作者:Faizan Shaikh,翻译:李文婧,转自:数据派(ID:datapi)
引言
人类不会每听到一个句子就对语言进行重新理解。看到一篇文章时,我们会根据之前对这些词的理解来了解背景。我们将其定义为记忆力。
算法可以复制这种模式吗?神经网络(NN)是最先被想到的技术。但令人遗憾的是传统的神经网络还无法做到这一点。 举个例子,如果让传统的神经网络预测一个视频中接下来会发生什么,它很难有精确的结果。
这就是循环神经网络(RNN)发挥作用的地方。循环神经网络在深度学习领域非常热门,因此,学习循环神经网络势在必行。循环神经网络在现实生活中的一些实际应用:
在这篇文章中,我们首先对一个典型的循环神经网络模型的核心部分进行快速浏览。然后我们将设置问题陈述,最后我们将从零开始用Python构建一个循环神经网络模型解决这些问题陈述。
我们总是习惯用高级Python库编写循环神经网络。那为什么还要从零开始编码呢? 我坚信从头学习是学习和真正理解一个概念的最佳方式。这就是我将在本教程中展示的内容。
本文假设读者已对循环神经网络有基本的了解。如果您需要快速复习或希望学习循环神经网络的基础知识,我建议您先阅读下面两篇文章:
深度学习的基础知识
https://www.analyticsvidhya.com/blog/2016/03/introduction-deep-learning-...
循环神经网络简介
https://www.analyticsvidhya.com/blog/2017/12/introduction-to-recurrent-n...
目录
一、快速回顾:循环神经网络概念回顾
二、使用循环神经网络进行序列预测
三、使用Python构建循环神经网络模型
一、快速回顾:循环神经网络概念回顾
让我们快速回顾一下循环神经网络的核心概念。我们将以一家公司的股票的序列数据为例。一个简单的机器学习模型或人工神经网络可以根据一些特征预测股票价格,比如股票的数量,开盘价值等。除此之外,该股票在之前的几天和几个星期的表现也影响着股票价格。对交易者来说,这些历史数据实际上是进行预判的主要决定因素。
在传统的前馈神经网络中,所有测试用例都被认为是独立的。 在预测股价时,你能看出那不是一个合适的选择吗? 神经网络模型不会考虑之前的股票价格 – 这不是一个好想法!
面对时间敏感数据时,我们可以利用另一个概念 — 循环神经网络(RNN)!
典型的循环神经网络如下所示:

这刚开始看起来可能很吓人。 但是如果我们展开来讲,事情就开始变得更简单:

现在,我们更容易想象出这些循环神经网络如何预测股票价格的走势。这有助于我们预测当天的价格。这里,有关时间t(h_t)的每个预测都需要依赖先前所有的预测和从它们那学习到的信息。相当直截了当吧?
循环神经网络可以在很大程度上帮助我们解决序列处理问题。
文本是序列数据的另一个好例子。一旦给定文本之后,循环神经网络就可以预测出接下来将会出现的单词或短语,这可将是非常有用的资产。我们希望我们的循环神经网络可以写出莎士比亚的十四行诗!
现在,循环神经网络在涉及短或小的环境时非常棒。 但是为了能够构建一个故事并记住它,我们的循环神经网络模型应该能理解序列背后的背景,就像人脑一样。
二、使用循环神经网络进行序列预测
在本文中,我们将使用循环神经网络处理序列预测问题。对此最简单的例子之一是正弦波预测。序列包含可见趋势,使用启发式方式很容易解决。下面就是正弦波的样子:

我们首先从零开始设计一个循环神经网络解决这个问题。 我们的循环神经网络模型也应该得到很好地推广,以便我们可以将其应用于其他序列问题。 我们将像这样制定我们的问题:给定一个属于正弦波的50个数字的序列,预测系列中的第51个数字。 是时候打开你的Jupyter notebook(一个交互式笔记本,支持运行 40 多种编程语言)或你选择的IDE(Integrated Development Environment,是一种编程软件)!
三、使用Python编码循环神经网络
第0步:数据准备
在做任何其他事情之前,数据准备是任何数据科学项目中不可避免的第一步。我们的网络模型期望数据是什么样的? 它将输入长度为50的单个序列。所以输入数据的形状将是:
(number_of_records x length_of_sequence x types_of_sequences)
这里,types_of_sequence是1,因为我们只有一种类型的序列—正弦波。
另一方面,每次记录的输出只有一个值。那就是输入序列中的第51个值。 所以它的形状将是:
(number_of_records x types_of_sequences) #where types_of_sequences is 1
让我们深入研究这个代码。首先,导入必要的库:
%pylab inline
import math
创建像数据一样的正弦波,我们将使用Python数学库中的正弦函数:
sin_wave = np.array([math.sin(x) for x in np.arange(200)])
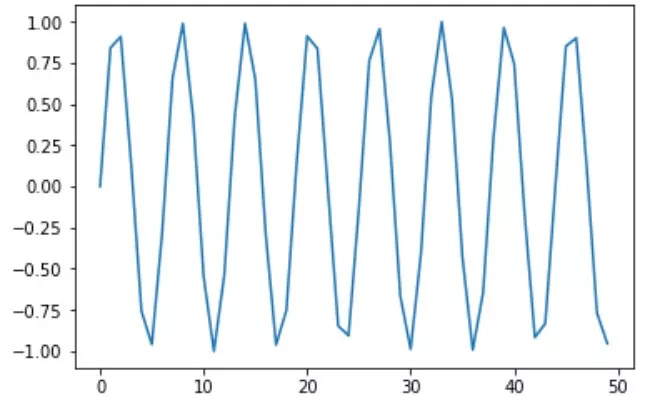
将刚刚生成的正弦波可视化:
plt.plot(sin_wave[:50])
我们现在将在下面的代码块中创建数据:
X = []
Y = []
seq_len = 50
num_records = len(sin_wave) - seq_len
for i in range(num_records - 50):
X.append(sin_wave[i:i+seq_len])
Y.append(sin_wave[i+seq_len])
X = np.array(X)
X = np.expand_dims(X, axis=2)
Y = np.array(Y)
Y = np.expand_dims(Y, axis=1)
打印数据的形状:
X.shape, Y.shape
((100, 50, 1), (100, 1))
请注意,我们循环(num_records - 50),是因为我们想要留出50条记录作为验证数据。现在我们可以创建这个验证数据:
X_val = []
Y_val = []
for i in range(num_records - 50, num_records):
X_val.append(sin_wave[i:i+seq_len])
Y_val.append(sin_wave[i+seq_len])
X_val = np.array(X_val)
X_val = np.expand_dims(X_val, axis=2)
Y_val = np.array(Y_val)
Y_val = np.expand_dims(Y_val, axis=1)
第1步:为我们的循环神经网络模型创建架构
我们接来下的任务是将我们在循环神经网络模型中使用的所有必要变量和函数进行定义。我们的循环神经网络模型将接受输入序列,通过100个单位的隐藏层处理它,并产生单值输出:
learning_rate = 0.0001
nepoch = 25
T = 50 # length of sequence
hidden_dim = 100
output_dim = 1
bptt_truncate = 5
min_clip_value = -10
max_clip_value = 10
然后我们将定义网络的权重:
U = np.random.uniform(0, 1, (hidden_dim, T))
W = np.random.uniform(0, 1, (hidden_dim, hidden_dim))
V = np.random.uniform(0, 1, (output_dim, hidden_dim))
其中:
U是输入和隐藏图层之间权重的权重矩阵
V是隐藏层和输出层之间权重的权重矩阵
W是循环神经网络层(隐藏层)中共享权重的权重矩阵
最后,我们将定义在隐藏层中使用S型函数:
def sigmoid(x):
return 1 / (1 + np.exp(-x))
第2步:训练模型
既然我们已经定义了模型,最后我们就可以继续训练我们的序列数据了。我们可以将训练过程细分为更小的步骤,即:
步骤2.1:检查训练数据是否丢失
步骤2.1.1:前馈传递
步骤2.1.2:计算误差
步骤2.2:检查验证数据是否丢失
步骤2.2.1前馈传递
步骤2.2.2:计算误差
步骤2.3:开始实际训练
步骤2.3.1:正推法
步骤2.3.2:反向传递误差
步骤2.3.3:更新权重
我们需要重复这些步骤直到数据收敛。 如果模型开始过拟合,请停止! 或者只是预先定义epoch的数量。
步骤2.1:检查训练数据是否丢失
我们将通过我们的循环神经网络模型进行正推法,并计算所有记录的预测的平方误差,以获得损失值。
for epoch in range(nepoch):
# check loss on train
loss = 0.0
# do a forward pass to get prediction
for i in range(Y.shape[0]):
x, y = X[i], Y[i] # get input, output values of each record
prev_s = np.zeros((hidden_dim, 1)) # here, prev-s is the value of the previous activation of hidden layer; which is initialized as all zeroes
for t in range(T):
new_input = np.zeros(x.shape) # we then do a forward pass for every timestep in the sequence
new_input[t] = x[t] # for this, we define a single input for that timestep
mulu = np.dot(U, new_input)
mulw = np.dot(W, prev_s)
add = mulw + mulu
s = sigmoid(add)
mulv = np.dot(V, s)
prev_s = s
# calculate error
loss_per_record = (y - mulv)**2 / 2
loss += loss_per_record
loss = loss / float(y.shape[0])
步骤2.2:检查验证数据是否丢失
我们将对计算验证数据的损失做同样的事情(在同一循环中):
# check loss on val
val_loss = 0.0
for i in range(Y_val.shape[0]):
x, y = X_val[i], Y_val[i]
prev_s = np.zeros((hidden_dim, 1))
for t in range(T):
new_input = np.zeros(x.shape)
new_input[t] = x[t]
mulu = np.dot(U, new_input)
mulw = np.dot(W, prev_s)
add = mulw + mulu
s = sigmoid(add)
mulv = np.dot(V, s)
prev_s = s
loss_per_record = (y - mulv)**2 / 2
val_loss += loss_per_record
val_loss = val_loss / float(y.shape[0])
print('Epoch: ', epoch + 1, ', Loss: ', loss, ', Val Loss: ', val_loss)
你应该会得到以下输出:
Epoch: 1 , Loss: [[101185.61756671]] , Val Loss: [[50591.0340148]]
...
...
步骤2.3:开始实际训练
现在我们开始对网络进行实际训练。在这里,我们首先进行正推法计算误差,然后使用逆推法来计算梯度并更新它们。让我逐步向您展示这些内容,以便您可以直观地了解它的工作原理。
步骤2.3.1:正推法
正推法步骤如下:
1. 我们首先将输入与输入和隐藏层之间的权重相乘;
2. 在循环神经网络层中添加权重乘以此项,这是因为我们希望获取前一个时间步的内容;
3. 通过sigmoid 激活函数将其与隐藏层和输出层之间的权重相乘;
4. 在输出层,我们对数值进行线性激活,因此我们不会通过激活层传递数值;
5. 在字典中保存当前图层的状态以及上一个时间步的状态。
这是执行正推法的代码(请注意,它是上述循环的继续):
# train model
for i in range(Y.shape[0]):
x, y = X[i], Y[i]
layers = []
prev_s = np.zeros((hidden_dim, 1))
dU = np.zeros(U.shape)
dV = np.zeros(V.shape)
dW = np.zeros(W.shape)
dU_t = np.zeros(U.shape)
dV_t = np.zeros(V.shape)
dW_t = np.zeros(W.shape)
dU_i = np.zeros(U.shape)
dW_i = np.zeros(W.shape)
# forward pass
for t in range(T):
new_input = np.zeros(x.shape)
new_input[t] = x[t]
mulu = np.dot(U, new_input)
mulw = np.dot(W, prev_s)
add = mulw + mulu
s = sigmoid(add)
mulv = np.dot(V, s)
layers.append({'s':s, 'prev_s':prev_s})
prev_s = s
步骤2.3.2:反向传播误差
在前向传播步骤之后,我们计算每一层的梯度,并反向传播误差。 我们将使用截断反向传播时间(TBPTT),而不是vanilla backprop(反向传播的非直观效应的一个例子)。这可能听起来很复杂但实际上非常直接。
BPTT与backprop的核心差异在于,循环神经网络层中的所有时间步骤,都进行了反向传播步骤。 因此,如果我们的序列长度为50,我们将反向传播当前时间步之前的所有时间步长。
如果你猜对了,那么BPTT在计算上看起来非常昂贵。 因此,我们不是反向传播所有先前的时间步,而是反向传播直到x时间步以节省计算能力。考虑这在概念上类似于随机梯度下降,我们包括一批数据点而不是所有数据点。
以下是反向传播误差的代码:
# derivative of pred
dmulv = (mulv - y)
# backward pass
for t in range(T):
dV_t = np.dot(dmulv, np.transpose(layers[t]['s']))
dsv = np.dot(np.transpose(V), dmulv)
ds = dsv
dadd = add * (1 - add) * ds
dmulw = dadd * np.ones_like(mulw)
dprev_s = np.dot(np.transpose(W), dmulw)
for i in range(t-1, max(-1, t-bptt_truncate-1), -1):
ds = dsv + dprev_s
dadd = add * (1 - add) * ds
dmulw = dadd * np.ones_like(mulw)
dmulu = dadd * np.ones_like(mulu)
dW_i = np.dot(W, layers[t]['prev_s'])
dprev_s = np.dot(np.transpose(W), dmulw)
new_input = np.zeros(x.shape)
new_input[t] = x[t]
dU_i = np.dot(U, new_input)
dx = np.dot(np.transpose(U), dmulu)
dU_t += dU_i
dW_t += dW_i
dV += dV_t
dU += dU_t
dW += dW_t
步骤2.3.3:更新权重
最后,我们使用计算的权重梯度更新权重。 有一件事我们必须记住,如果不对它们进行检查,梯度往往会爆炸。这是训练神经网络的一个基本问题,称为梯度爆炸问题。 所以我们必须将它们夹在一个范围内,这样它们就不会增长得太快。 我们可以这样做:
if dU.max() > max_clip_value:
dU[dU > max_clip_value] = max_clip_value
if dV.max() > max_clip_value:
dV[dV > max_clip_value] = max_clip_value
if dW.max() > max_clip_value:
dW[dW > max_clip_value] = max_clip_value
if dU.min() < min_clip_value:
dU[dU < min_clip_value] = min_clip_value
if dV.min() < min_clip_value:
dV[dV < min_clip_value] = min_clip_value
if dW.min() < min_clip_value:
dW[dW < min_clip_value] = min_clip_value
# update
U -= learning_rate * dU
V -= learning_rate * dV
W -= learning_rate * dW
在训练上述模型时,我们得到了这个输出:
Epoch: 1 , Loss: [[101185.61756671]] , Val Loss: [[50591.0340148]]
Epoch: 2 , Loss: [[61205.46869629]] , Val Loss: [[30601.34535365]]
Epoch: 3 , Loss: [[31225.3198258]] , Val Loss: [[15611.65669247]]
Epoch: 4 , Loss: [[11245.17049551]] , Val Loss: [[5621.96780111]]
Epoch: 5 , Loss: [[1264.5157739]] , Val Loss: [[632.02563908]]
Epoch: 6 , Loss: [[20.15654115]] , Val Loss: [[10.05477285]]
Epoch: 7 , Loss: [[17.13622839]] , Val Loss: [[8.55190426]]
Epoch: 8 , Loss: [[17.38870495]] , Val Loss: [[8.68196484]]
Epoch: 9 , Loss: [[17.181681]] , Val Loss: [[8.57837827]]
Epoch: 10 , Loss: [[17.31275313]] , Val Loss: [[8.64199652]]
Epoch: 11 , Loss: [[17.12960034]] , Val Loss: [[8.54768294]]
Epoch: 12 , Loss: [[17.09020065]] , Val Loss: [[8.52993502]]
Epoch: 13 , Loss: [[17.17370113]] , Val Loss: [[8.57517454]]
Epoch: 14 , Loss: [[17.04906914]] , Val Loss: [[8.50658127]]
Epoch: 15 , Loss: [[16.96420184]] , Val Loss: [[8.46794248]]
Epoch: 16 , Loss: [[17.017519]] , Val Loss: [[8.49241316]]
Epoch: 17 , Loss: [[16.94199493]] , Val Loss: [[8.45748739]]
Epoch: 18 , Loss: [[16.99796892]] , Val Loss: [[8.48242177]]
Epoch: 19 , Loss: [[17.24817035]] , Val Loss: [[8.6126231]]
Epoch: 20 , Loss: [[17.00844599]] , Val Loss: [[8.48682234]]
Epoch: 21 , Loss: [[17.03943262]] , Val Loss: [[8.50437328]]
Epoch: 22 , Loss: [[17.01417255]] , Val Loss: [[8.49409597]]
Epoch: 23 , Loss: [[17.20918888]] , Val Loss: [[8.5854792]]
Epoch: 24 , Loss: [[16.92068017]] , Val Loss: [[8.44794633]]
Epoch: 25 , Loss: [[16.76856238]] , Val Loss: [[8.37295808]]
看起来不错!是时候进行预测并绘制它们以获得我们设计的视觉感受。
第3步:获得预测
我们将通过训练的权重利用正推法获得预测:
preds = []
for i in range(Y.shape[0]):
x, y = X[i], Y[i]
prev_s = np.zeros((hidden_dim, 1))
# Forward pass
for t in range(T):
mulu = np.dot(U, x)
mulw = np.dot(W, prev_s)
add = mulw + mulu
s = sigmoid(add)
mulv = np.dot(V, s)
prev_s = s
preds.append(mulv)
preds = np.array(preds)
将这些预测与实际值一起绘制:
plt.plot(preds[:, 0, 0], 'g')
plt.plot(Y[:, 0], 'r')
plt.show()

这是有关培训数据的。 我们怎么知道我们的模型是不是过拟合? 这就是我们之前创建的验证集发挥作用的时候:
preds = []
for i in range(Y_val.shape[0]):
x, y = X_val[i], Y_val[i]
prev_s = np.zeros((hidden_dim, 1))
# For each time step...
for t in range(T):
mulu = np.dot(U, x)
mulw = np.dot(W, prev_s)
add = mulw + mulu
s = sigmoid(add)
mulv = np.dot(V, s)
prev_s = s
preds.append(mulv)
preds = np.array(preds)
plt.plot(preds[:, 0, 0], 'g')
plt.plot(Y_val[:, 0], 'r')
plt.show()
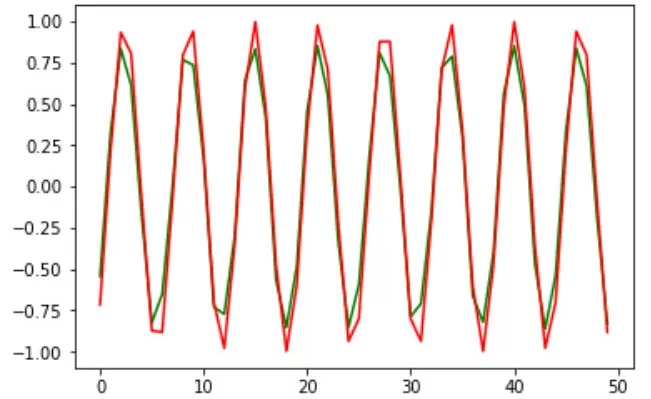
不错。 预测看起来令人印象深刻。 验证数据的均方根误差分数也是可以接受的:
from sklearn.metrics import mean_squared_error
math.sqrt(mean_squared_error(Y_val[:, 0] * max_val, preds[:, 0, 0] * max_val))
0.127191931509431
总结
在处理序列数据时,我没有足够强调循环神经网络多么有用。 我恳请大家学习并将其应用于数据集。 尝试去解决NLP问题,看看是否可以找到解决方案。
在本文中,我们学习了如何使用numpy库从零开始创建循环神经网络模型。 您也可以使用像Keras或Caffe这样的高级库,但了解您正在实施的概念至关重要。





