跳转到主要内容
FPGA 开发圈
Toggle navigation
新闻
视频
技术文章
博客
下载中心
活动
登录
注册
新闻
AMD GPU,将开源
AMD 表示,它有望在 5 月底发布其微引擎调度程序 (MES) 文档,随后发布源代码。然后,它将继续以开源方式发布 Radeon 堆栈的其他部分
2024-04-23 |
AMD
,
GPU
AMD加持研华AIMB-723工业级主板,着眼未来AOI应用
本文将讨论Advantech如何帮助客户利用AOI生产PCB和IC。重点介绍研华的由AMD驱动的AIMB-723工业级主板的新能力
2024-04-22 |
AMD
,
AIMB-723
,
AOI
,
研华科技
谁是Chiplet的最优解?
半导体行业正在准备从基于专有小芯片的系统向更加开放的小芯片生态系统迁移
2024-04-22 |
Chiplet
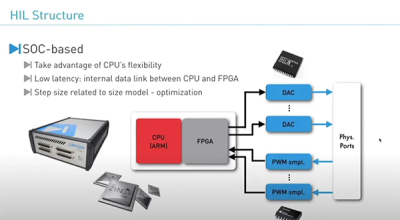
瑞苏盈科FPGA核心板在实时仿真与测试(HIL)中的应用
RT Box 1中使用的Mercury ZX5采用AMD Xilinx® Zynq® 7015/7030 SoC器件,配备ARM®双核Cortex™-A9处理器
2024-04-19 |
瑞苏盈科
,
FPGA
,
硬件在环测试
,
Plexim
走进北汽研究总院,芯驿电子 AUMO 亮相创新技术展
AUMO展示了多款智驾仿真测试、电子后视镜CMS产品及解决方案,包括自动驾驶硬件在环仿真HIL、12通道HDMI视频注入系统
2024-04-19 |
芯驿电子
,
AUMO
FPGA,被RISC-V完全征服
不知不觉中,FPGA 的 MCU 市场已经成为 100% 基于 RISC-V 的市场,我们也在逐步进入应用处理器市场
2024-04-18 |
FPGA
,
RISC-V
第二代 AMD Versal™ 自适应 SoC 助力 AI 驱动型嵌入式系统实现单芯片智能性
AMD 第二代 Versal AI Edge 系列和第二代 Versal Prime 系列自适应 SoC 为 AI 驱动和经典的嵌入式系统提供了单芯片智能性实现性能
2024-04-18 |
AMD
,
Versal
,
AI
,
每日头条
AMD 面向工业 AI 推出搭载集成 NPU 的锐龙嵌入式 8000 系列处理器
AMD 锐龙嵌入式 8000 系列处理器采用下一代 AMD “Zen 4” 4 纳米核心 CPU 架构,能提供多至 8 核心(16 线程)的强大 x86 CPU 算力
2024-04-18 |
AMD
,
AI
,
NPU
,
锐龙处理器
英特尔和Altera联合发布新芯片和FPGA以增强网络边缘AI
英特尔及其子公司Altera近日推出了一系列新的处理器,以及旨在将AI功能扩展到网络边缘的FPGA产品
2024-04-17 |
Altera
,
FPGA
,
AI
,
Agilex-5
AMD 联合 Vindral 推出全球首个超低延迟 8K 10bit HDR 直播演示
AMD 与 Vindral 合作,在拉斯维加斯的 NAB 展会上展示了全球首个具有超低延迟的 8K 10bit HDR 直播解决方案
2024-04-17 |
AMD
,
Vindral
,
Alveo-MA35D
,
8K
莱迪思助力汽车和工业应用实现功能安全
加强与NewTec的合作,专注于提供灵活、可扩展和易于实施的功能安全解决方案
2024-04-17 |
莱迪思
,
FPGA
,
NewTec
高云半导体再登德国纽伦堡国际嵌入式展EW2024
在本次展会上,高云展示了 Arora-V 系列高密度、高性能和低功耗 FPGA。该系列基于高度优化的 TSMC 22nm 工艺,提供了最低的功耗和最好的性能。
2024-04-16 |
高云半导体
,
EW2024
,
Arora-V
,
FPGA
Microchip收购Neuronix AI Labs
Microchip宣布收购 Neuronix AI Labs,以进一步增强在现场可编程门阵列(FPGA)上部署高能效人工智能边缘解决方案的能力。
2024-04-16 |
Microchip
,
Neuronix
,
人工智能
,
PolarFire
全国高校教师能力培养高级研讨会暨国产FPGA技术师资培训在成都顺利举办
本次会议旨在搭建一个电子信息类一流专业建设、新质课程建设的交流平台,以及通过深入研讨和交流,进一步推动电子信息类专业的高质量发展
2024-04-16 |
FPGA
,
师资培训
,
高云半导体
AMD向AI边缘计算开战,单芯片智能为嵌入式系统而生
继第一代Versal™ AI Edge自适应SoC之后,AMD又发布了第二代Versal™自适应SoC,为边缘计算打开了方便之门
2024-04-15 |
AMD
,
AI
,
边缘计算
,
Versal
1
2
3
…
下一页
末页