“要想 AI 不吃土,数据资源不可少”
然而数据资源不是你想要就能要的
随着各厂商对数据越来越重视
各国对个人信息的保护政策越来越完善
用户数据野蛮圈地的时代早已过去
但是
机器学习却又需要大量的优质数据来学习
肿么办?
快跟小编一起看看
最近比较火热的“联邦学习”吧
首先了解一下机器学习的原理
什么是机器学习?
简单来说,分为两步
第一步训练,通过大量优质的特征数据让模型学习如何完成工作。
第二步推断,就是深度学习把从训练中学习到的能力应用到工作中去。如果训练数据特征不够,那就尴尬了。
那是不是只要给到充足的数据
就能得到准确的模型了呢
No~No~No
愿望是美好的,而现实是残酷的
一般情况下
人工智能所需要的数据
涉及多个领域
同时数据源之间也存在着
难以打破的壁垒
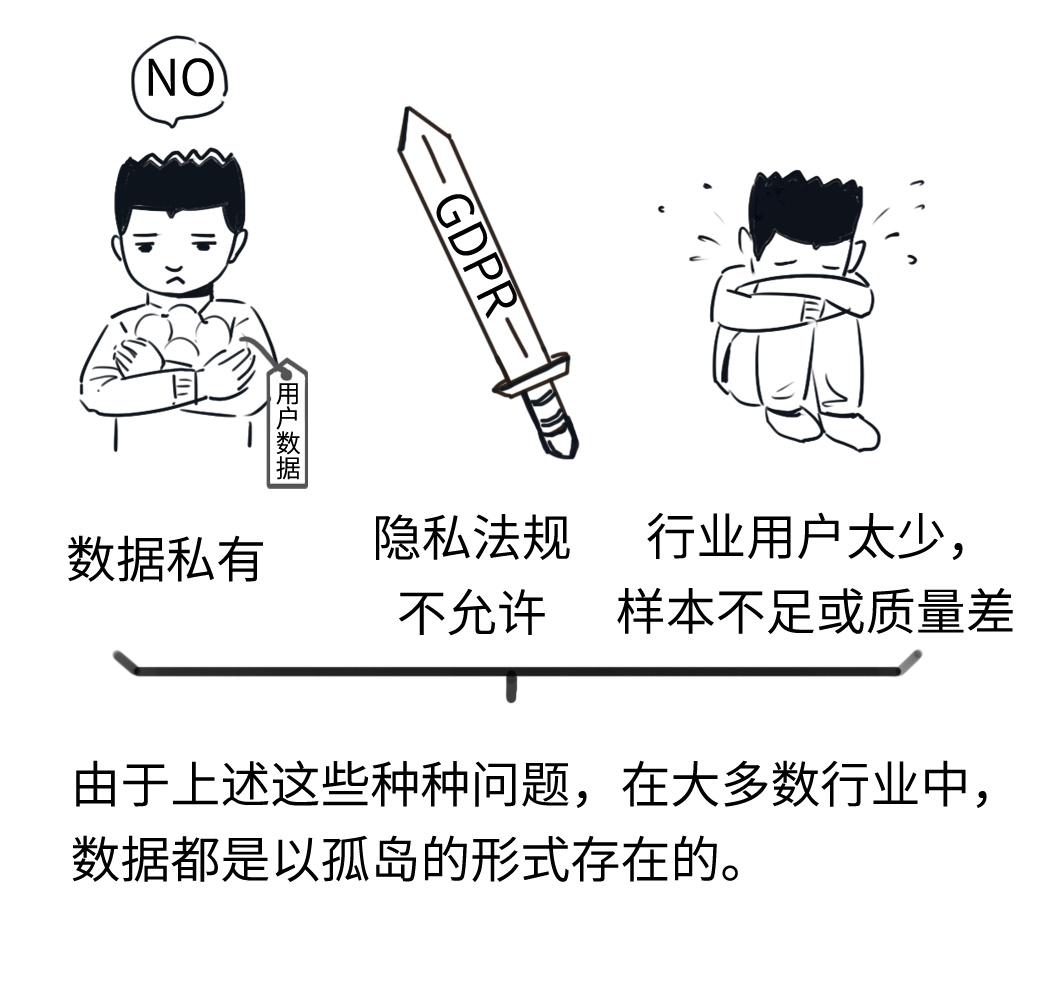


这就是“联邦学习方法”
什么是联邦学习?

具体来说,联邦学习基本可以分为以下几个步骤
Step1:用户 A、B、C 各自使用粗糙模型进行训练得到参数 Wi。
Step2:A、B、C 在本地对模型参数 Wi 进行加密得到[[Wi]]。
Step3:上传加密模型[[Wi]]。
Step4:关键来了!服务器采用同态加密算法整合各个加密模型。

Step5:将更新后的[[Wi]]下发到 ABC。
Step6:ABC 使用自己的密钥更新来自他那一部分的 Wi,得到一个更精确的算法模型。
升级完成!Well done。数据没动,但模型更精确了!
看到这里
是不是对联邦学习
充满了期待和更多的好奇呢
公开课时间:
12 月 17 日 | 10:00 – 11:00
主题:
FPGA 如何加速联邦学习高性能计算落地
介绍:
本次公开课将详细介绍联邦学习,以及针对联邦学习中存在的诸如同态加密、密态运算等复杂计算力问题,结合 FPGA 高并行、高定制、低延迟等特性,分享在联邦学习中具体的 FPGA 加速方案和成果,使得计算性能和效率大幅提升。
演讲嘉宾:

王玮现为星云 Clustar 硬件团队负责人
十年 FPGA 设计开发经验,一直专注于 FPGA 数据处理和加速相关领域,曾就职于阿里云,负责 FPGA 硬件加速产品商业落地,熟悉 FPGA 整体架构设计。现为星云 Clustar 硬件团队负责人,带领团队完成联邦学习 FPGA 加速等相关项目落地。

马鸿伟
现任赛灵思大中华区
加速及系统设计领域技术专家
马鸿伟,现任赛灵思大中华区加速及系统设计领域技术专家,负责赛灵思大中华区 Alveo 加速板卡推广及系统解决方案。在通信、加速应用领域从事 FPGA 开发和支持工作超过11年。
墙裂建议以下行业用户参与讨论,必定获益不浅!
● 金融
● 医疗
● 计算机视觉
● 自动驾驶汽车
● ……
欢迎所有想要进一步了解
联邦学习的童鞋
参加此次在线公开课
期待你的加入
扫码报名






