本文转载自:上交所技术服务微信公众号
本文选自《交易技术前沿》总第四十一期文章(2020年12月)
环宇翔、崔建军、郑立荣 / 复旦大学信息科学与工程学院微纳系统中心
高昀、王嘉晨 /上证所信息网络有限公司
对于瞬息万变的证券交易市场,即时的行情信息是行情系统的基础。快速获取行情信息可以给市场参与者提供更宽裕的交易决策时间窗口,交易者获取的行情信息延时越低,往往意味着越多的交易机会和越大的决策空间。传统的基于软件的行情信息系统,信息的解析一般经过网络层数据获取、协议层数据解析、应用层数据处理等过程,在操作系统和协议层面,存在毫秒级别的上下文切换和软件处理延时,由于操作系统的进程调度和CPU主频的动态调整机制,这种延时还具备一定的不确定性。为实现纳秒级超低延时行情解析处理,本文针对上海证券交易所的行情发布系统,采用Verilog硬件描述语言,在FPGA加速卡上开发了对行情信息流的以太网,IP和UDP以及FAST协议的硬件解码,设计了支持指令集编程的微指令加速引擎。与传统的基于软件的方法相比,本文提出的专用硬件处理方案延时可降低10倍以上。
一、引言
随着量化高频交易在世界范围内的兴起,超低延时的行情信息已经逐步成为高频交易中不可或缺的环节,对于行情信息延时的优化也从软件层次的优化逐步转移到基于硬件实现的加速方案。现场可编程门阵列(FPGA),作为一种可重配置硬件,为超低延时行情解析提供了定制化硬件设计的技术基础。FPGA相较CPU,硬件电路并未完全固定,支持硬件的重构编程,可提供深入到底层硬件电路层次的逻辑优化,因而兼具更大的优化空间和足够的灵活度。FPGA一般需采用硬件描述语言(HDL)(例如Verilog或VHDL)来进行逻辑电路设计描述,通过专门的编译综合工具,转化成包含逻辑门和电路连接的网表,最终在FPGA芯片中载入运行。FPGA的开发门槛较高,周期较长,因此主流FPGA厂商均开始支持OpenCL等高层次可综合语言(High Level Synthesis,HLS)的编程,开发风格上更接近C++等高层软件编程语言,屏蔽硬件实现细节,从而加速可编程硬件的开发,但HLS无法做到精确到单时钟周期级(Clock Cycle Level)的逻辑优化,无可避免的会带来至少15%-20%的性能损失。
为了充分发挥FPGA的专用硬件加速特性,本文基于Verilog硬件描述语言,设计开发了面向证券行情信息的超低延时专用硬件解析系统。该系统通过Verilog实现了低延时以太网通信,支持UDP/IP协议的硬件解析,及STEP-FAST数据流的硬件解码。相比基于HLS的硬件设计,本文采用了流水线硬件设计优化,通过Verilog实现了FAST的硬件并行解码,解码延时可低至33ns,最终包含UDP收发及行情解码的整体穿透延时可低至847ns。
二、技术背景
(一) 行情发布系统
FAST(FIX Adapted forStreaming,适流FIX)是2005年全球金融企业联盟组织FPL提出的一种面向消息流的压缩、编码和传输方法。主要是利用消息流中先后传到的消息之间字段数据的逻辑联系压缩需要传送的数据内容,针对不同类型的二进制字段进行高效的二进制编码使得压缩率提高,传输数据大小降低。上海证券交易所现有的Level-2行情系统就部分采用了FAST技术来优化实时消息的传输,在优化消息尺寸、节省带宽、降低行情延迟等方面都获得了良好的实际应用效果。但对于下游用户来说,开发解码程序有一定的难度。目前的行情解析,主要依赖于基于传统服务器CPU的软解析模式,通过调用mFAST、openFAST进行FAST码流的解码。由于FAST数据的流式排布特征,数据前后相关性大,很难利用CPU的多线程实现处理并行化。同时,CPU相对固定的处理模式,无法提供底层更细颗粒度的操作调度,所以FAST的软解码延时较高,对CPU的负载占用较大,乃是现有行情解析系统的痛点所在。为此,我们提出了基于FPGA的超低延时硬件行情解析系统,将CPU的重负载解析任务迁移至专用硬件处理,进行电路层次的并行操作优化,并支持模版化配置,降低CPU负载,实现行情通讯和解码的整体加速。
(二) 行情解析相关协议
在当前的行情信息系统中,行情数据流需要跨过多层的协议才能从物理通信端口,这些层主要由网络通信和STEP-FAST数据流交换协议组成,具体包括:
1、以太网层
协议栈的最底层为以太网层。该层提供了网络发送数据包的物理实现(PHY)和媒体访问控制(MAC),可以通过定义数据包的发送者和接收者的媒体访问控制(MAC)地址来识别网络中的端点,并提供循环冗余校验(CRC)以确保数据完整性。
2、IP层
以太网层之上是Internet协议(IP)层。该层将计算机分为逻辑组,并为该组内的每个终端节点分配一个唯一的地址,可用于多播向多个端点发送消息。
3、TCP/UDP层
IP层之上为传输层协议,主要有TCP和UDP两种代表性协议。TCP协议全称是传输控制协议是一种面向连接的、可靠的、基于字节流的传输层通信协议。UDP协议全称是用户数据报协议,在网络中它与TCP协议一样用于处理数据包,是一种无连接的协议。
UDP协议相比TCP协议,首部开销小,无需多次握手建立连接,因而实时性更高,且支持单播、多播、广播等多种通信方式,虽然其可靠性稍差,但可通过上层应用设计实现可靠传输机制,是低延时通信的理想选择,本文的验证系统即采用了UDP协议。
4、STEP-FAST
我国金融信息行业,交易所行情数据目前主要采用STEP(Securities Trading Exchange Protocol)协议,并基于国际主流金融信息交换标准的FIX(Financial Information eXchange protocol)协议,根据行情数据的流式处理特征,进行了FAST(FIX Adapted For Streaming)编码压缩。一方面,该协议定义了各种字段和运算符,用于标识特定的股票及其定价。另一方面,FAST编码带来的流式数据压缩机制,可大幅减少带宽,但也显著增加了数据解析的复杂度。
(三) 行情解析处理方案
目前行情数据流的解析延时主要就来自于以上协议层的处理。因此,现有的行情解析方案也着重于围绕通信和数据流解码两方面展开优化,主要存在以下三种主流解决方案:
1、高性能CPU
行情解析的延时优化主要集中于软件层对FAST解码的优化,结合mFAST、openFAST等经过软件优化的FAST解码库加速FAST解析,从而实现1ms级的行情解析处理。
2、高性能CPU+基于ASIC的智能网卡
此方案在软件层优化FAST解码的基础上,通过采用如Solar Flare、Mellanox、Intel等公司的专用低延时网卡,配合 kernel bypass技术,进一步降低通信延时开销,从而达到亚毫秒级的行情解析处理。
3、高性能CPU+FPGA加速卡
此方案通过基于FPGA的专用硬件电路设计,在硬件层面实现了对网络通信和FAST码流解析的处理, CPU仅需进行上层业务逻辑的处理,占据行情解析延时的数据通信和解码被完全从CPU上offloading,最大程度地降低了延时且减少了CPU占用,可实现低至亚微秒级的超低延时行情加速,已逐步成为未来的金融信息交换技术的发展趋势。
三、系统架构
本文针对上海证券交易所的LDDS系统行情源,提出了一种基于CPU+FPGA加速卡的超低延时行情解析方案。行情数据的通信和解析均在高性能FPGA加速卡上进行了RTL电路设计实现,该硬件系统主要包括网络通信和FAST解码两大部分:
(一) 低延时万兆以太网接口实现
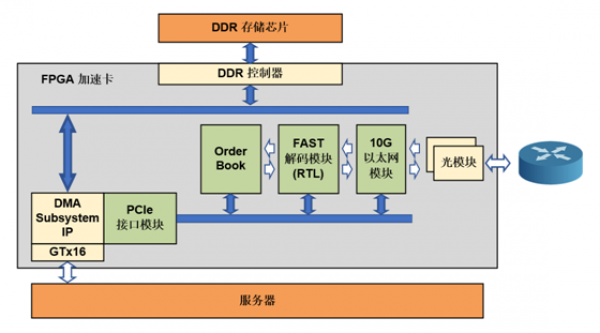
图1:基于FPGA的硬件行情加速系统框架图
不同于传统采用网卡实现网络通信的方式,本文在FPGA加速卡上直接实现了高速万兆以太网接口。基于FPGA的高速以太网接口采用了如上图所示的架构,物理层采用Xilinx公司提供的PHY IP,MAC 层采用Xilinx 公司的万兆以太网MAC IP 实现传输协议的CRC32校验码的填充与检测,并通过Verilog定制设计了UDP/IP协议解析电路。如图2所示,数据流模拟电路信号经由高速串行接口SerDes,配合PHY IP,实现了对电信号的接收端时钟恢复/发送预加重、编解码、通道绑定、数据缓存等,解析出的数字信号数据,将通过XGMII接口和MAC模块进行数据传递,对发送的数据帧进行编码,对接收的数据帧进行解码。本文中设计的以太网高速通信电路中采用了64-bit位宽的单速率XGMII总线接口和全双工10 Gbit /s 的以太网媒体控制器,支持万兆以太网数据的前导码过滤与增加、CRC校验码的填充与验证,以太数据帧长最小为64 byte,最大为1518 byte。发送端在传输数据之前,MAC控制器会先发送7 byte的同步码和1 byte的帧首定界符,并在1 帧传送结束时填充4 byte 的CRC32校验码,如果数据长度小于46 byte,则会自动在数据字段填充PAD 字符,即补0。在接收端,MAC层去掉前导码和帧首定界符,并对帧进行CRC32校验。MAC层获取的数据将进一步经过UDP/IP解析模块的处理,最终转化为实际的Raw Data。
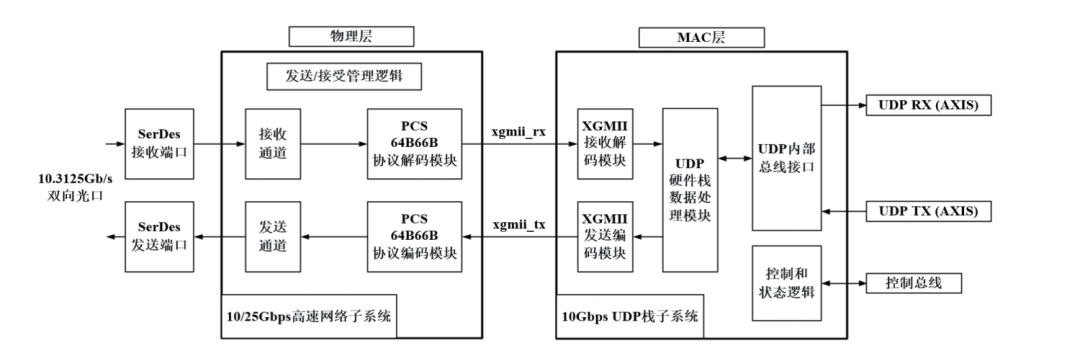
图2:低延时以太网架构
(二) STEP-FAST硬件解码
通信接口获取到Raw Data,仍然不是能直接读取的行情信息,必须遵循行情信息编解码的规范加以解析,本文即在FPGA上实现了相应的硬件解析器。
1、STEP解析器
STEP协议采用tag=value,将FAST编码的数据流附加额外信息进行了封装,可提供交易行情之外的业务会话信息。为了最大程度降低行情数据解析的延时,本文采用verilog定制设计了STEP协议的硬件解析器,该解析器模块每个周期从AXI总线获取经由网口传递来的64-bit数据段,64-bit的数据段将以8-bit为单位进行处理,通过检测“=“和SOH的ASCII码,自动判定当前数据段所属的tag或value属性,并发往指定的缓存空间,留待后续的信息读取或进一步的FAST解码。
2、FAST解析器
当STEP中的FAST数据作为tag96的value被剥离后,数据将被送入定制设计的FAST解码器进行硬件解码。如图3所示,原始的行情信息遵循了FIX的协议格式,采用了
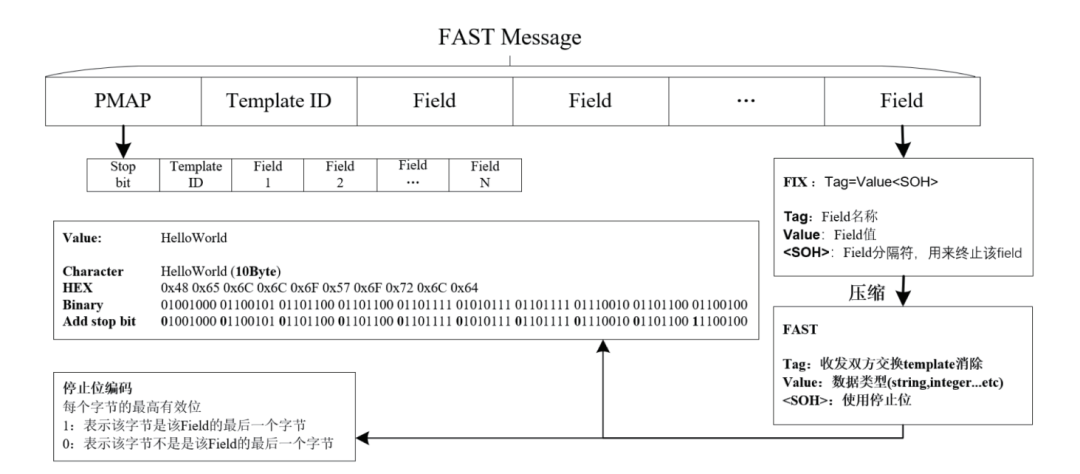
图3:FAST数据流的编码特征
template定义减少了重复出现的Tag数据。特定类别的数据往往格式相对固定,一般由一组相对通用的Tag组成,比如行情快照、逐笔、指数等信息,因此,可以将特定组的Tag转换为一套收发双方共同约定的template模版来解析数据。在双方都获得数据解析模版的情况下,码流无需再保存Tag信息,而只需要按照模版定义的字段顺序和操作组织数据,从而省去了Tag数据的传输。
数据操作和数据类型定义减少了Value数据的存储开销。此方法主要利用了数据上下文的相关性来减少不必要的数据存储,包括但不限于Value数据中可能存在的:数据当前值相教前值保持不变、当前值相教前值差值较小、不定长数据等情形。根据数据的前后关联和Value值实际长度,便只需记录历史数据、变化情况、有效数据等相对精简的信息,即可通过反演操作恢复原始数据,能够极大地降低数据码流的存储开销。
单bit停止位替代
采用了上述压缩优化的FAST编码,可以大幅降低数据码流的空间占用,数据量可压缩>70%,但同时也对解码提出了较高的要求。软件方案虽然可以一定程度上利用CPU处理特性进行解析优化,但CPU本身不具备足够灵活的硬件算子或操作来支持精确到bit位的解码优化。本文提出的基于FPGA的专用硬件解码方案,使用Verilog硬件描述语言设计了专门支持FAST码流解析的硬件操作算子,通过微指令编码方式提供了底层硬件算子级别的重构能力,不同的template可以映射为算子对应的微指令操作,并进行了FAST解码过程的操作流水线优化,最终实现了纳秒级别的超低延时FAST解码。FAST解码的硬件设计核心模块包括:
(1)停止位检测和字段分割单元
该单元以byte为单位,在单个时钟周期内完成最高bit位检测,判断出当前字节是否为字段停止字节,并根据判断结果,同步更新后续微程序的跳转指令指针,使得已检测的字节能够被立即发往指定的操作算子,在微指令控制下进入解析流水线执行连续的操作。
(2)FAST解码操作算子
硬件实现的操作算子是FAST解码的关键部件,这些操作算子包括:存在图的字段选择、数据移位、计算、复制、尾部更新、字节向量计数、Sequence字段循环控制等算子,这些硬件经过专门的电路设计优化,可以运行在较高的时钟频率,并且在1-2个时钟周期内即可完成对应算子操作(计数和循环控制操作除外)。所有算子模块的控制信号,均由微指令统一整合加以控制,为解码提供了足够的硬件调度灵活性。
(3)FAST模版解析引擎
FAST码流解析的规则主要由template来定义,因此本文基于微指令技术实现了粗粒度可重构的硬件解析框架。微指令解码器会在每个时钟周期获得当前周期的硬件控制指令,同时翻译为并行的多路控制信号,指示相应模块执行匹配操作。在此框架下,XML格式的template将被翻译为连续的字段数据类型定义、字段操作和流程控制的微程序,FAST码流将持续的通过数据总线传输给硬件解析流水线通道,在微程序的并行控制下,完成解码操作。虽然各算子模块并行执行操作,但由于FAST数据存在前后关联,直接地并行解码难以实现。前后关联的数据遵循相对固定的处理流程,但所处的处理阶段不尽相同,所需占用的硬件算子也并不一样。因此,FAST数据能够以byte为单位,在微指令控制下并行地被调度给当前空闲的硬件算子模块,一方面保证了解析流程的顺序,另一方面仍提高了硬件算子处理的并行度,可进一步提升硬件解析性能。
四、测试结果
(一) 测试环境
为评估硬件方案相对软件方案的性能优势,本文在完成了FPGA超低延时行情解析系统设计的同时,还搭建了软件实现的对照测试系统。测试系统的软硬件环境如表1所示:
表1:行情加速软硬件对照测试系统环境配置
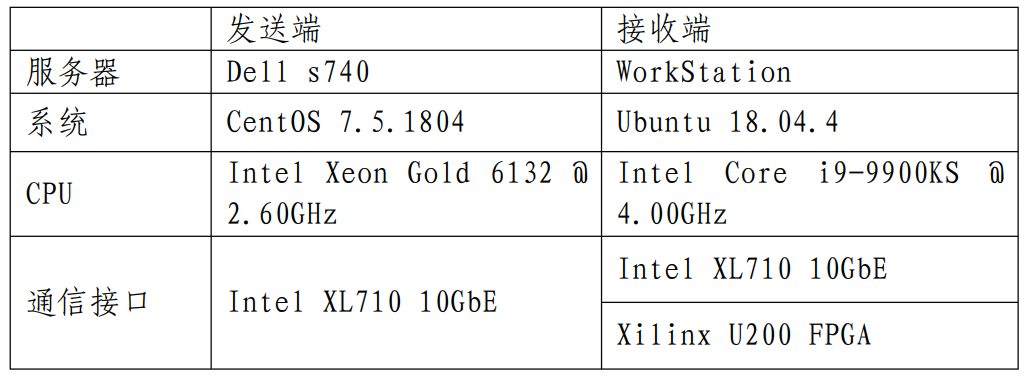
发送端服务器将读取上海证券交易所的行情源VDE中截取的行情数据,通过Intel高性能万兆以太网卡,经由光模块同时发往接收端高性能工作站的万兆以太网卡和FPGA专用加速卡。本文在接收端同时部署了基于万兆以太网卡的软件接收解码方案和基于Xilinx U200 FPGA加速卡的专用硬件行情解析方案,两台测试服务器的通信连接示意图如图4所示。两台服务器调用socket进行基于UDP的行情数据传输,并在接收端完成数据接收和解码。

图4:行情加速软硬件对比测试系统示意图
(二) 测试结果
本测试以Intel高性能专用网卡作为对比测试基准,在发送服务器同时发送同样数据给专用网卡和FPGA加速卡,进行收发和行情解码的处理延时实测,软硬件对比测试方案架构如下图所示,分别进行了方案整体延时实测和穿透延时测试。
1、整体行情解析延时测试
TH为硬件方案总延时,TS为软件方案总延时,TD为硬件解码延时。测试数据以上海证券交易所level1行情的一条step数据为例。测试的STEP包数据长度为1515 Byte,其中包括98byte的STEP头、181byte的FIX头、1221byte的20条FAST消息,以及8byte的FIX尾和7byte的Step尾。VDE重复发该条STEP包,测得软硬件解码的平均解码延时如表2所示:
表2:FAST解码软硬件方案处理性能对比
| 软件解码 | 硬件解码 |
|---|---|
| 示例STEP数据平均:217us | 示例STEP数据平均:14us |
其中STEP解码部分的延时在150us-250us,时间有波动,取决于CPU负载;而硬件解码时间固定,无波动。硬件解码延时相比于软件解码缩短了10倍以上。

图5:行情加速软硬件对比测试系统架构图
2、穿透延时测试
本文对FPGA加速卡上实现的网络通信和行情流解码的穿透延时进行了评估测试,穿透延时从数据到达FPGA端的以太网口接收开始计算,截止到FPGA端以太网口开始发出经过STEP-FAST解码得到的行情数据,包含了FPGA端硬件实现的的以太网接收、数据解码和以太网发送三部分,各部分具体延时测试结果如表3所示。测试结果显示,FAST单个字段的解码延时如图6的T1所示,为33ns。测试结果显示,FPGA端的行情穿透延时可低至847ns。
表3:基于FPGA的硬件行情解析方案穿透延时测试
| 以太网接收(PHY RX + MAC RX) | STEP-FAST解码 | 以太网发送(MAC TX+ PHY TX) |
|---|---|---|
| 430 ns | 33ns | 384ns |
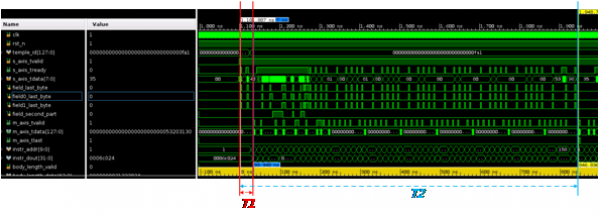
图6: T1为STEP-FAST解码延时,T2为单条UA5302 FAST数据的解码延时
3、不同模板解码延时测试
从数据流中随机抽取不同模板的一条FAST数据测试延时,分别测试了上海证券交易所Level1FAST实时流行情UA5302,Level2行情快照UA3202,Level2逐笔行情UA3201和Level2指数行情UA3113四种具有代表性的模板数据。测试结果如表4所示。对应的延时测试波形图如图6T2,图7T3,图8T4,图9T5所示。
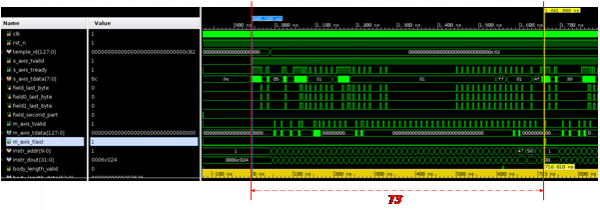
图7: T3为单条逐笔UA3202FAST数据的解码延时

图8: T4为单条逐笔UA3201FAST数据的解码延时

图9: T5为单条指数行情UA3113 FAST数据的解码延时
五、总结和展望
行情信息是交易市场运行的基础。及时地获取行情信息,是一切交易发生的前提。随着电子信息技术的飞速发展,高实时的行情信息越来越被市场参与者所青睐,推动着金融信息交换技术向着低延时行情解析的方向不断发展演进。FPGA以高硬件集成度、高灵活性等优势,越来越受到金融信息开发者的关注。相比较传统的软件实现的行情系统,FPGA提供了集网络处理、编解码甚至智能算法加速等于一体的集成化可编程硬件开发平台。原有系统中的性能瓶颈功能,均可以转化到FPGA平台,进行专用硬件的定制设计和精确到纳秒级时钟的性能优化。本文即面向证券行情信息领域,设计开发了基于FPGA的超低延时专用硬件解析系统。为了实现超低延时的行情信息解析,本文通过Verilog实现了低延时以太网通信,支持UDP/IP协议的硬件解析,提出并设计了基于微指令架构的STEP-FAST数据流的硬件解码模块,支持根据template快速配置解码硬件。通过微指令层次的FAST解码流水线优化,实现了FAST码流的硬件并行解码,解码延时可低至33 ns,最终包含UDP收发及行情解码的整体穿透延时可低至847 ns。
本文的对行情解析的延时优化主要集中于网络通信和FAST解码两大部分的优化,实际的业务系统还会涉及到FPGA处理数据与主机CPU频繁的数据交互,若未充分优化,则可能由于中断引发频繁的内核态和用户态的切换,大幅提升FPGA与主机CPU数据交互的延时。针对此问题,未来可在CPU端引入kernel bypass机制,配合FPGA上的高速DMA模块,采用轮询方式的PMD(Poll Mode Drivers)驱动来替代原来Linux操作系统的基于中断触发的数据交互机制,使用无中断方式直接操作网卡的接收和发送队列,则可大幅降低系统方案的行情数据解析及业务处理延时,这也将是未来本文系统进一步优化的方向。
本文目前只涉及了行情数据的通信和解码,但行情业务远不止于此。随着大数据、人工智能等技术的飞速发展,行情业务将不只停留在对原始数据的解析,结合新的处理技术和手段,行情信息必定可以被挖掘出更大的价值。FPGA是传统CPU平台的有益补充,提供了丰富的硬件逻辑和计算资源,将是未来新处理业务的良好承载平台。行情硬件解析仅占用了FPGA少量的资源,该硬件平台仍存在巨大的空间去承载更为复杂的处理任务,诸如数据库加速、大数据预处理、分布式计算、人工智能算法处理等,为现有信息系统赋能、赋智。行情业务通过FPGA实现软硬件结合一体化必将是未来重要的发展方向。





