本文转载自:SDNLAB微信公众号
随着技术的发展与革新,服务器、SmartNIC与DPU之间的界限越来越模糊,但实际上,定义与用例之间几乎没有多大关系。今天,我们针对Xilinx日前推出的新一代Alveo SmartNIC产品组合,从中窥探SmartNIC的未来发展趋势:可组合性。
新一代SmartNIC融合了定制ASIC、Arm CPU和FPGA元素
FPGA解放了服务器上昂贵的CPU计算资源,通常用Java之类的高级语言编写,不过出于性能方面的考虑,有时也用C / C ++编写,这可以帮助减少延迟。在FPGA上嵌入Arm处理器,可以满足嵌入式计算的目的,同时也可以减轻硬件设计的难度。从某种意义上说,FPGA的可扩展可编程逻辑是Arm内核的加速器,CPU是FPGA的串行处理加速器。FPGA本身就是混合设备,它们被进一步嵌入到具有更高级别的计算、网络和内存的系统中。
过去几十年,基于PCI Express总线定制的ASIC将CPU连接到网络。随着时间推移,ASIC可以从CPU上分担一些网络功能,它们在处理数据包方面做得非常好,但性能不够专业。随着技术的发展,NIC变得越来越智能,ASIC添加了越来越多的offload,Altera和Xilinx都创建了可编程的SmartNIC,他们可以添加更广泛的offload,并将更广泛的系统软件从CPU迁移到SmartNIC。现在,Xilinx推出的新一代可编程SmartNIC混合了定制ASIC、Arm CPU和FPGA计算元素,并支持更广泛的CPU offload,包括I/O和网络虚拟化。
以下是Xilinx NIC产品阵容:

2019年,Xilinx收购了SolarFlare,Xilinx X2 offload 网卡就来自于SolarFlare。在去年,Xilinx发布了Alveo U25智能网卡,它采用的是针对25GbE这一代的Solarflare IP。今年发布的Alveo SN1000则是针对100GbE这一代。
从SN1022型号开始,SN1000系列的架构都是基于赛灵思 16nm UltraScale+FPGA,容量为100万个LUT。SN1000还有一个16核Arm处理器,安装在Cortex-A72内核上,运行频率为2 GHz,该处理器来自NXP半导体。
SN1000有4Gb的DDR4内存用于Arm CPU,8Gb的DDR4内存用于FPGA。SmartNIC上有两个100 GB/s的以太网收发器,并带有到服务器主板的PCI Express 3.0 x16和PCI Express 4.0 x8接口。
与其他Xilinx SmartNIC一样,SN1000具有多种onload和offload 功能。
关于onload,Xilinx在收购Solarflare后获得了TCPDirect功能,它可以直接绕过内核进入Linux操作系统的用户空间,以加快网络速度,减少延迟。全球90%的金融交易所都在使用该功能。Alveo U25也内置了Solarflare Onload功能。
关于offload,SN1000有开放虚拟交换机、Intel DPDK等经典卸载功能,以及一系列基于硬件的数据包处理加速,可以在FPGA上每秒处理400万个状态连接和1亿个数据包。根据Xilinx计算,如果把数据包处理工作放在Arm CPU上处理,每秒能处理3200万个数据包就很不错了。
由于Xilinx采用了一个ARM CPU外加一个FPGA的方案,这意味着可以同时具有控制和数据两个平面,类似于我们看到的现代交换机分段机制。一般来说,应用程序的数据平面运行在FPGA架构上,控制平面运行在Alveo设备上的Arm CPU上。
过去,访问FPGA架构的唯一方法是通过VHDL或RTL,但是现在可以使用P4并将其编译为LUT。因此,与Alveo U25一样,SN1000可以用P4,C / C ++和HLS语言编程,并通过Vitis集成开发环境和运行协调。
SmartNIC越来越智能的原因不仅仅是因为摩尔定律。
Xilinx数据中心集团营销总监Kartik Srinivasan表示:“在10 Gb/s和25 Gb/s的速度下,传统的标准NIC表现非常好,而CPU却运行缓慢。当速度达25 Gb/s后,CPU开始阻塞,offload有助于数据包的处理,并且通常会进行一些高级存储加速,这大多数都是基于ASIC的,没有任何可编程性。当数据中心的服务器端口到40 Gb/s、50 Gb/s甚至100 Gb/s时,CPU的阻塞就更严重。所以,几乎所有的超大规模用户和云服务提供商很早就开始使用SmartNIC了,并且他们都有自己独特的需求和功能,每六个月或十二个月进行一次升级。”
总结一下就是:ASIC发展速度不够快,纯CPU又无法提供特别好的性能,加上超大规模用户和云服务提供商的强烈需求,这几个因素驱动着SmartNIC的快速发展。
高频交易平台:开发快速&超低延迟
先科普下高频交易是什么:
百度百科:高频交易是指从那些人们无法利用的极为短暂的市场变化中寻求获利的计算机化交易,比如,某种证券买入价和卖出价差价的微小变化,或者某只股票在不同交易所之间的微小价差。
总之,高频交易都是由计算机自动完成的程序化交易,并且,交易量巨大。
Xilinx的加速算法交易解决方案在高频交易中大受欢迎,它与定制硬件开发、CPU纯软件这两种解决方案的对比如下图:
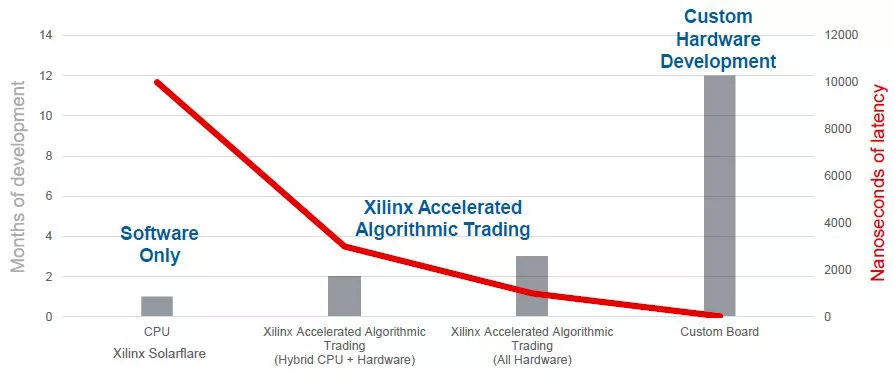
如上图所示,定制硬件开发虽然可以提供最低的延迟,但是可能需要一年时间才能将新的ASIC投入使用,这完全不能满足不断变化的算法交易环境。在CPU上运行的纯软件功能的上市时间最短,但延迟约为10微秒。相比这两种方式,Xilinx加速算法交易解决方案显得合适很多。
这里的基本逻辑是,数据从PCIe的网卡通过PCIe总线传到CPU,然后CPU处理数据并制定决策后,还必须通过PCIe总线将数据传回给网卡,这导致延迟很高。而借助FPGA,无需进行PCIe的遍历,而是使用自定义的逻辑流水线就可以进行交易,从网络获取数据并将其输入逻辑流水线只需要15纳秒的时间,大大降低了延时。
由于高频交易公司通常不愿意公开其核心的算法,所以公司可将其自己的算法IP添加到加速算法交易解决方案中,进行客制化交易,在不到10%的时间和资源支出的情况下,获得80%至90%的完全定制化。
“Smart World”AI视频分析平台
Xilinx的“Smart World”的AI视频分析平台基于FPGA,可以提供100毫秒延迟的确定性性能,也就是在眨眼之间就能找出视频流中的内容。其性能要求如下所示:

这种视频分析基本上是一个人工智能推理问题,它处理数据就在实体所在的地方进行,这也可以说是某种加速的边缘计算。
在边缘上进行规模合理的AI推理时,Xilinx可以与Nvidia的T4 GPU加速器抗衡。下图是,在支持32个摄像机的情况下,两个Xilinx加速器(Alveo U30和Alveo U50)与四个Nvidia T4加速器的对比。
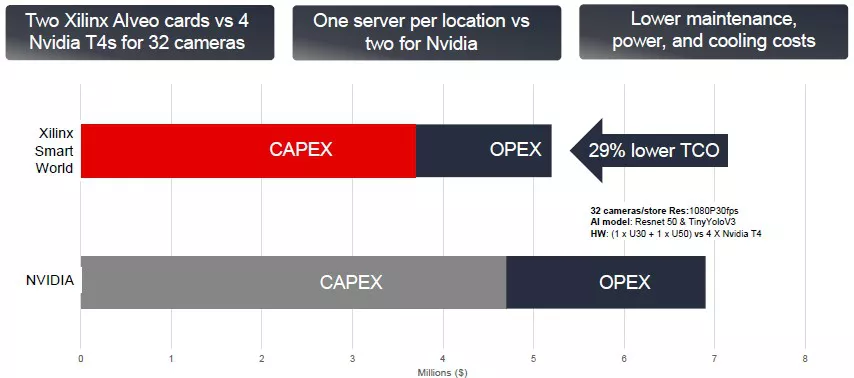
如上图所示,Xilinx的成本要低一些,如果有大规模的视频分析需求,可以考虑更换成本更低的平台。
看下图,FPGA最具吸引力的地方在于延迟方面:

形象的说,使用T4 GPU加速器处理服务器上的视频图像需要眨眼两次,而使用FPGA加速器只需眨一下眼即可。
Xilinx及其合作伙伴着眼于工业安全、智能城市、智能建筑和智能零售等邻近市场,并根据需要定制了硬件:

Xilinx与Aupera合作开发了智能零售和智能城市的应用程序,与DeepAI合作开发边缘AI培训,与Mipsology合作开发用于Nvidia GPU加速系统的CUDA代码,并将其自动移植到了FPGA加速系统中。
总结
另外提一下,Xilinx将会有一个新的App Store,你可以将Xilinx FPGA上开发的IP模块或解决方案放在App Store中,其他Xilinx FPGA用户可以购买IP并用在其硬件上,无需自己从头开发这个IP,从而节省了整个开发周期的时间。
总的来看,Xilinx Alveo SN1000不仅在硬件方面很强大,它的可组合性也可以为客户提供灵活、集成的优质解决方案。另外,Xilinx正试图建立一个IP市场,就像手机可以直接从应用商店安装软件一样,这可以极大地减少开发周期。毫无疑问,除了SmartNIC的硬件升级,这也是一个行业的变革。
原文链接:https://www.nextplatform.com/2021/02/23/giving-smartnics-bigger-fpga-and...
免责声明:本文为网络转载文章,转载此文目的在于传播相关技术知识,版权归原作者所有,如涉及侵权,请联系小编删除(联系邮箱:service@eetrend.com )。





