作为广受青睐的 AI 加速开发平台,Vitis AI 已发布全新版本,并于 6 月 15 日正式推出。
我们一直期待 AI 在不同的工作负载和器件平台上发挥更重要的作用。由于从数据中心到云端都对 Vitis AI 有着巨大的市场需求,因此 AMD-赛灵思着力丰富与强化 Vitis AI 的功能,旨在提供更快的 AI 加速。本文将对 Vitis AI 2.5 的新功能及优化进行概述。
AI 模型库增加更多优化模型
最受欢迎的 BERT-NLP 模型、Vision Transformer、端到端 OCR 模型以及实时 SLAM SuperPoint 与 HFNet模型,都已包含在 Vitis AI 2.5 的模型列表。随着AMD对赛灵思的收购, AMD获得了卓越的软硬件功能,如今,Vitis AI 2.5 在 AMD EPYC 服务器处理器上支持 AMD 深度神经网络 ZenDNN 库中的 38 种基本模型和优化模型。可以想象,更多的 AMD CPU 用户将通过 Vitis AI 解决方案体验更快的 AI 加速方案。
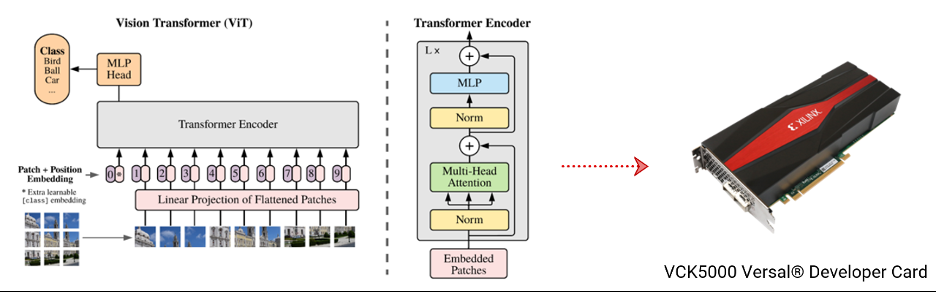
面向数据中心的高效 AI 开发流程
在Vitis AI 2.0中,我们首次增加了“全图形优化器 (WeGO)”这一功能,并在开发者群体中获得了积极的反馈。通过将Vitis AI 堆栈与主流AI框架的集成,WeGO 提供了在云端深度学习处理器单元 (DPU) 上部署 AI 模型的一套便捷的方案。
在Vitis AI 2.5 中,WeGO 支持了 Pytorch 和 Tensorflow 2 等更多种框架。Vitis AI 2.5 版还新增了图像分类、目标检测和分割等 19 个示例,诣在帮助用户在数据中心平台上更顺利地部署 AI 模型。
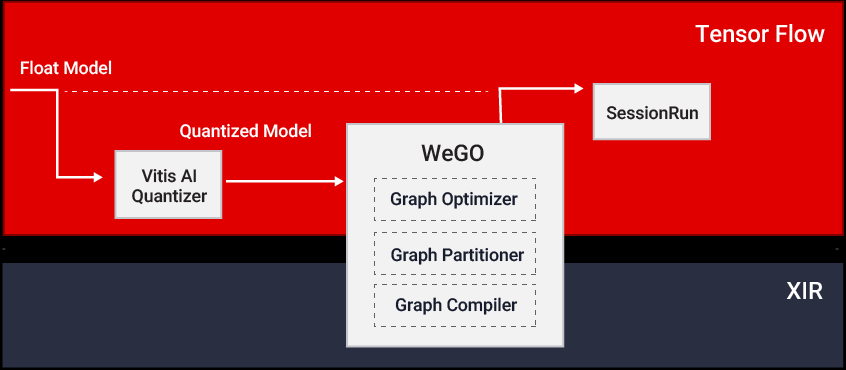
更加优化的深度学习处理器单元和软件工具
AMD-赛灵思平台上卓越的 AI 加速性能离不开一系列强大的加速引擎和易于使用的软件工具。目前我们向主要的FPGA、自适应 SoC、Versal ACAP 以及 Alveo™ 数据中心加速器卡提供可扩展的 DPU。
随着 Vitis AI 2.5 的发布,Versal DPU IP 可支持 Versal AI Core 系列器件上的多个计算单元模式(Multiple compute unit),增加了由新的算术逻辑单元 (ALU) 实现的 Pool 引擎和 Depthwise 卷积引擎,支持大内核尺寸 MaxPool、AveragePool、AveragePool 和 16 位常数权重等新功能。
除此以外,DPU IP 现在还支持更多的网络层组合,如 Depthwise 卷积结合LeakyRelu等模式。
数据中心端 DPU 新增支持更大内核尺寸的 Depthwise 卷积、更大内核尺寸的Pooling、和基于 AI 引擎(AI Engine)的Pooling等。
了解更多
本文仅简要讲解了 Vitis AI 2.5 的主要功能。有关 Vitis AI 2.5的完整介绍,请访问 Vitis AI 2.5 更新。
https://china.xilinx.com/products/design-tools/vitis/vitis-ai-whats-new....
进一步了解 AI 模型库、量化器、优化器、编译器、DPU IP、WeGO 以及整个应用加速 (WAA),请访问 Vitis AI 页面。
https://china.xilinx.com/products/design-tools/vitis/vitis-ai.html
即刻访问 Vitis AI GitHub 页面,可获得试用所需的最新工具和镜像!
https://github.com/Xilinx/Vitis-AI





