现在人工智能有着飞速的发展,而这很大程度上归功于现在硬件算力的飞速发展。当你有了深度学习算法、模型,并构建了深度神经网络时,需要足够多的数据去训练这个网络。庞大的数据就需要更强大的硬件支持。虽然我们可以不断增加处理器核心的数量,但是由于能耗限制,无法让它们同时工作。就好像一幢大楼里有很多房间,但由于功耗太大,你无法点亮每个房间的灯光。这种“暗硅”效应的本质原因是在后摩尔定律时代,晶体管的能效发展已经趋于停滞。
FPGA在人工智能领域,突破了“暗硅”为我们带来了更强大的可能性。然而FPGA的开发难度也成为了AI工程师面临的一大门槛。近年来Xilinx致力于将FPGA推广到各个领域的工程师手中,但FPGA在编译、部署难度上与传统的CPU+GPU架构有着较明显的提升。
现在依元素科技提供了一个完整的FPGA加速解决方案,让AI工程师能够以“即插即用”的方式部署 FPGA,AI 工程师隐藏了 FPGA,不需要硬件细节,让他们享受更快的执行。
FPGA加速解决方案–数据加速器卡
依元素科技现推出FPGA加速解决方案,是加速 FPGA 和自适应 SoC 的开发、部署的解决方案。在我们方案驱动下的赛灵思 Alveo U250 加速器卡,与所有其他商用加速器相比,实现了 2 倍以上的峰值性能效率。

Xilinx Alveo 数据中心加速器卡旨在满足现代数据中心不断变化的需求,为重要工作负载(包括机器学习推断、视频转码和数据库搜索与分析)提供比 CPU 高 90 倍的性能。
搭配我们完整的解决方案,使 Alveo数据中心加速卡 像 CPU 或 GPU 一样易于使用,用于深度学习推理加速。在我们方案下所驱动的 FPGA 比 GPU 更适合加速数据中心和大型工业 AI 应用程序的神经网络推理。
更优的机器学习推理效率
依元素科技现推出的FPGA加速方案中所驱动的Alveo U250 加速器卡在每 TOPS 的吞吐量方面明显优于竞争对手,并跻身当今可用的最佳加速器之列。基于 MLPerf v0.7 推理结果,它提供与 NVIDIA T4 相似的性能,同时其 TOPS 低 3.5 倍。换句话说,在与 GPU 相同数量的 TOPS 上,我们方案提供的吞吐量是 TPU v3 的 3.5 倍或 6.5 倍。
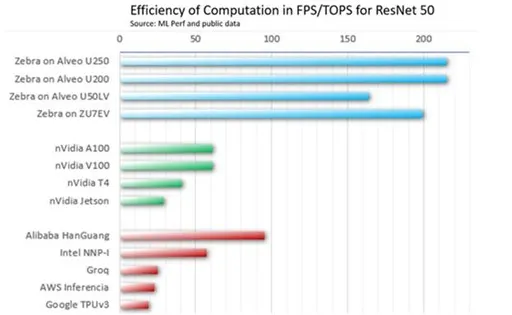
图1:基于 FPGA 的推理加速器在 MLPerf 基准测试对比
处理多种神经网络
我们的FPGA加速解决方案,基于Zebra软件经过验证的核心技术。它采用 TensorFlow、PyTorch 或 ONNX CNN 模型并将它们无缝映射到目标系统,同时不会牺牲边缘的准确性。由于可以处理多种神经网络,因此应用程序可以继续发展,而无需在低级别重新编程 FPGA。
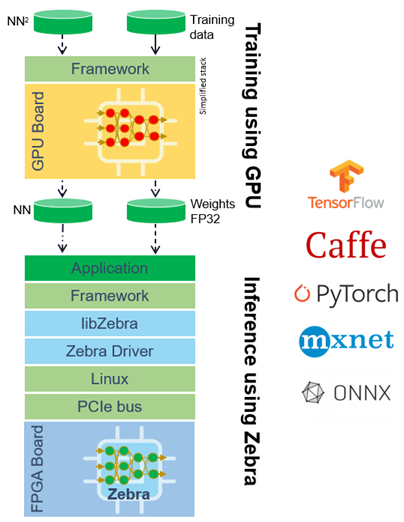
图2:人工智能运算加速解决方案堆栈图像
统一的开发方式
FPGA加速解决方案提供了统一的开发方式,能够帮助熟悉使用GPU开发的AI工程师快速转移到新的方案上来。相近的流程大大降低了移植时候的学习成本,具有与我们在 GPU卡上运行推理加速器相似的特性和行为,但格式更加灵活,因此开发人员可以通过附加功能增强他们的系统。
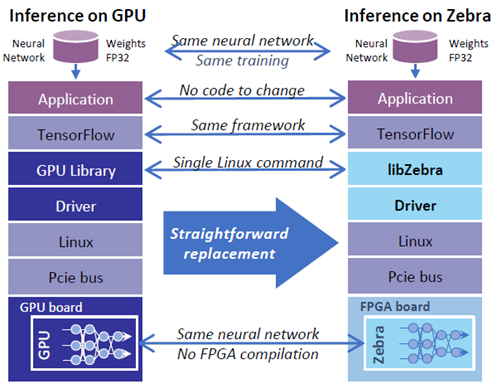
图3:人工智能运算加速解决方案与GPU开发方案对比
文章来源:依元素科技





