作者:安平博,Xilinx高级工程师;来源:AI加速微信公众号
使用FPGA进行神经网络加速需要编译器的支持,因为一个复杂的神经网络会产生大量的指令,手写指令不能满足通用化要求,费时又费力。编译器依据神经网络的图结构,产生硬件可执行指令序列。从广义上讲,编译器包括了前端和后端,前端主要实现从tensorflow等深度学习框架描述的网络结构形式到新表示的转化,后端完成编译器中间表示到硬件可执行程序的转化。前端对硬件应该是透明的,它的主要挑战在于如何设计出一套通用的中间表示,并且和tensorflow,pytorch等不同深度学习框架进行对接。更复杂的编译器前端还包含了很多硬件无关的优化策略,比如常数折叠,算符融合等等。后端是和具体硬件相关的,不同的硬件都具有自己的设计结构,针对这些设计结构内存分配,优化方式等都有很多不同。特别是针对FPGA,每个硬件只能设计自己的后端,不可能找到一个通用的后端架构。因为FPGA的灵活特性,针对不同的网络,可能设计出的结构都有差异。
自从第一个网络加速项目开始,自己就一直在手写指令,改了一个有一个版本,做了一次又一次优化,越发发现编译器的重要。因此闲暇之余开始研究开源的神经网络加速器编译器架构。TVM提供了一个完整的编译器架构解决方案,它自定义了IR,对计算过程进行了抽象化(包括算符,变量等),提供了一个完整的代码生成和执行框架,开发者完全可以在其框架内改写自己的编译器。
TVM整体结构如下图:
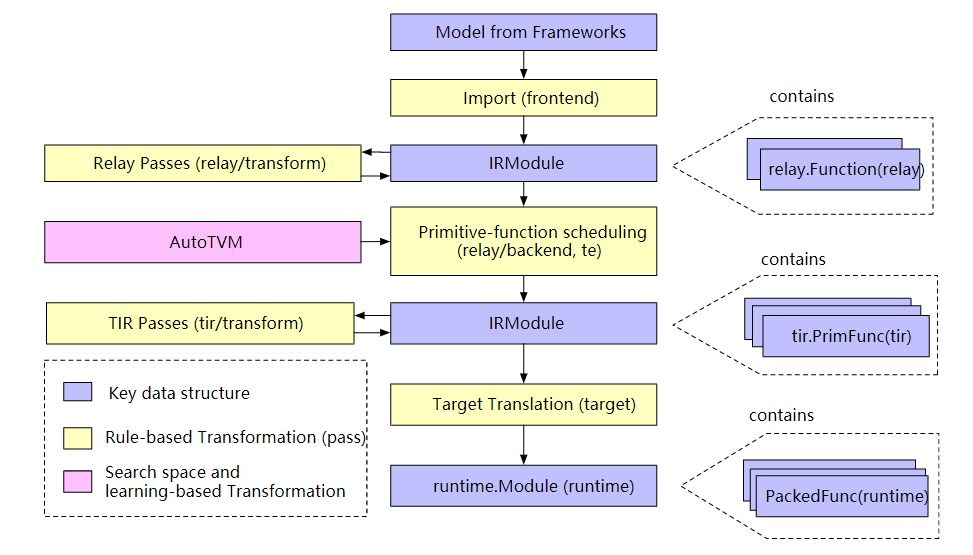
Frontend:这个就是将来自不同深度学习框架中的神经网络转化成TVM自己的IR表示。神经网络模型的输入是protoBuf文件,比如在tensorflow中就是pbtxt文件,这个文件中是protobuf形式的网络结构,包括各个节点的特性,参数,算符等。
IRModule:TVM定义的IR结构有两类,一个是relay中的IR,一个是TIR。两者的区别,relay中的IR是一个高层次的抽象表示,而TIR是更接近硬件的表示结构。Relay中IR通过relay::function来描述,function描述了整个图结构,是图结构的另外一种描述,function有输入输出变量,内部是计算序列。很像编程中定义的函数。TIR中用PrimFunc描述,它更加底层一些,包含了tensor计算算符,load/store等指令。用户如果有自定义的指令,就可以在TIR中定义这些指令。
Passes:这些pass是完成对网络图结构的一些优化和转化,比如常数折叠,算符融合,去除死代码等等,都使用pass来构造。TVM通过这些pass来遍历,然后对节点进行修改。对于内存分配,针对硬件特点的图优化策略都可以用pass来进行构造。
Transform:transform包括两方面:优化和lowering,这些都是在pass架构中构造的。Lower实现高层次IR到TIR的转化,或者完成到硬件实现的转化。比如将多维tensor转化成一维向量。当然很多lowering操作都是硬件相关的,需要开发人员自行编写,LLVM,CUDA等就有自己的lowering方法。
Auto TVM:这个是TVM一种自动化优化方法,其主要思想就是基于强化学习的方法,搜寻一个最优的优化空间,实现网络调优。它的采集硬件实现的不同表现,来不断更新新的优化变量。通常一个网络都很大,搜索空间巨大,所以这是一项耗费量大的工程。而且开发者的硬件特点不同,可能有自己的独特优化方式,所以autoTVM是一个可选择优化方式。
Runtime:编译器提供了一个端到端的解决方案,runtime是最终可以在硬件平台上运行的程序,它包含了编译出的代码或者指令,硬件驱动,软件端调用。
以上是TVM的主要结构,在来看一下TVM代码的基本构成。
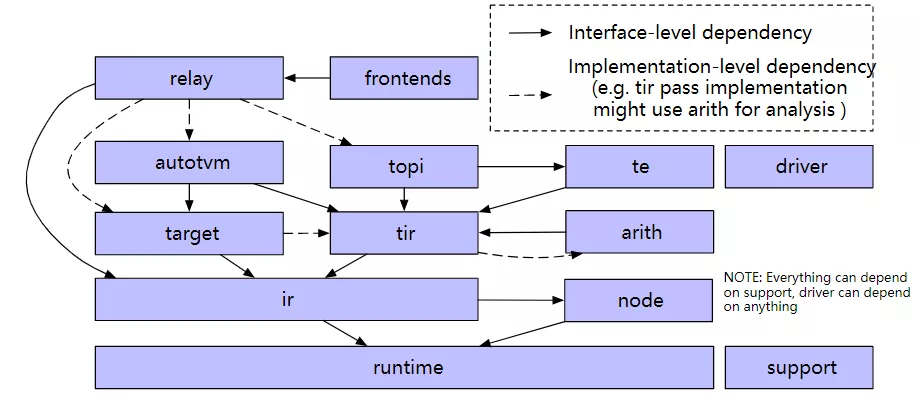
图中箭头表示了相互逻辑关系。
Support:架构的一些通用组件,比如socketing,logging等。
Frontends:TVM可以实现tensorflow,pytorch,onnx等很多深度学习框架到其自身IR表示的转化,这是frontends的主要工作,frontends就包含了针对每种深度学习框架图结构的转化函数。
Relay:这是一个高层次图结构的描述,它有自己的IR表示,用这些IR表示来描述神经网络结构。一些高层次的优化也是在relay IR的基础上进行的。
Autotvm:可选的基于强化学习的网络优化方法。
Topi:这是一个tensor计算库,里边包含了很多神经网络通用的计算单元,比如矩阵乘法,点乘,卷积等。我们可以通过这些topi来进行计算。
Tir:相比于IR来说,这个层次的计算单元更加底层和原始,更接近硬件实现。
Te:te是tensor expression,用户可以通过调用te中的函数来构建tir。TVM不仅可以将tensorflow等深度学习框架模型转化成自己的IR结构,还允许用户自己通过这些te来构建一个网络。
Node:node是在IR的基础上增加了一些新特性,可以允许用户对一些函数进行访问。这样就能够实现更加复杂的表达函数。比如如下的代码:

A和b就是tir.add的节点。
Driver:针对硬件的驱动。
Arith:这个紧紧绑定了TIR,可以帮助进行TIR优化的时候进行一些分析。
Runtime:runtime封装了图结构的转化,优化,代码生成,以及程序在硬件上的执行,为客户提供一个API接口完成所有的编译过程。





