所以“算力”会和“原力”一样成为人们期望拥有的能力。
5G、AI 和 AIoT,让所有东西都联网和数字化,使得算力缺口不断扩大,从端侧到云端,数据运算需求呈现指数级增长,都在思考如何打破“算力瓶颈”。也许你会说,可以用 CPU 和 GPU 啊?曾经有人算过,不断增长的加速需求全部用 GPU 来算的话,用上全世界的电力可能也不够,所以光用 GPU 做加速显然不现实。
在我看来,根据场景不同将来算力会分布在从云到端的各个环节上。站在这几年非常流行的“上云万能论”的角度来看,有许多场景的需求无法通过云解决,以智能驾驶场景为例,计算结果需要在毫秒级反馈到控制系统,显然云端计算变得不现实。相信 FPGA 的灵活性可以为更多场景做“算力赋能”。
FPGA如乐高积木
以 ASIC 思路做 FPGA 开发
我是一个半导体行业的老兵,在芯片原厂工作的十几年里,几乎接触过市面上所有类型的芯片。在这么多的芯片里,FPGA 是最特殊的,它“乐高积木”一样的特点让人着迷。
这几年,异构计算和硬件加速是非常值得期待的市场。从当下 4000 多亿美金全球的芯片市场规模来说,FPGA 芯片的 60 多亿不那么大,但随着 ABC(AI,Bigdata,Cloud)和 5G 的推动,从端到云都可能面临“算不过来”的窘境,这对于擅长做加速的 FPGA 来说市场潜力极大。按照 Gartner 的预测,到 2025 年 FPGA 芯片市场将增长到 125 亿美金,非常值得期待。

*图1为FPGA与ASIC方案成本比较(源自兴业证券)
然而,几十年来 FPGA 也一直面临 ASIC 的竞争。通常认为,客户的产品在达到一定体量后,从成本角度会迁移到 ASIC。雪湖科技认为,虽然这样的竞争无法避免,但如果能把“Crossover Point(交叉点)”往右边延伸(如图1),那就能扩大 FPGA 应用市场的空间,充分受益于异构计算强大的算力优势。所以雪湖科技选择“用 ASIC 的思路去做 FPGA 开发”,在应用开发的过程中,珍惜一点一滴的计算资源,从时间利用率和空间利用率上做优化,最终通过提升 FPGA 的资源使用率来提升应用端加速性能。
这样给客户带来的价值就是,因为性能提升延长了成本切换的时间点,让一部分原本 ASIC 的市场变成 FPGA 的市场。即使在云端也是一样,性能的极致优化和提升可以为客户提升 TCO,剩下大把的成本,可以用来专注于提升云端的服务能力。
雪湖CEO 张强在 FPGA 数值计算加速领域经验丰富,曾经参与过微软基金会的创新项目“激光打蚊子”,在 Vertex2PRO 上实现了每秒钟处理 500 帧图片,每张图片识别 4096 只蚊子的惊人效果,而这一些都是通过对计算资源极致优化来完成的。雪湖已经拥有 40 位 FPGA 开发者人员,秉承“用设计 ASIC 的思路做 FPGA 的开发”的理念,已经成功在人工智能,智能驾驶,数据中心和高性能计算领域完成布局。
Wide and Deep加速器
算法懂你,还得懂赚钱
提升算力的关键,首先一定是硬件的提升,FPGA的低延迟及高吞吐相对GPU有绝对的优势,因此越来越多的企业意识到了这一点,已经开始率先使用FPGA来提升算力。
在赛灵思开发者大会 XDF 2019 上,阿里云的 FPGA 异构计算负责人张振祥也说,在今年优酷的国庆阅兵直播,以及天猫双十一晚会直播,阿里云都采用了 FPGA 的转码方案。我们了解到,天猫双十一的图片转码也都是用 FPGA 做的。这里可以看出一个趋势,FPGA 还会随着双十一销售额交易量的攀升得到更为广泛的运用。可以预见,FPGA 在互联网基础业务领域有很多应用场景。
雪湖也有幸参与到了本届 XDF,并且与赛灵思共同推出了基于赛灵思 Alveo U200 加速卡实现的“Wide and Deep 广告推荐算法加速解决方案”,相较于CPU服务器,基于FPGA加速器打造的这一解决方案,将吞吐量提高了 3~5 倍,加上功耗更低,其 TOC(总体拥有成本)是 CPU 云的 5 倍以上。
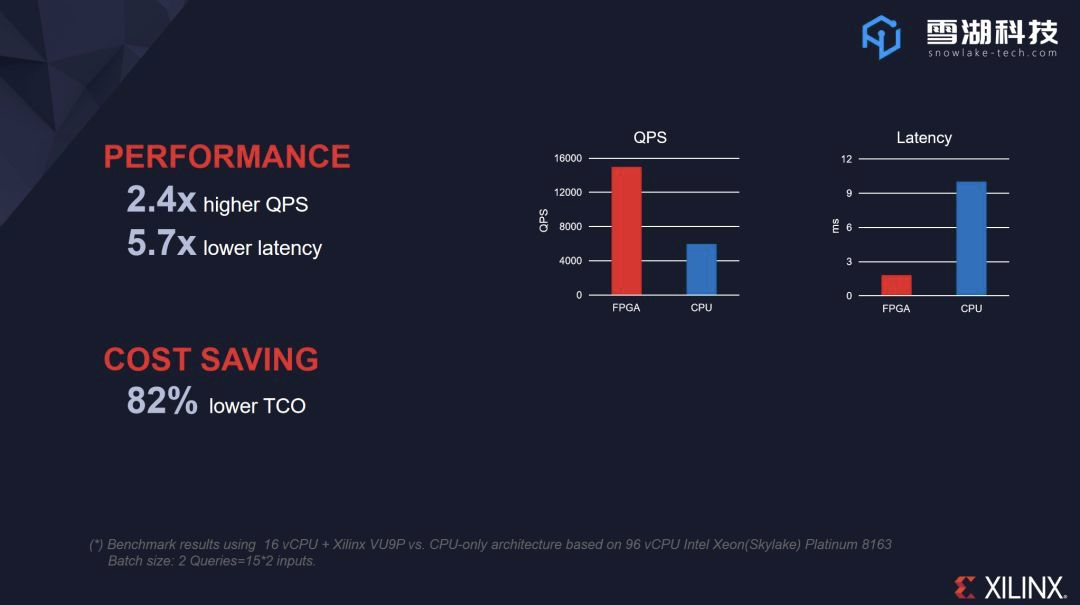
图2为FPGA vs CPU基于FPGA的推荐算法性能比较
推荐系统是互联网公司运营的核心,内容推荐会影响留存,转化和成交转化;广告推荐会直接影响点击率(CTR),进而影响广告收入。看到互联网公司对广告投放、内容点击率的痛点,我们开发了基于 FPGA 的广告推荐加速器。
推荐系统中,CTR 至关重要,在云音乐推荐的“今日歌单”,抖音上的短视频,购物 APP 的“猜你喜欢”等场景中,CTR 值反映的是推荐系统的准确率,它影响着用户是去是留,也决定着互联网企业的广告收益。
为了达成精准的推荐和投放, 2016 年谷歌提出了“Wide and Deep”算法模型,现在已经被 Facebook、Youtube 等国际领先的互联网公司广泛使用。考虑到部署于 GPU 的成本高,这一算法以往采用 CPU 来加速,但性能并不理想。在这个背景下,我们与赛灵思针对数据中心广告推荐算法加速推出“Wide and Deep算法推荐系统”高性能解决方案。

*赛灵思Alveo U200数据中心加速器卡
在完成推荐过程时,我们会根据用户信息提取用户自画像和商品属性,输入到模型,再根据相应算子得出最终结果。基于赛灵思 U200 构建出的“Wide and Deep”加速器,能够根据模型 API 制作出雪湖科技 API,再由自研发的工具包将模型和数据转换为可由 FPGA 处理的数据,从而快速计算出结果。
将结果进行处理和排序后,也就是我们日常可见的推荐界面了。由于不同的用户有不同的个人信息和喜好,经过模型计算也会有不同的结果,也就对应出不同的推荐内容。
另外,考虑到大型推荐系统的上线都是通过云端部署,同时用在线和离线方式更新模型。除了 U200 加速卡,我们同样支持 Wide and Deep 在阿里云 FPGA 服务器 F3(FPGA:赛灵思 VU9P)上的部署应用,用户可以通过镜像文件部署。根据最近的更新数据显示,模型精度损失可控制在 2/100000。当模型更新时,通过雪湖科技提供的专有工具可直接载入模型参数,可做到一键式更新模型参数。
目前,互联网公司在算法推荐上的需求持续增长,在让企业看到 FPGA 的性能预期之外,我们还希望通过这些操作上的便利,能提供到奉行最小可行性测试的互联网行业最为喜闻乐见的方案,让他们能低成本地拥抱变化,进一步满足人们‘听我想听’、‘看我想看’、‘买我想买’的‘懒惰’需求,另一维度上,广告主的带货KPI能被更高效的完成,企业的广告售卖单价能够提升,FPGA 的价值也就体现了。
除了推荐算法,雪湖对于硬件加速和算力提升的探索还在继续,“愿算力与你同在”!
关于作者
王韵,雪湖科技联合创始人兼 COO,日本国立九州大学硕士,师从著名产业经济学家山崎朗。半导体行业老兵,在该领域拥有超过 15 年工作经验。曾服务于全球 500 强日本富士通集团,任职亚太区高管负责半导体芯片的市场营销业务。
文章转载自:一点灵Xi微信公众号





