本文转载自:PYNQ开源社区微信公众号
上期推送为大家带来了A班的优秀作品合集。本期,小编为大家带来了B班优秀作品的基于PYNQ的SSD目标检测系统项目。B班的作品相较于A班更有挑战性,内容也更丰富一些。本篇推送主要介绍设计概述,如果有想要亲自尝试本系统的同学,请复制下方Github链接前往GitHub,即可看到本项目的开源代码哦!
github链接:https://github.com/Memory-bread/SSD_IN_PYNQ
设计目的与应用
随着人工智能的发展,神经网络正被逐步应用于智能安防、自动驾驶、医疗等各行各业。目标识别作为人工智能的一项重要应用也拥有着巨大的前景,随着深度学习的普及和框架的成熟,卷积神经网络模型的识别精度越来越高。有名的LeNet-5手写数字识别网络,精度达到99%,AlexNet模型和VGG-16模型的提出突破了传统图像识别算法,GooLeNet和ResNet推动了卷积神经网络的应用。
但是神经网络的发展也给我们带来了更多挑战,权重参数越来越多,计算量越来越大导致了复杂的模型很难移植到移动端或嵌入式设备中,且嵌入式环境对功耗、实时性、存储都有着严格的约束。因此如何将卷积神经网络部署到嵌入式设备中是一件非常有意义的事情。目前神经网络在传统嵌入式设备上绝大部分是基于ARM平台,神经网络在ARM上部署时存在的巨大问题是算力的不足。GPU主要应用于神经网络训练阶段,对环境和库的依赖性较大,国内技术积累较弱,难以实现技术自主可控。ASIC 是为特定需求而专门定制优化开发的架构,灵活性较差,缺乏统一的软硬件开发环境,开发周期长且造价极高。所以,基于FPGA的硬件加速平台是时候发挥它的优势了。FPGA由于独特的架构,被广泛的应用与实时信号处理、图像处理领域,其并行性也为卷积神经网络提供了巨大算力。
传统的RTL开发FPGA流程相比缓慢,不如软件的开发效率高,所以HLS运营而生,使用高层次语言来进行转换为底层的硬件代码,极大的加快开发进程。因此项目选用HLS工具来实现算法中的加速IP核,将SSD目标检测网络移植到FPGA硬件平台上, 对于硬件加速过程中的算法并行性,在本设计中主要采用两个方式:对层内的运算并行化,将多个通道的数据进行分块,每一块内的通道同时进行运算,最后将结果累加在一起。对于模块的运算采用HLS并行优化,对数组核循环添加优化指令进行优化。整个系统采用PYNQ的软件框架来实现,为SSD目标检测算法提供了硬件加速方案,充分发挥了FPGA的并行性。
SSD目标检测算法原理
SSD于2016年提出,是经典的单阶段目标检测模型之一。它的精度可以媲美FasterRcnn双阶段目标检测方法,速度却达到了59FPS(512x512,TitanV),单阶段目标检测方法的目标检测和分类是同时完成的,其主要思路是利用CNN提取特征后,均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,物体分类与预测框的回归同时进行,整个过程只需要一步,所以其优势是速度快。
SSD采用的主干网络是VGG网络,VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。该模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了优异成绩:在分类任务上排名第二,在定位任务上排名第一。
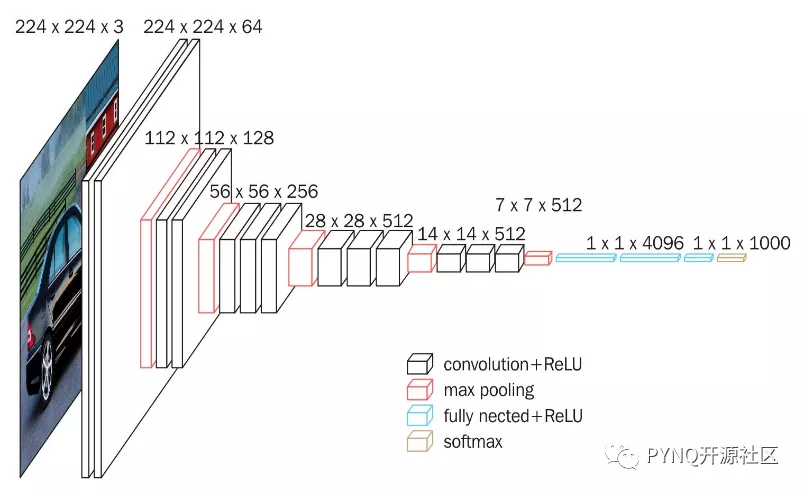
图1.VGG16网络结构
这里的VGG网络相比普通的VGG网络有一定的修改,主要修改的地方就是:
1、将VGG16的FC6和FC7层转化为卷积层。
2、去掉所有的Dropout层和FC8层;
3、新增了Conv6、Conv7、Conv8、Conv9。
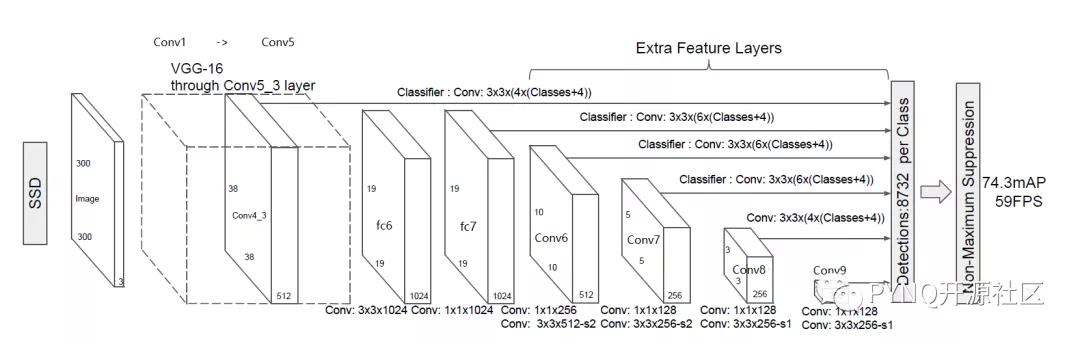
图2.SSD主干网络结构
上图展示了SSD的主干网络结构,整个网络为全卷积网络结构,SSD将VGG16的两个全连接层转换成了普通的卷积层,池化层POOL5由原来的stride=2,kernel大小2x2变成stride=1,kernel大小3x3,为了不改变特征图大小同时获得更大的感受野,Conv6改为空洞卷积,diliation=6,输入的图片经过了改进的VGG网络(Conv1->fc7)和几个另加的卷积层(Conv6->Conv9)进行特征提取。
从图2我们可以看出,SSD将conv4_3、conv7、conv6_2、conv7_2、conv8_2、conv9_2都连接到了最后的检测分类层做回归,6个特征图分别预测不同大小和长宽比的边界框,具体细节如图3。

图3.SSD特征提取网络
SSD为每个检测层都预定义了不同大小的先验框(prior boxes),Conv4_3、Conv8_2和Conv9_2分别有4个先验框,而Conv7、conv7_2和Conv8_2分别有6种先验框,即对应于特征图上的每个像素,都会生成4或6个prior box.
在浅层的神经网络里,只能看到图片的细节和纹理信息,就如管中窥豹。随着网络层数的加深,相当于把图片往后移动一段距离。这样才能够感知到图片的整体信息。低层卷积可以捕捉到更多的细节信息,高层卷积可以捕捉到更多的抽象信息。低层特性更关心“在哪里”,但分类准确度不高,而高层特性更关心“是什么”,但丢失了物体的位置信息。SSD正是利用不同尺度检测图片中不同大小和类别的目标物体,获得了很好的效果。
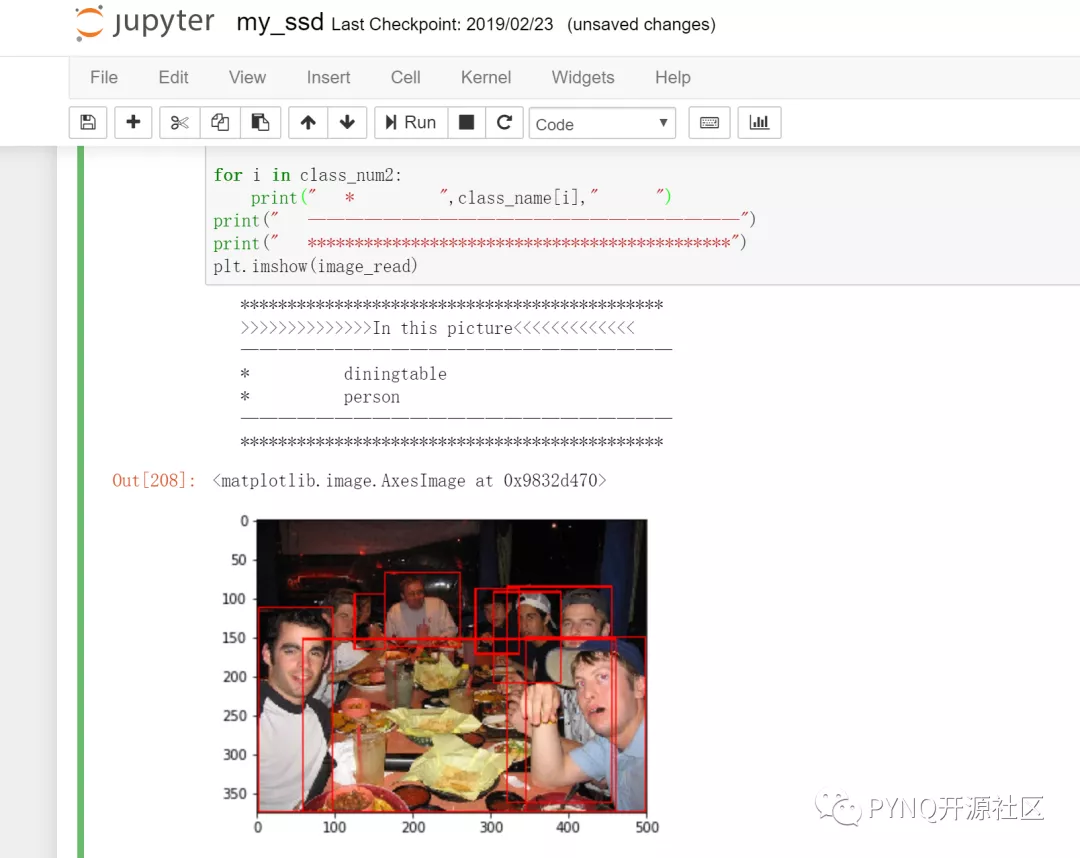
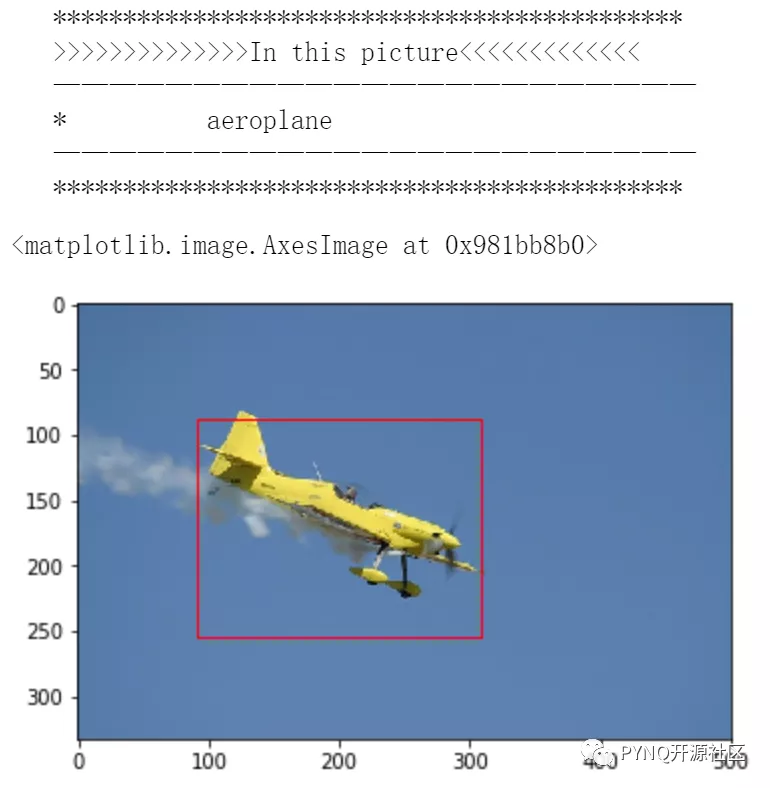
作品展示