本文转载自:矩阵元微信公众号
隐私计算与密码学
数据已经成为数字经济时代最重要的生产要素,成为企业和机构的核心资产,而数据价值的体现则是数据的隐私保护。传统的面向静态数据保护的安全手段已经无法满足数据在跨企业、跨机构之间流通的需求。
隐私计算作为新兴技术为数据的安全流动提供了新的可能性,即使在数据融合、计算的过程中,也可以保证数据的隐私。
密码学是隐私计算技术一个重要的方向,其中使用较为广泛的几个领域为安全多方计算(secure Multi-Party Computation),同态加密(Homomorphic Encryption)和零知识证明(Zero-Knowledge Proof)。这三种密码学技术分别适用于不同的场景,技术上也有不同的优劣势,因此在具体的解决方案中往往采用多种技术的组合,以在不同的环境下满足不同的需求。
安全多方计算(MPC)是由图灵奖获得者姚期智院士于1982年提出的概念。通过将近40年的发展,在理论和工程上都得到了长足的进步。以秘密分享(Secret Sharing)、混淆电路(Garbled Circuit)和不经意传输(Oblivious Transfer)等技术为主的MPC协议中(从广义的概念上来看,同态加密和零知识证明也可以归于安全多方计算的范畴),往往网络通信上的代价要大于计算的代价。在合适的网络条件下基于上述技术的MPC协议的实际性能也能满足许多实际的需求。
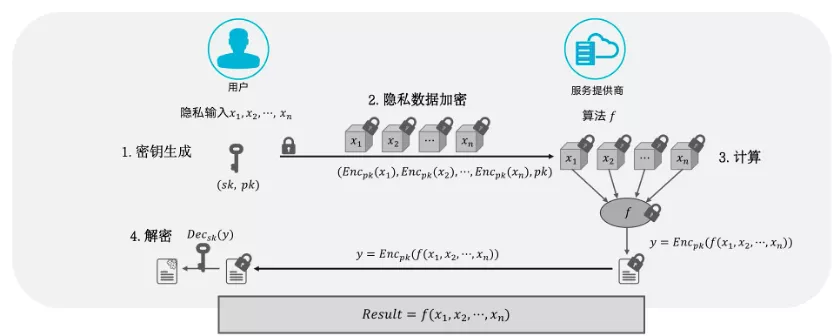
同态加密(HE)是Ron Rivest、Leonard Adleman以及Michael L. Dertouzo在1978年提出的概念。与传统的加密算法的区别在于,除了加密和解密算法之外,还支持同态计算算法——可以在密文上进行计算,计算后解密可等价于先解密后计算。同态加密具有非常多的应用,一个典型的应用就是安全外包计算,如下图。由于同态加密对于网络通信的要求较低,因此也可以做为MPC的一个组件来支持不同的协议。
同态计算有多种分类,其中包括加法同态加密(只能支持加法的同态操作,比如Paillier)、乘法同态加密(只能支持乘法的同态操作,比如ElGamal)、深度受限的同态加密(可以同时支持加法和乘法,但是电路的深度有限制,比如BGV/BFV/CKKS/TFHE等)和全同态加密(可以支持所有的计算,加法和乘法,同时深度不受限制,比如BGV/BFV/CKKS/TFHE + Boostrapping)。
全同态加密(Fully Homomophic Encryption)一直被称为密码学的圣杯,直到2009年才由Craig Gentry给出第一个基于格理论的方案。此后几乎所有的全同态加密方案都是在该框架下进行优化和改良。在Craig Gentry的开创性工作之上,(全)同态加密方案在算法性能上有了极大的提升,并且已经开始应用到隐私机器学习、深度学习等领域。
虽然算法上的性能有了很大提高,但是同态加密的计算复杂度仍然非常高。与明文的操作相比,密文同态的操作要超出4-5个数量级。如何从硬件的角度对同态加密算法进行加速已经成为非常迫切的需求,性能的提升也直接推动同态加密在各类复杂场景的应用。
数论变换NTT
几乎现在所有的具备复杂同态计算能力的(全)同态加密算法都是基于格理论(Lattice)的。其安全性均可基于Learning With Error(LWE)或者Ring Learning With Error(RLWE)这两类困难问题上。
从表现来看,这类同态加密算法的基本操作都会涉及到维数较大的整系数多项式的加法和乘法。对于基本操作的性能提升,可以直接提升整个加密方案的性能,甚至提升倍数还具有放大效应。
平凡的算法计算两个N次多项式的加法的复杂度为O(N),乘法的复杂度为O(N2),因此多项式乘法是基本操作中更耗性能一个操作。为提升多项式乘法的计算性能,常用的做法是采用数论变换(Number-Theoretic Transform,NTT),可以将乘法的复杂度降为O(NlogN)。
NTT实际上是傅立叶变换(FFT)的一个变种,其优势在于可以直接对整数进行处理,无需考虑浮点数中的存储以及精度问题。另外对大整数(针对同态的场景)的运算可以通过中国剩余定理转换为多个独立的小素数的NTT,因此该算法也非常适合FPGA的并行优化。
NTT的FPGA加速
NTT中最重要的部分为蝶形运算。为在FPGA中实现蝶形运算,矩阵元设计专门的处理单元(Processing Element,PE)以及与之匹配的交换网络,结合状态机等组成一个完整的NTT模块。多个NTT模块通过连接器(connector)与片外存储(off chip memory)DDR进行交互。除此之外,矩阵元在初版的NTT加速的框架中,进行了以下几点的优化:
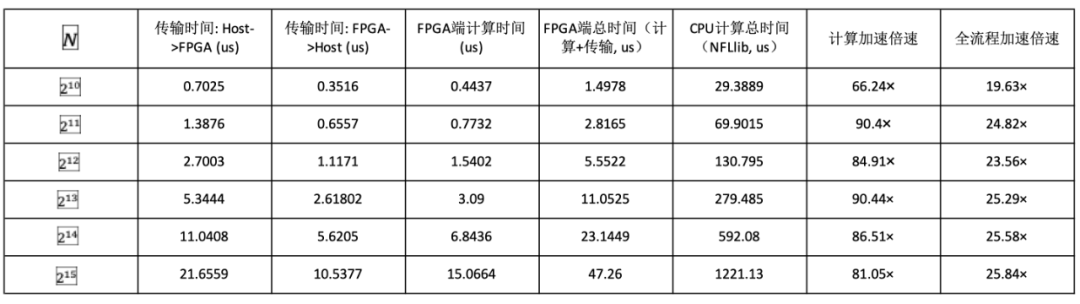
矩阵元硬件加速框架采用Xilinx Alveo U250加速卡,Host端CPU为Intel(R) Core(TM) i5-6200U CPU @ 2.30GHz。目前的性能数据如下。其中N为多项式维度,模数为51比特的q=0x7FFFFFFFE0001UL,CPU的NTT实现使用目前较快的软件库NFLlib :https://github.com/quarkslab/NFLlib
系统资源占用数据如下:
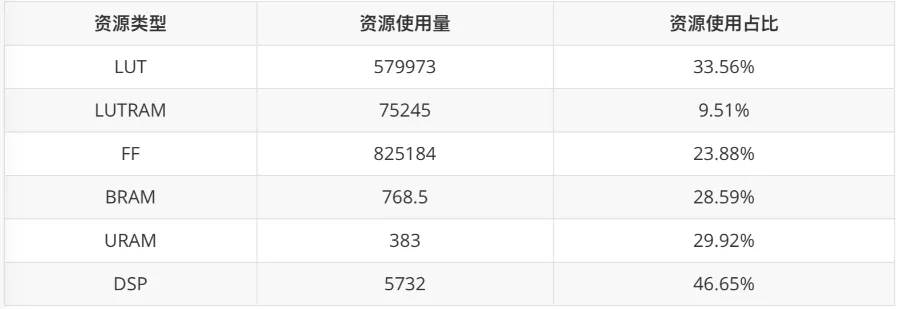
LUT: Look-Up Table 查找表
LUTRAM: Look-Up Table Random Access Memory 查找表内存
FF: Flip Flop 触发器
BRAM: Block Random Access Memory 块内存
URAM: Ultra RAM Ultra 内存
DSP:Digital Signal Processor 数字信号处理器
整体而言,当前版本的NTT计算FPGA加速倍数在25倍左右。从目前的状态来看,还可以在算法和工程上继续继续优化,特别是在数据传输时间上进行优化,资源的使用也可进一步减少,并行化进一步提高等等。
后续规划
NTT只是(全)同态加密算中最为基础、最为底层的操作。矩阵元在初版NTT的基础上将持续优化基础算子的性能。同时将逐步实现更为高阶的操作,比如加密、解密和同态操作,最终实现对(全)同态加密的整体硬件加速支持,并应用在隐私机器学习、深度学习等同态加密的相关场景中,满足性能要求。最终矩阵元的(全)同态加密硬件加速将配合Rosetta隐私AI计算框架,一起提供完备的软硬一体化解决方案。