北京时间今天凌晨,第三十六届 AAAI 大会( Association for the Advancement of Artificial Intelligence )正式在线上开幕。本届 AAAI 大会上,AMD-赛灵思 AI 团队的论文《Cross-Dataset Collaborative Learning for Semantic Segmentation in Autonomous Driving 》(跨数据集协同学习用于自动驾驶中的语义分割)成功入选。这是继去年 CVPR、ICCV之后,该再次在行业顶会中获得认可。
作为人工智能领域的综合性顶会之一,AAAI 关注机器学习、自然语言处理、计算机视觉、数据挖掘等多个研究领域。要知道,AAAI 大会对论文的评审是十分严格的。所有提交的论文不仅要经历两轮会议评审,而且最终能够入选的论文数量非常有限。今年, AAAI 大会官方收到了创纪录的 9,251 份论文提交,最终接受了1,349 篇论文,总体论文接受率仅为15%。
AMD-赛灵思 AI 团队的论文能在激烈竞争中突出重围,其中一定蕴含着独特的创新与价值。我们与论文第一作者、AMD-赛灵思 AI 团队算法工程师王莉深度对话,为大家带来这份独家的论文解析。
下面是王莉的自述。

王莉,AMD-赛灵思 AI 团队算法工程师
跨数据集协同学习
一种简单、灵活且通用的语义分割方法
在这篇论文中,我们针对自动驾驶领域中的语义分割任务,探究了目前相关工作的局限性——专注于设计网络结构来提升单个目标数据集的精度。为了解决上述问题,我们研究了如何利用多个数据集协同训练,从而提升单个模型在多个数据集上的泛化能力。这就是我们在论文中提出的跨数据集协同学习。
我们的目标是训练一个统一的模型,利用多个数据集的综合信息来提高网络的泛化性,进而在各个数据集上达到满意的性能。
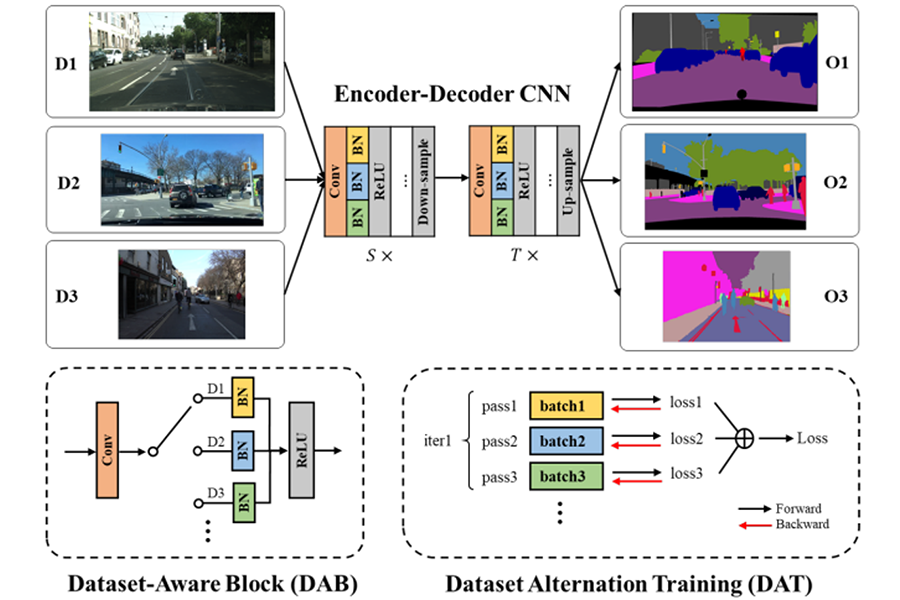
首先,我们引入了一系列数据集感知块( Dataset-Aware Block, DAB )作为网络的基本计算单元,它们有助于捕获跨不同数据集的同构卷积参数和数据集感知的统计分布。
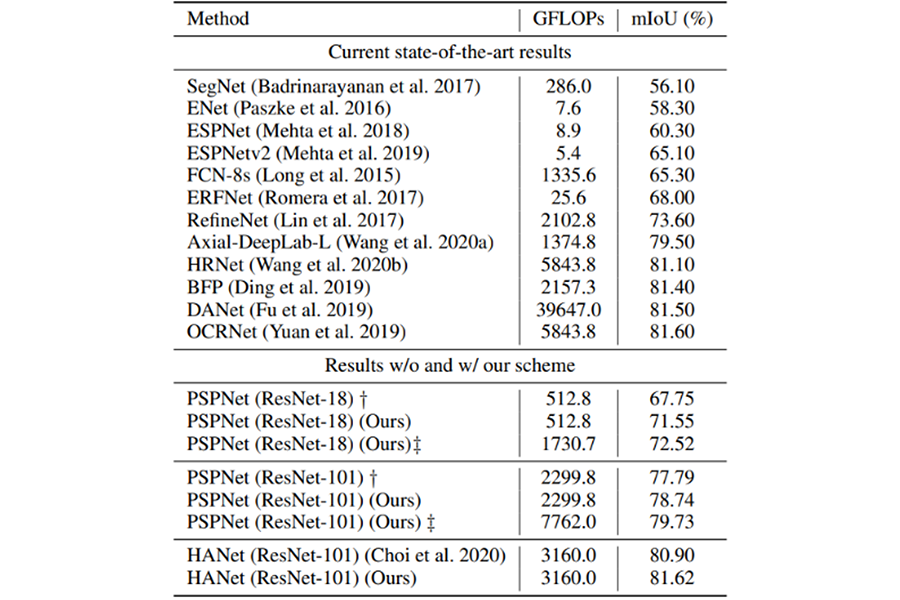
其次,我们提出了一种数据集交替训练(Dataset-Alternation Training, DAT )机制来促进多数据集协同优化过程。我们对自动驾驶的多个语义分割数据集进行了评估,在不引入额外 FLOPs 的情况下,我们的方法比目前的单数据集方法取得了显著的提升。
例如,基于PSPNet (ResNet-18) 的分割算法,我们的方法在 Cityscapes、BDD100K、CamVid 三个公开数据集的验证集上比单数据集基线分别提升了5.65%、6.57% 和 5.79%。同时,我们还将 CDCL 应用于3D点云语义分割任务,进一步验证了我们方法的通用性。

长期关注+持续探索+新方向=全新算法
新的算法支持多个数据集协同训练,而且无需算力开销即可带来稳定的数据集精度提升
自动驾驶中的语义分割任务是我们长期关注的领域,而我们也看到了其中存在的诸多局限性。
首先,目前的分割算法主要通过设计不同复杂度的网络结构来提升目标数据集上的精度。针对多个数据集,该类算法需要保存多组网络,每个网络只负责其对应的数据集,未考虑多个数据集之间的关系。
其次,在处理多个数据集分布差异并提高目标数据集准确性方面,基于微调( Finetuning )的方法是最直接的解决方案,却需要丰富的经验去设置一些超参数,而且两阶段式的训练方式会带来额外的训练开销。另外一种利用多数据集训练的方式是标签重映射( label remapping ),该方法同样存在缺点。
我们的研究方向与上述方法不同。我们观察到,分割网络中BN的统计参数是可以直接反应数据分布的差异性,而Conv是数据集可共享的。因此,我们引入了数据集感知块( DAB )作为网络的基础计算单元,它有助于捕获跨不同数据集的同构Conv和异构BN统计分布。此外,我们提出了一种数据集交替训练( DAT )机制来促进协同优化过程。
简而言之,我们提出的算法不仅支持多个数据集协同训练,而且在模型推理过程中无需引入额外的算力开销,即可让各个数据集上精度得到稳定提升。
为自动驾驶节约数据采集标注成本
在我们看来,针对多个数据集的语义分割任务,目前算法往往需要分别采集各个目标场景的数据集对模型进行精调,而像素级别的标注是很耗时耗力的。我们的方法在不需要额外标注数据集的前提下,可以有效利用公开数据集提升网络的泛化能力。这样一来,就能在不增加额外资源开销的前提下,使单个模型在多个目标场景上均能获得满意的效果。同时,这种方法在零样本的场景上也可以达到较好的精度。
在未来,这一方法可以应用到自动驾驶场景中。针对不同的驾驶场景,我们不需要分别采集和标注对应场景下的数据集来训练多个模型参数来。采用本文的算法可以直接利用公开的带标注的自动驾驶场景的数据集训练得到统一的模型,使得在多个场景上均得到较好的结果。这种方法既节省了数据采集标注的成本,也提高了算法的实用性。
AMD-赛灵思人工智能算法研发总监田露表示:“自动驾驶的出现正推动社会迈入新纪元。近年来,随着海量数据产生和深度学习算法的成熟,人工智能在 ADAS和自动驾驶的应用成为大势所趋。高层的计算机视觉任务,如目标检测、语义分割,在自动驾驶的感知中扮演着重要角色。这篇文章以语义分割为切入点分析了目前研究方法的缺点,进而提出一种简单有效的多数据集协同训练方法,可以有效缓解人工智能在实际落地过程中的困难,进而提升算法的实用价值。”
目前,论文第一作者、AMD-赛灵思 AI 团队算法工程师王莉针对论文的讲解已登录线上。在演讲中,王莉深度阐述了核心研究及相关算法。您可以点击链接观看。
注:赛灵思现在是 AMD 的一部分