本文转载自:PYNQ开源社区微信公众号
感兴趣者可与 pynq_china@xilinx.com 联系,共同合作拓展项目。
什么是类脑计算?
虽然在海量标注数据和快速增长的计算力的驱动下,以深度学习为代表的人工智能技术迅猛发展并在许多领域已进入实用阶段。但人们也越来越认识到:深度学习还有“需要海量标注数据、通用智能水平弱”等许多局限性,难以成为解决人工智能问题的终极手段。而且随着摩尔定律放缓、登纳德缩放定律失效,能效问题日益成为计算机系统发展的重要制约因素,深度学习高度依靠计算力的方式面临严峻挑战。而人的大脑是由约 10^11 个神经元、10^15个突触构成的复杂的生物体,具有很高的智能水平但功耗只有 25 瓦左右,其计算模式值得借鉴。因此各国纷纷推出“脑计划”,希望通过解析大脑工作机理,发展类脑计算,克服现有深度学习的不足。
类脑计算的基础是脉冲神经网络(SNN, Spiking Neural Network),相比 DNN(Deep Neural Networks)等第二代神经网络,SNN 工作机理更接近于生物大脑,因此被认为是第三代神经网络。类脑计算研究的一个重要任务是探索最适合SNN运行的类脑体系结构,研制高性能、低功耗的类脑计算机。
现有实现办法
世界上最大的类脑超级计算机SpiNNaker拥有100万个ARM处理器内核,每秒可执行200万亿次操作,作为欧洲人脑计划类脑计算的一个平台,能够达到人脑百分之一的比例,是第一个低功耗、大规模人脑数字模型,重新定义了传统计算机的工作方式。
整体架构采用芯片、包、板集,系统的方式层层组建。每个处理器芯片是ARM968,包含32kB的指令存储,64kB的数据存储。每个包由18个ARM968处理器芯片组成,每个板集包含48个包,3个FPGAs芯片用于高速通信。系统则由1200个板集组成。最终形成1036800个芯片集群。
SpiNNaker 能够建模达到人脑百分之一的比例,是类脑仿真的第一个低功耗、大规模数字模型。通过SpiNNaker,研究人员将能够精确地模拟脑区,并且测试有关大脑工作的假说。SpiNNaker的整体架构突破了冯诺依曼式束缚,为新一代类脑芯片研究与发展提供贡献。SpiNNaker采用了神经形态的组织结构和新兴的“脉冲神经网络”算法,因此具有更低的功耗。但也正因为如此,其数据编码信息损失很大,导致算法准确度不及目前的成熟算法。
随着神经科学的进一步发展,人们对大脑神经系统工作方式的逐渐清晰,脉冲神经网络算法可望进一步发展,其准确度也可望得到进一步提高从而可以实用。
适合的开放平台
尽管目前已有许多类脑芯片和系统方面的工作, 如 SpiNNaker、 Loihi等以专用芯片和系统的方式针对 SNN运行做了优化支持。但当所选择运行的SNN工作负载的特性与硬件平台不相匹配时,会导致专用类脑系统的计算能效甚至还不如通用计算机系统。例如,当在SpiNNaker上运行一个具有8万神经元、3 亿突触的全尺寸皮质微电路模型(SpiNNaker 上迄今为止运行的最大模型),SpiNNaker 的计算能效表现还不如基于高性能集群的 NEST 软件模拟方式以及单块 GPU 方式,原因就是因为该模型中神经元联接的突触数量超过了 SpiNNaker 设定的最优值。这意味着当设计类脑芯片和系统时,如果没有针对所选领域 SNN 负载特性进行透彻地研究,或所选的 SNN 模型和系统覆盖不全,都可能会导致所设计的类脑系统达不到预期效果。
与 DNN相比,SNN 的研究还不算多。究其原因,SNN 的主要构成是神经元、突触、联接、学习机制与可塑性。其中每个神经元独立地根据接收到的脉冲信号情况更新状态并决定是否产生输出脉冲。同时,依据 STDP,神经元可以根据局部的脉冲时间关系调整突触的权重。所以 SNN 计算模式本身具有明显的分布式计算的特点。对于大规模 SNN 系统进行研究需要有适合的大规模分布式计算平台的支撑。
作为第三代神经网络技术,基于 SNN 的类脑计算的研究仍处于初期阶段,研究人员还无法方便地获得像深度学习一样众多的软件环境和硬件平台的支持。
OpenHEC云上的类脑计算平台
为了给社区提供一个可用于类脑计算研究的大规模、分布式、软硬件融合的平台,推动类脑计算系统的研究,江南大学人工智能与计算机学院柴志雷老师团队在OpenHEC云平台上搭建了基于100个Xilinx PYNQ-Z2节点的FPGA集群,并开放给研究人员使用。
PYNQ集群的节点之间采用千兆以太网通信。PYNQ-Z2节点包括PS(Process System)端的ARM A9双核处理器系统和PL(可编程逻辑)端的FPGA资源。
该团队在上述PYNQ集群上通过对NEST(NEST是一款使用广泛的类脑模拟器)进行软硬件协同优化,完成了一款高能效的类脑计算系统。为了更好地推动该领域的研究,团队将该项目的软件代码与HLS代码开源。相信以开源项目结合开放硬件平台的,将会为该领域的研究人员提供更大的便利。

集群架构图

集群实物图
PYNQcluster上的类脑计算系统性能表现
在PYNQcluster上,通过ARM处理器集群并基于FPGA对神经元计算进行加速,大幅提升了类脑计算系统的性能。运行的实例为基于STDP和HMAX模型的无监督图像识别的脉冲神经网络。由于使用的图片大小为300*300,神经元数据超过了单块PYNQ的内存大小,所以最少需要采用2块arm+FPGA来进行性能测试。基于PYNQcluster的实验结果分别与AMD Ryzen5 3600X和Intel i5-5200平台上的运行结果进行了对比。为了对比更加直观,AMD Ryzen5 3600X和Intel i5-5200都只使用2个线程进行测试,通过对比发现2节点arm+FPGA方式的类脑计算系统的计算性能是arm上运行NEST软件模拟器的12.83倍,是i5-5200的1.37倍,计算性能十分接近采用7nm工艺的AMD Ryzen5 3600X。采用100节点arm+FPGA方式在运行时是2节点版本的47.75倍,也就是i5的65.41倍。
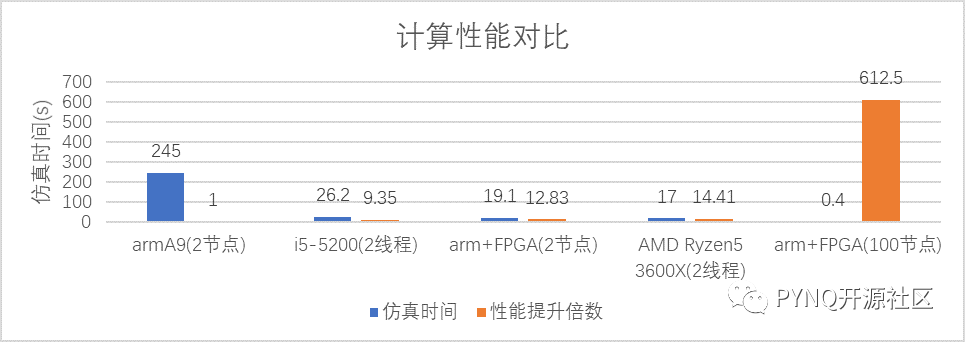
计算性能对比图
在能效比方面, 100节点的PYNQcluster的能效比是AMD Ryzen5 3600X能效比的12.7倍,是i5-5200的20.9倍。
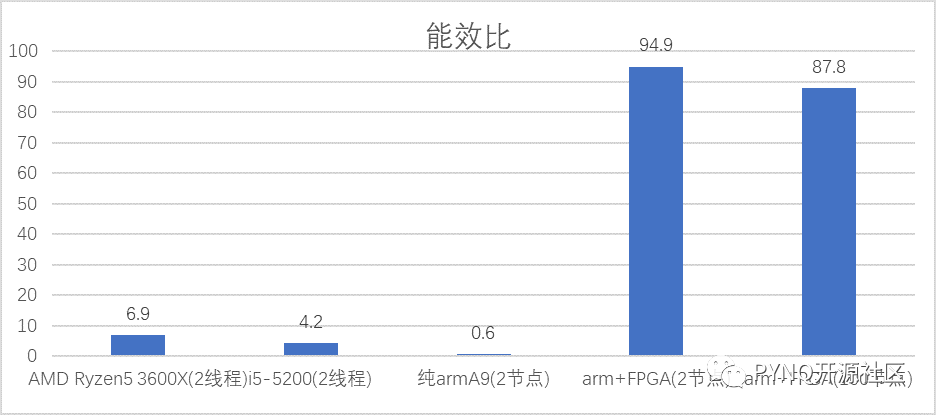
能效比对图
进一步合作的机会
本平台的用户分两类:一类是类脑计算平台的使用者,可以使用平台进行类脑应用的运行和分析;第二类是类脑系统的研究者,可以基于该平台进行硬件加速、芯片与系统方面的研究。
本平台设计全部开源,点击阅读原文可获得Github链接。同时PYNQcluster硬件平台也以公有云方式对外提供。对类脑系统研究感兴趣的人员可以通过远程访问的方式使用平台,并在开源项目的基础上进行更深入的研究,感兴趣者可与 pynq_china@xilinx.com 联系,共同合作拓展项目。
注:该项目得到国家自然科学基金“(61972180)基于工作负载表征的类脑体系结构基准测试模型与自动映射方法研究”的支持。





