随着人工智能和机器学习算法取得一系列新进展,众多高计算强度的应用正在被部署到边缘设备上。当下,业界迫切需要一种高效率的硬件,既能高效率地执行复杂算法又能适应这种技术的快速演进。在此背景下,赛灵思 Kria K26 SOM应运而生,为 ML 边缘应用开发提供了更加理想的选择。
赛灵思的研究结果表明,K26 SOM 提供了比英伟达 Jetson Nano 高出大约 3 倍的性能。此外,它的单位功耗性能较之英伟达 Jetson TX2 提升了 2 倍。对于 SSD MobileNet-v1 这样的网络,K26 SOM 的低时延、高性能深度学习处理单元 (DPU)提供了比 Nano 高出 4 倍甚至更高的性能。
1. 与未来兼容的 Kria K26 SOM
智能应用除了要求亚微秒级的时延,还需要具备私密性、低功耗、安全性和低成本。以 Zynq MPSoC 架构为基础,Kria K26 SOM 提供了业界一流的单位功耗性能和更低的总体拥有成本,使之成为边缘设备的理想选择。
原始计算能力
就在边缘设备上部署解决方案而言,硬件必须拥有充足的算力,才能处理先进 ML 算法工作负载。我们可以使用各种深度学习处理单元 (DPU) 配置对 Kria K26 SOM 进行配置,还能根据性能要求,将最适用的配置集成到设计内。
支持更低精度的数据类型
深度学习算法正在以极快的速度演进发展,各种更低精度的数据类型和定制数据正在进入使用。传统的 GPU 厂商已无法满足当前的市场需求,而 Kria K26 SOM 能够支持全系列数据类型精度,如 PF32、INT8、二进制和其他定制数据类型。
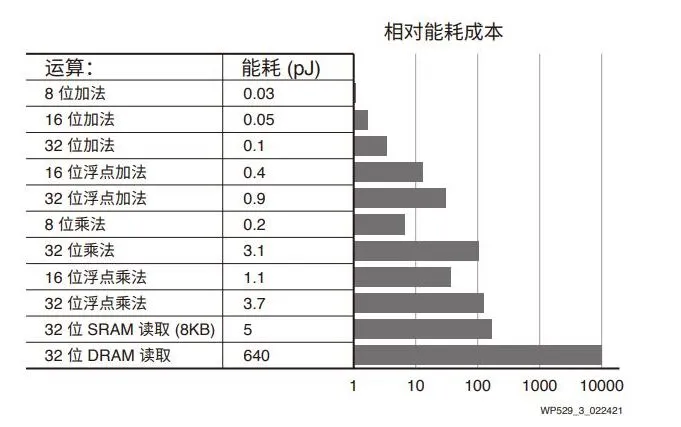
运算的能耗成本
低时延与低功耗
为了改善软件可编程能力,GPU 架构需要频繁访问外部 DDR。这种做法非常低效,有时候会对高带宽设计要求构成瓶颈。相反,Zynq MPSoC 架构具有高能效,它的可重配置能
力便于开发者设计的应用减少或不必访问外部存储器。这不仅有助于减少应用的总功耗,也通过降低端到端时延改善了响应能力。
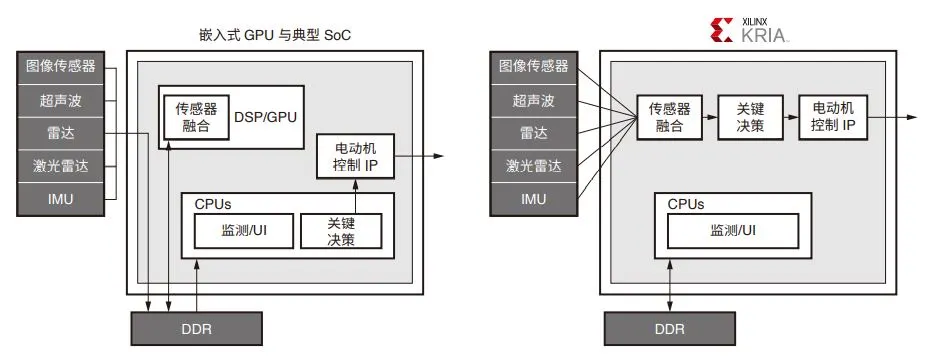
典型 GPU 与 Zynq MPSoC 架构
灵活性
与数据流固定的 GPU 不同,赛灵思硬件提供了灵活性用来专门地重新配置数据路径,从而实现最大吞吐量并降低时延。此外,可编程的数据路径也降低了对批处理的需求,而批处理是 GPU 的一个重大不足,需要在降低时延或提高吞吐量之间做出权衡取舍。Kria SOM 灵活的架构已在稀疏网络中展示出巨大潜力。
2. 与英伟达 Jetson 性能比较
深度学习模型性能比较
根据测试数据,所有模型在 K26 SOM 上的性能数值均优于英伟达 Jetson Nano。而且对于 SSD Mobilenet-V1 等部分模型,吞吐量则为 Jetson Nano 的四倍以上,为 Jetson Tx2 的两倍左右,从下表可以很容易地看到显著的吞吐量提升。
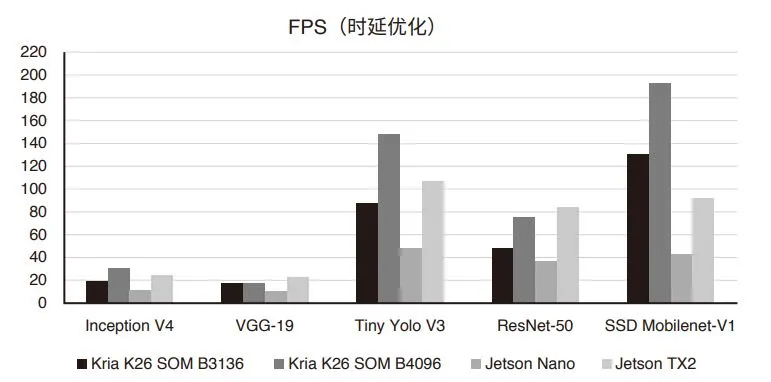
FPS(时延优化)
功耗测量
边缘设备提供最佳性能这点非常重要,但同时必须降低能耗。赛灵思测量了英伟达和赛灵思 SOM 模块在执行具体模型时发生的峰值功率,结果很明显,K26 SOM 优于 Jetson Nano
3.5 倍,优于 Jetson TX2 2.4 倍。

FPS/瓦
实际应用性能比较
为了分析实际用例,我们选择了一种准确检测和识别车辆牌照的基于机器学习的应用。将 Uncanny Vision 行业领先的 ANPR 算法部署在 Kria SOM 上后,与英伟达用 Deepstream-SDK 完成的“车牌识别”的公开数据进行比较,结果说明,Uncanny Vision 的 ANPR 流水线在针对 KV260 入门套件进行优化后,实现了超过 33fps 的吞吐量,显著优于英伟达基准测试中 Jetson Nano 的 8pfs 和 Jetson Tx2 的 23fps。这种前所未有的性能水平为 ANPR 集成商和 OEM 厂商提供了优于竞争对手的开发灵活性。
实际应用测试显示,K26 SOM 不仅在标准性能比较中表现极其优异,并且在为开发者提供加速整体 AI 和视觉流水线所需的原始性能时,效率也更高。通过对比,在标准的基准测试领域之外,竞争解决方案倾向于提供较低效率水平,而且功耗较高。