近日 MLPerf 组织发布了最新一轮的机器学习 (ML) 推断基准测试结果。MLPerf 成立于 2018 年,是一个由超过 23 家提交组织组成的开源社区,其使命是制定一套标准化 ML 基准。该小组的 ML 推断基准测试提供了一个公认的通用流程,用于衡量不同类型的加速器以及系统执行受训神经网络的速度和效率。
此次是赛灵思首次直接参与 MLPerf 测试。虽然参与测试已经让我们感到欣喜,但能够在图像分类类别中取得领导地位更让我们喜出望外。我们与 Mipsology 合作,参加更严格的“封闭”基准测试。该测试向厂商提供预训练网络和预训练权重,开展真正的“同类”测评。
测试系统使用赛灵思 Alveo U250 加速器卡,该卡以 Mipsology 优化的领域专用架构 (DSA) 为基础。基准测试测量了我们基于 Alveo 的定制 DSA 在离线模式下以 5,011 图像/秒的速度执行基于 ResNet-50 基准的图像分类任务的效率。ResNet-50 以图像/秒为单位测量图像分类性能。
我们实现了最高的性能/峰值(TOP/s,每秒万亿次运算)。这是一个衡量性能效率的指标,本质上意味着,在给定 X 个硬件峰值计算量的情况下,我们提供了最高的吞吐量性能。
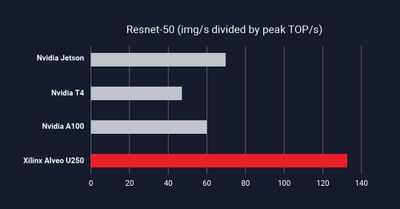
此外,MLPerf 的结果还显示,与我们在数据手册中公布的性能相比,我们实现了 100% 的可用 TOP/s。这一令人印象深刻的结果表明,纸面上的原始峰值 TOP/s 未必总能准确代表实际性能。我们的器件架构能够为 AI 应用提供更高效率(有效 TOP/s/峰值 TOP/s)。市场上的大多数厂商只能提供其峰值 TOPS 的一小部分,效率最高通常不超过 40%。最重要的是,ML 应用涉及的不仅仅是 AI 处理。它们通常需要 ML 预处理功能和后处理功能,这两者会竞争系统带宽,导致系统级瓶颈。我们的自适应平台的强大之处在于,它可以通过加速关键型非 AI 功能同时构建应用级数据流流水线来避免系统瓶颈,从而实现完整应用的加速。我们在保持 TensorFlow 和 Pytorch 框架可编程性(无需用户具备硬件专业知识)的同时,也取得了领先的成果。
MLPerf 正在迅速成为业界衡量 ML 性能的事实标准。这是 MLPerf Inference基准测试 (v0.7) 的第二个版本,它吸引了 1,200 多位同行来进行评审。对于需要图像分类和目标检测等计算机视觉任务的应用(例如自动驾驶和基于 AI 的视频监控)来说,ML 推断是一个快速增长的市场。这些复杂的计算工作负载需要不同级别的吞吐量、时延和功耗性能才能高效运行,这正是赛灵思和我们的自适应计算产品的强项所在。
MLPerf 基准测试结果彰显了我们的自适应计算器件为 AI 应用提供的高效吞吐量和低时延性能。我们为获得这些初步的 MLPerf 结果感到振奋,并期待参与下一个版本的测试。
进一步了解 MLPerf 推断基准测试套件以及 v0.7 版本测试结果,请访问:https://mlperf.org/press#mlperf-inference-v0.7-results。
文章来源: 赛灵思中文社区论坛