本文转载自: XILINX开发者社区
概述:
众所周知,将受过良好训练的神经网络模型成功部署到 AI 推理硬件上,需要花费一定的时间,采用 Vitis AI 在 FPGA 上部署的情况也一样。实际因素之一是真实的神经网络模型在结构或算子的设计上极为不同,这导致了同一个网络模型的不同部分不能被加速引擎完整加速的问题。一般情况下,我们针对 DPU 或CPU 处理器将模型划分为多个子图,但是用户需要逐一部署这些子图,这种手动部署流程增大了在 FPGA 和ACAP上部署神经网络模型的难度。
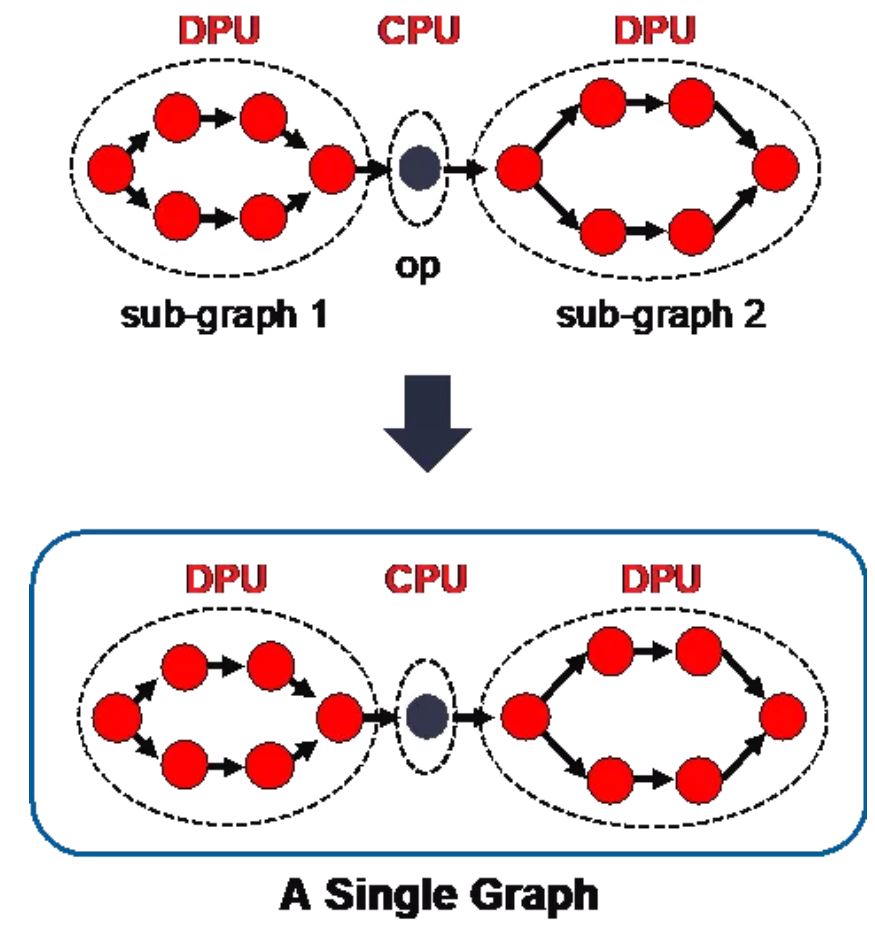
在今年7月发布的 Vitis AI 1.4 版中,赛灵思推出了一套全新的软件 API graph runner。其设计目的是将多个模型转换成单图,简化多子图模型的部署工作。
在当前的 Vitis AI 框架下,在 FPGA 或 ACAP 平台上部署 Tensorflow、PyTorch 或 Caffe 模型通常需要三个主要步骤:
步骤 1:模型量化,即将浮点格式的模型转换成 INT8 格式
步骤 2:将量化后的模型编译成 XIR 图形,这是一种将模型转化为计算图形的通用表达
步骤 3:调用 VART(Vitis AI 运行时)API,运行 XIR 图形
本文将重点讲解如何调用 VART API 以运行 XIR 图形。同时,假设我们在处理程序内已有XIR 图形,我们将了解到如何创建runner以及如何在编译流程中启动 graph runner。有关量化和编译的更多信息,请访问如下链接参阅 Vitis AI 工具: https://github.com/Xilinx/Vitis-AI/tree/master/tools
XIR 图形简介
XIR 图是计算有向非循环图 (DAG) 的简单表达,其中的节点代表运算,如 XIR Op、Conv2d、Reshape、Concatenation 等。一个 XIR Op 仅输出一个 XIR Tensor,输入一个或多个 XIR Tensor。Xcompiler(请访问如下链接参阅 Vitis AI 编译器)将部分 XIR Op 标记为图形输入,部分 XIR Op 标记为图形输出。
https://www.xilinx.com/html_docs/vitis_ai/1_4/compiling_model.html#ztl15...
一个 XIR 图形会被分割成众多子图,每个子图有对应的 runner,用于在特定处理器(如 DPU、CPU 或其他处理器)上运行该子图。如果没有graph runner API,最终用户必须创建这些 runner 并手动连接 runner 之间的输出和输入。这一流程容易发生错误。而使用 graph runner API 后,最终用户只需关注整个图形的输入和输出。
为方便使用,赛灵思专门将graph runner API 设计成与子图 subgraph runner 相同的API, 它们共享同一个 API 接口,即:
vart::Runner or vart::RunnerExt which is an extension of vart::Runner
示例
我们以 resnet50.xmodel 为例,展示如何在目标板卡上部署该模型。具体包括如下步骤:
我们可以使用 XIR API加载 xmodel 文件:
xir::Graph::deserialize
auto g_xmodel_file = std::string("/usr/share/vitis_ai_library/models/resnet50/resnet50.xmodel")
auto graph = xir::Graph::deserialize(g_xmodel_file);我们可以使用其中一个 Vitis AI API库创建runner:
vitis::ai::GraphRunner::create_graph_runner
auto attrs = xir::Attrs::create();
auto runner =
vitis::ai::GraphRunner::create_graph_runner(graph.get(), attrs.get());attrs尚未使用。
我们需要使用 VART API以填充输入,
vart::RunnerExt::get_inputs()
如上所述,它返回与 Xcompiler 标记输出XIP Op 所关联的输入 tensor buffer。
std::vector<vart::TensorBuffer*>inputs = runner->get_inputs();
对于 resnet50.xmodel,我们只有一个输入 tensor buffer:
auto tensor_buffer= inputs[0];
auto batch_size = inputs[0]->get_tensor()->get_shape()[0];
uint64_t data;
size_t data;
for(auto batch = 0; batch < batch_size; ++ batch) {
std::tie(data, size) = tensor_buffer->data({batch, 0, 0, 0});
// read input from file
...
}一个输入的 tensor buffer由多个连续的memory区域构成,一个区域与一个batch的一张输入图像对应,这样我们需要逐个读取这个图像并填充输入。
如果输入图像的数量小于batch size,我们必须构建新的tensor buffer用于更小批量。但我们并不推荐这种方法,因为 DPU 资源不会被充分利用。
我们可以按如下方式从输入文件读取数据:
std::ifstream(filename).read((char*)data, size).good()
我们可按如下方式启动graph runner:
//sync input tensor buffers
for (auto& input : inputs) {
input->sync_for_write(0, input->get_tensor()->get_data_size() /
input->get_tensor()->get_shape()[0]);
}
//run graph runner
auto v = runner->execute_async(inputs, outputs);
auto status = runner->wait((int)v.first, -1);
CHECK_EQ(status, 0) << "failed to run the graph";
//sync output tensor buffers
for (auto output : outputs) {
output->sync_for_read(0, output->get_tensor()->get_data_size() /
output->get_tensor()->get_shape()[0]);
}缓存的同步至关重要,例如在 execute_async 之前和之后同步,这是由于执行时有可能通过硬件zero-copy支持预处理和后处理,这种情况下同步会变得没有必要。
与填充输入 tensor buffer相似,我们可以按如下方式读取和处理输出 tensor buffer:
auto tensor_buffer= outputs[0];
auto batch_size = outputs[0]->get_tensor()->get_shape()[0];
uint64_t data;
size_t data;
for(auto batch = 0; batch < batch_size; ++ batch) {
std::tie(data, size) = tensor_buffer->data({batch, 0, 0, 0});
std::ofstream(filename).write((char*)data, size).good();
}请注意,输出 tensor buffer是没有排序的,我们需要根据名称仔细找到正确的输出tensor buffer,即:
tensor_buffer->get_tensor()->get_name()
结论
通过上面的介绍,我们了解到 graph runner 的功能是将模型转换成单个图形,大幅简化有多个子图的模型的部署工作。过去用户需要为每个子图创建 DPU runner,手动完成对 DPU 和 CPU 的大量输入输出连接以及部署。现在 graph runner 将所有子图转换成单个图形,显著简化 Vitis AI 的部署流程。
本文作者:
郭冰清
赛灵思软件与 AI 产品市场经理,从事多年 AI 加速解决方案市场营销。受益于她对市场的了解和有效的推广策略,越来越多的用户开始在他们的产品开发中使用赛灵思 Vitis AI,并认可 Vitis AI 为其产品性能带来的提升。
王纯业
赛灵思事业部首席软件工程师,从事软件开发工作超过 15 年,现在他负责领导 Vitis AI 软件 API 开发。身为核心的软件开发工程师,他为改进 Vitis AI 的易用性做出了大量贡献且始终对软件开发保持不变的热情。