今年 CVPR 上,赛灵思 AI 研发团队实现了学术与实践“两开花”(点击深入了解赛灵思 AI 研发团队的“双引擎”发展)。近日,在另一个计算机视觉顶级学术会议 ICCV 上,赛灵思 AI 研发团队再次成功入选两篇论文:
作为一支坚持前沿研究与客户需求双驱动的团队,赛灵思 AI 研发算法团队的研究领域覆盖应用算法优化,以及面向不同硬件平台的算法设计。本次 ICCV 录取的两篇论文就是这支团队在此领域收获的果实。学术论文的成功发表不仅是团队技术实力和创新力的证明,与此同时,借助这些研究产出,团队也能够更好地服务于客户,助力客户打造更具内核竞争力的产品、更加卓越的智能方案。
通过Bin正则化提升低比特网络量化精度
论文第一作者:韩田甜,赛灵思资深算法专家

模型量化作为一种重要的神经网络加速方法,已经广泛应用于各种资源受限的硬件部署上。尽管 8-bit 量化可以一定程度上实现模型加速,然而,随着开发的神经网络模型越来越大,实际模型加速仍然面临着严峻挑战。为了进一步降低模型复杂度,低比特模型(<=4bits)优化被提出,但是这些低比特模型优化方法面临着精度下降严重的问题。
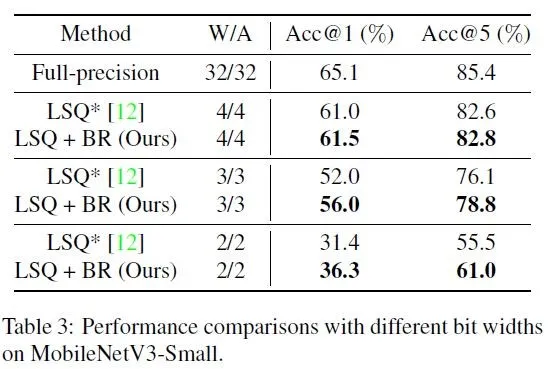
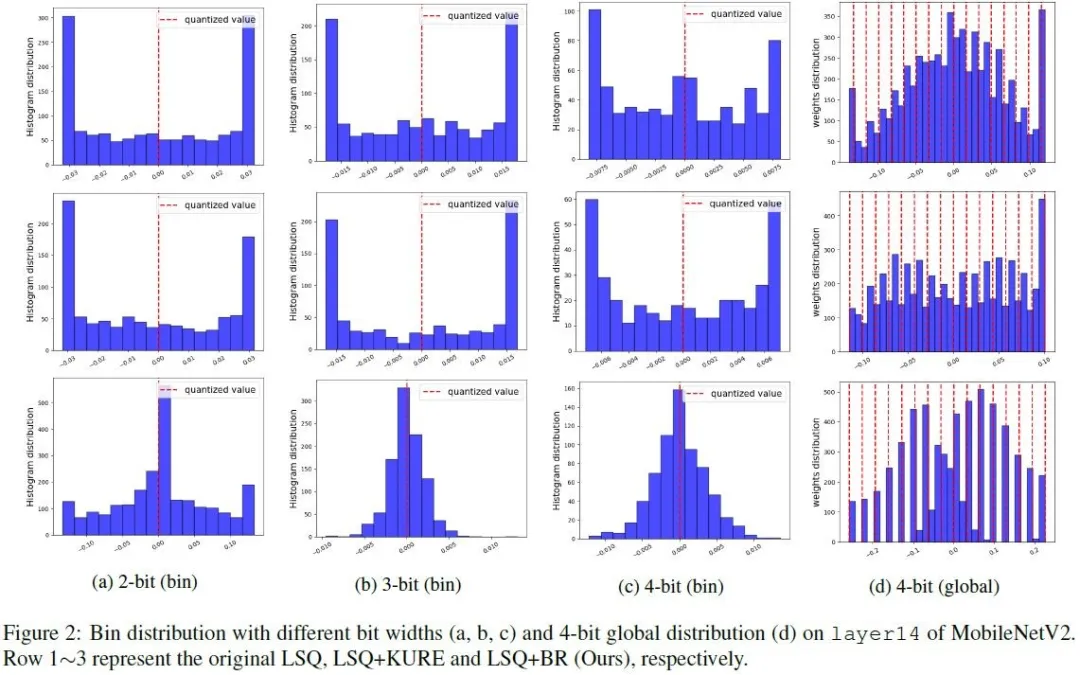
本论文针对该问题提出了一种新的权重正则化方法,以进一步提升低比特模型的量化精度。这种正则化方法分别优化每个量化bin中的所有数据,使其尽可能接近目标量化值,从而促使每个量化 bin 的权重分布尖锐并尽可能接近 Dirac delta 分布。实验表明,这种方法对于不同网络结构( ResNet、MobileNetV2、MobileNetV3 )、不同低比特带宽(4/3/2比特)均能提升量化精度。例如,在 ImageNet 基准分类任务上,将 MobileNetV3-Small 量化至2比特,这种方法相比当前的SOTA 算法-LSQ提高了4.9%的 top-1识别精度。

这种方法的独特价值在于:
1.所提方法在主流图像分类数据集ImageNet上,基于不同网络结构和比特带宽进行了有效性验证。相比于已有的量化训练算法获得了新的最佳性能。
2.相比于已有优化整体数据分布的量化方法,创新性地提出优化每个量化bin的策略,并探索了不同训练策略对量化结果的影响,对于其他量化优化算法有一定的启发意义。
3.可以很容易集成到现有低比特优化算法上,从而进一步提升现有低比特优化算法的模型量化精度。
4. 不会给低比特模型部署带来额外开销。
5. 在极低比特(2 bits)的量化上具有显著的精度提升,为未来更低比特的模型加速和部署提供了新的实验依据。
面向无监督行人再识别的判别表示学习
论文第一作者:Takashi Isobe,赛灵思算法实习生

行人再识别是智能监控和智慧城市中的重要任务,主要目的是在跨摄像头中识别同一个行人身份。有监督行人再识别通常需要耗时耗力的数据标注,很大程度上限制了模型的可扩展性。例如,当把一个在某个场景有监督预训练的模型直接应用在一个新场景时,识别效果往往大打折扣。因此,无监督域适应下的行人再识别应运而生,可以应对新场景没有数据标签的问题。
已有方法通常采用一种两阶段的训练方式:先在有标签的源域上预训练,再在无标签的目标域上利用数据聚类得到的伪标签进行微调训练。这种两阶段训练方式存在两个主要问题:(1)伪标签的噪声会阻碍学习得到足够有判别力的特征去识别目标域样本;(2)域差异(domain gap)会阻碍源域到目标域的知识迁移。
为此,这种方法提出了三种技术手段:
1.基于聚类的对比学习算法
(cluster-wise contrastive learning)
2.渐进式域适应算法
(progressive domain adaptation)
3.傅里叶增强学习算法
(Fourier augmentation)
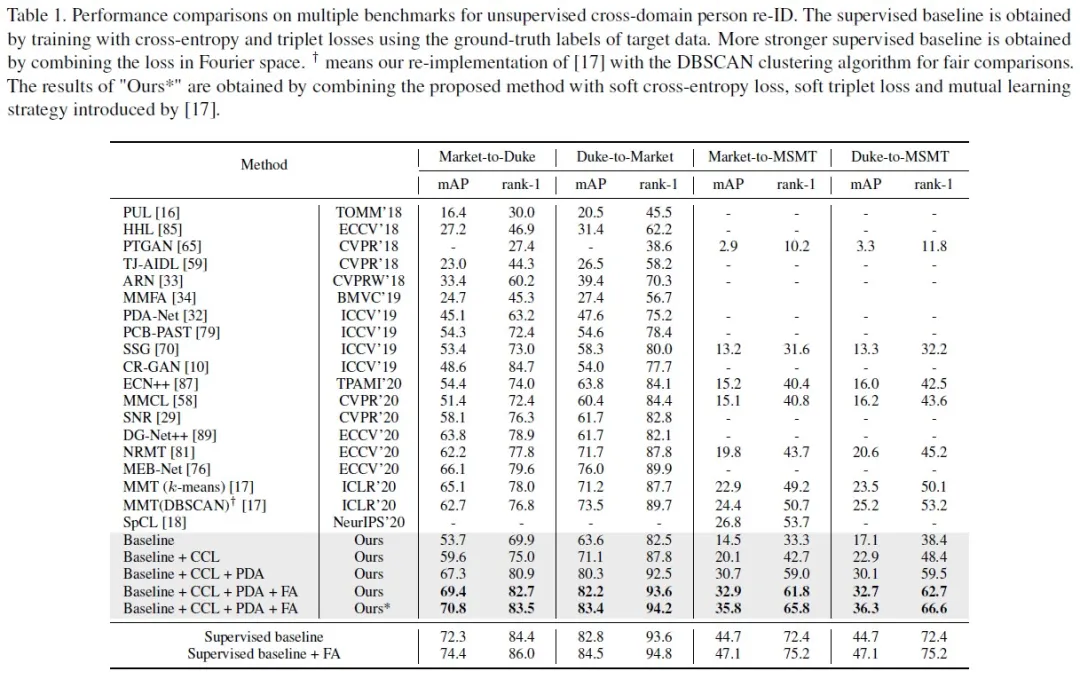
实验证明,这种方法在多个主流 benchmark 上刷新无监督行人再识别的最好性能。例如,在 Market-to-Duke、Duke-to-Market、Market-to-MSMT和Duke-to-MSMT 四个 benchmark 上分别超越 MMT 方法 8.1%、 9.9%、11.4%和11.1% mAP。

这种方法的独特价值在于:
1. 相比于已有的基于 instance-level 信息的自监督对比学习算法,基于聚类的对比学习算法(cluster-wise contrastive learning)采用迭代式地数据聚类和网络训练,能够在无标注的目标域上极大地减少聚类产生的伪标签噪声。
2. 相比于传统两阶段的域适应训练方式,我们提出一种渐进式域适应算法(progressive domain adaptation),在训练过程中动态更新源域和目标域的样本权重来逐渐缓解域差异的问题,帮助源域到目标域更好地知识迁移。
3. 相比于大多数方法只在空域进行特征提取和学习,我们创新性地提出傅里叶增强学习算法(Fourier augmentation),在傅里叶域增加额外的训练约束,以进一步提升模型的判别力。
在实际应用层面,这种无监督域适应行人再识别方法,能够在没有新场景数据标注信息情况下学习得到具有足够判别力的模型,识别精度远远高于其他已有无监督算法,并且能够应用到其他再识别任务(比如 Vehicle re-ID),以及从合成数据迁移到真实数据的域适应问题。
10 月 11 日至 17 日,ICCV 2021 将于线上举行。届时,赛灵思 AI 研发团队的论文将在会上进行展示。更多信息,请密切关注 ICCV 官网。
ICCV 简介
ICCV即国际计算机视觉大会,由IEEE主办,与CVPR、ECCV 并称计算机视觉方向三大顶级会议。ICCV 于 1987 年在伦敦首次举办,此后每两年举办一次。上届 ICCV 于韩国首尔举办;2005 年于北京举办。ICCV 是计算机视觉领域最高级别的学术会议,代表了最新发展方向和最高研究水平。和 CVPR 一样,ICCV 的论文接收率也较低。2021 年,ICCV 共收到论文 6236 篇、接收论文 1617 篇,接收率仅为 25.9%。





