本文转载自:本文由半导体产业纵横(ID:ICVIEWS)编译自semianalysis
AMD能在服务器领域实现领跑吗?
由于验证周期长,服务器行业转向新供应商的速度很慢。安全的选择是坚持现有的供应商,无论是几十年前的 IBM,还是现在的英特尔。不过,AMD表示“坚持使用至强并不安全”。

第四代 Epyc Genoa 的发布标志着 AMD 在大多数性能指标上连续三代击败英特尔。Rome和Milan让云玩家开始大量购买 AMD,而Genoa可能会征服剩余的大多数市场和终端用户。SemiAnalysis 认为,Genoa和Sapphire Rapids的差距大于Milan和Ice Lake之间的差距。这种差距只会持续扩大到 2024 年底,但可能会在 2025 年出现 Sierra Forrest 和 Granite Rapids之间减少。
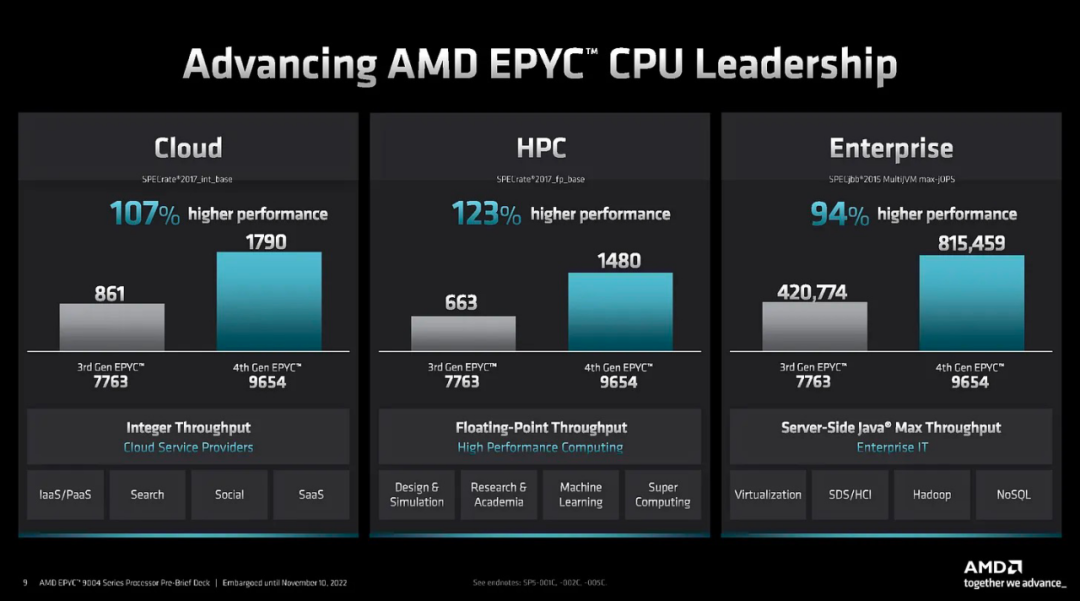
AMD 正在推出越来越多的 CPU 变体。虽然 CPU 用于通用工作负载,但针对各种终端市场的定制正在增加。在第 4 代中,有 4 个变体。Genoa是通用的和主流的。
Bergamo 适用于云原生工作负载。IO die 和平台与 Genoa 共享,所以很多方面都相似,只是将 Zen 4 核心替换为 Zen 4C 核心,它具有相同的核心架构和 L2 缓存,每个核心只有一半的 L3 缓存。Zen 4C 的内核布局以牺牲频率为代价实现密度最大化。
Genoa还将有另一个名为 Genoa X 的变体,用于“技术”。这是一个奇怪的定义,但它适用于计算流体动力学、EDA 和其他需要更多缓存的工作负载。Genoa X 将是 Genoa具有 3D V-Cache 和多个潜在的变体。
Siena是给电信公司和边缘的。由于较低的功率和资本支出需求,我们还会说它适用于某些企业部署。从内存到核心数量,Siena大概是Genoa或Bergamo的 1/2。
最后,AMD 的下一代被称为 Turin,预计将在 2024 年上半年推出。它有更多的系列和变体。

总结一下, Genoa 的性能是 Milan 的 2 倍左右,而功耗只有适度的增加。由于增加了 AVX512 和超大的内存带宽提升,浮点增益更大

规格没有什么大的改变,96 个内核、12 个 DDR5 通道和 160 个 PCIe Gen 5 通道(其中 64 个支持 CXL)。附加 CXL 的内存加密对于多租户云架构的安全性至关重要。CXL 内存 ASIC/设备不需要支持来支持加密,这不依赖于任何特定的 ASIC。

Genoa 的核心是 Zen 4 核心。性能大幅提升,IPC 提高了 14%,由于 L2 大小增加了 2 倍,显著提高了频率和平均延迟。前端占 IPC 改进的 40%,加载/存储改进占 24%,分支预测占 20%,L2 缓存/执行引擎每个是 8%。

AVX512是一个浮点向量指令库。英特尔以 512 位宽实现它,但这也意味着它在芯片层面的成本太高,而且英特尔没有在客户端芯片上包含该功能。此外,当 AVX512 点亮时,芯片的时钟速度会下降,芯片上的其他工作负载也会受到影响。AMD 通过将其拆分为跨 256 位单元的多个周期,走了一条更加智能的路线。这意味着不存在noisy neighbor问题,并且芯片面积影响仍然很小。

安全性总是很重要, AMD 比英特尔具有优势的多个核心和 SOC 级别的安全功能。最值得注意的一个与 SMT 或超线程有关。Ampere Computing 喜欢提出每个内核运行多个线程是不安全的论点。带有 SEV-SNP 的 AMD 正在应对这个问题。如果实现此功能,安全客户线程可以选择在共享核心上有活动的同级线程时不运行。这可以防止旁通道攻击,例如 Spectre 和 Meltdown。
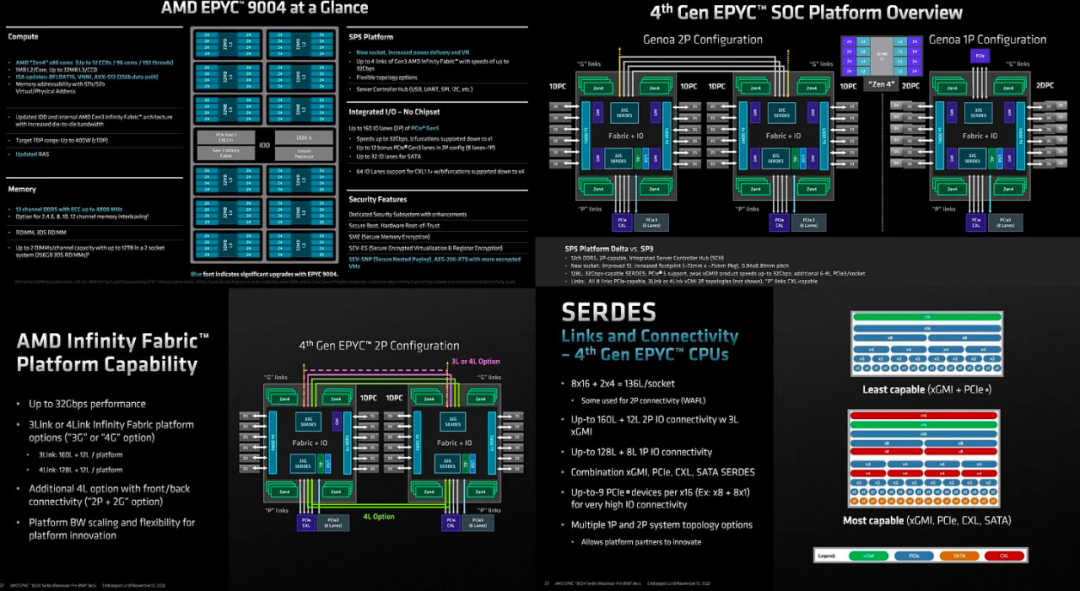
随着第四代 Epyc 的推出,IO Die 可以说是一个更大、更重要的变化。它建立在 N6 进程节点上,而不是像 CPU 小芯片那样的 N5。IO 芯片现在得到了加强,可以通过一个更大的、具有更多层的封装与 12 个小芯片通信。
另一个值得注意的点是插座完全重新设计。安装机制更坚固,引脚间距更窄,为 0.94 x 0.81mm。尺寸从 58mm x 75mm 增加到 72mm x 75mm。对于像 Unimicron 这样的公司来说,更大的封装和更多的层是一件大事
AMD 的 IO 可扩展性非常值得关注。他们使用具有组合功能的 SerDes。从本质上讲,这些 SerDes 可以具有多种特性,使得所连接的选项非常可配置。该平台可以配置 3 个或 Infinity 结构通道,从而在 2S 配置中实现可扩展的 PCIe 通道数。每台 2S 服务器可以有 3 个 Infinity 结构通道和 160 个 PCIe 通道以及另外 12 个用于平台的 PCIe 链路,或者用于平台的 4 个 IFIS、128 个 PCIe 和 12 个 PCIe。每个 16x PCIe 根联合体可以缩减为 9 个 PCIe 设备,其中 1 个 8x 设备 + 8 个 1x 设备。

鉴于Genoa大幅提高 IO 速度,正确利用该带宽至关重要。增强的 AVIC 减少了虚拟化 IO 设备的开销。这可以实现更高的带宽利用率和更少的 CPU 开销。Milan有一个更早的版本,但它更像是原型。现在使用 Genoa,IO 设备具有接近原生的性能。使用运行 InfiniBand 的 Nvidia 的 Mellanox Connect X7 进行的测试。

Genoa在内存成本方面进行了关键改进,这是服务器 BOM 的 50%,这一点不容小觑。
值得注意的是对 72 位和 80 位 DIMM 的支持。大多数服务器将使用 80 位 ECC,但一些超大规模服务器希望减少到 72 位。相对于非 ECC 内存所具有的 64 位,仍有一些 ECC 功能,但比广泛使用的关键任务 80 位要少。这里的优点是用于奇偶校验检查的 DRAM 裸片减少了 1 个。“有界故障”功能也有助于解决此问题,因为如果在存储设备中检测到错误,则可以映射这些问题。
另一个重要特征是双列与单列内存。Milan 和大多数 Intel 平台,双列内存对于最大化性能至关重要。例如,Milan有 25% 的性能增量。在Genoa,这一比例降至 4.5%。这是另一个可观的成本改进,因为可以使用更便宜的单列内存。
Genoa的内存延迟比Milan高,Genoa为 118ns,而Milan为 105ns。AMD 表示,其中只有 3ns 来自更大的 IO 芯片,Genoa为 73ns,而Milan为 70ns。大多数内存延迟影响来自 DDR5 内存设备本身。DDR5 上为 35ns,而 DDR4 上为 25ns。这是由于 DDR5 不成熟、更大的存储库大小以及架构中的其他变化导致的更宽松的时序。内存延迟影响很大,但 SOC 级别的微小增加令人惊讶。

IO Die 到 Core Complex Die 的连接得到了极大的改进。每比特传输的功率降至2pj/bit 以下。作为参考,EMIB 声称为 ~0.5pj/bit。最值得注意的方面是有一个新的 GMI3-Wide 格式。对于客户Zen 4 和前几代 Zen 小芯片,IOD 和 CCD 之间有 1 个 GMI 链接。使用 Genoa,在较低的核心数、较低的 CCD SKU 中,可以将多个 GMI 链路连接到 CCD。这是可用于较低核心数 SKU 的带宽的大幅增加。具体来说,这将有助于关系数据库和高频 SKU,其中每核许可成本很高。
电源管理得到增强。Genoa 有 2 种基本的电源管理模式,性能确定性或电源确定性。由于热和硅的变化,不同芯片上的不同工作负载之间可能存在许多差异。考虑到制造涉及数千个工艺步骤,硅不是确定性的。
性能决定论适用于希望获得持续性能的公司。它在允许的情况下消耗更少的功率,并且性能保持稳定。大多数客户会选择此选项,因为稳定性至关重要。
功率确定性是为了保持功耗稳定并提高和降低性能。考虑到硅抽签、热预算和工作负载等因素,芯片将提高和降低时钟速度。
除了电源管理模式外,Genoa 芯片还有一个可配置的 TDP。峰值提升行为将根据选择的选项而有所不同。时钟提升基于可靠性和峰值功率传输。高活动工作负载将以较低的频率运行。考虑了系统和芯片裕量。与消费级平台相比,功率预算不会长期超出。TDP 只能超过 10 毫秒。
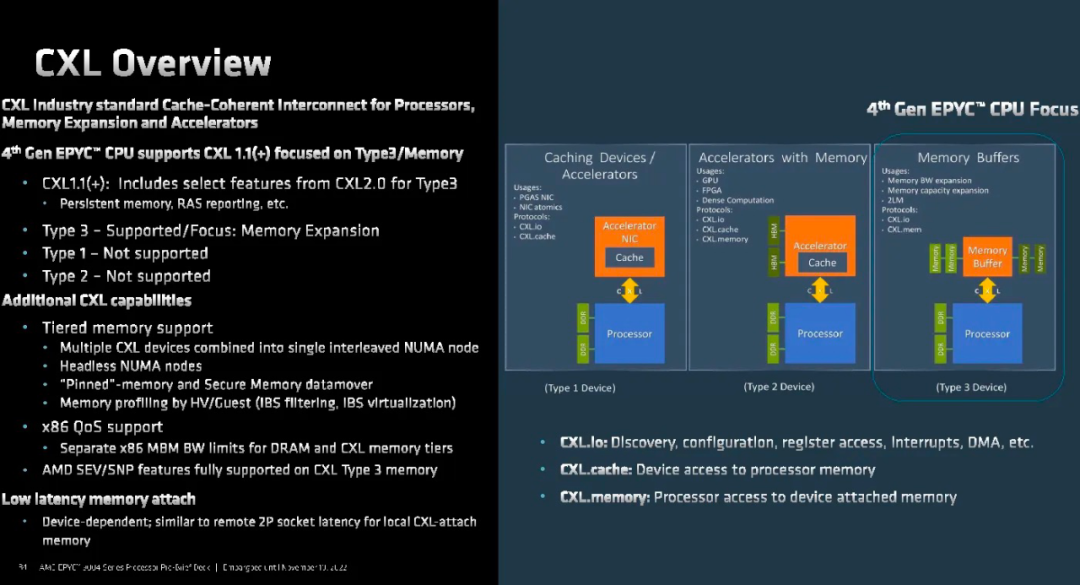
AMD 通常支持 CXL 1.1,但支持 Type 3 内存设备的 CXL 2.0。

值得一提的是,CXL 的 64 个通道可以分成 16 个 4x 器件。Sapphire Rapids不具备 CXL 通道分叉的能力。如果一个连接 4x 或 8x CXL 设备,这将消耗所有 16 个通道。Emerald Rapids 修复了该功能,但那是一年之后的事情。虚拟机管理程序无法更改来宾的内存分配,这对于在云中使用 CXL 附加内存的用户来说是巨大的。
AMD 的性能支柱是每插槽性能领先、每核心性能领先、所有工作负载和细分市场的领先地位,以及 TCO 和可持续性方面的领先地位。
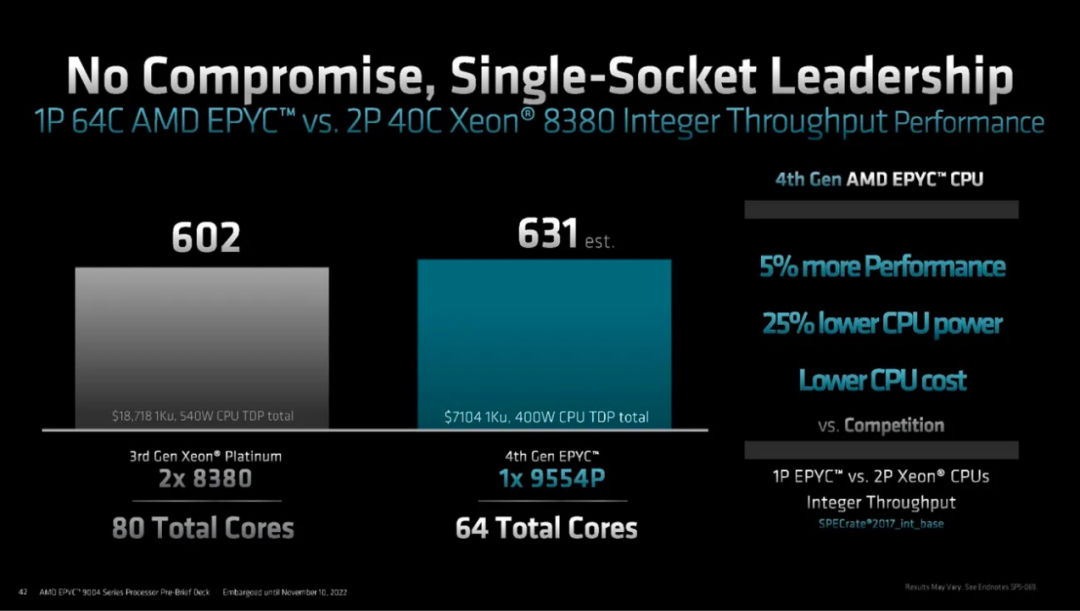
中端 Genoa 芯片与 2 个高端 Xeon 芯片的 1 个比较最好地说明了这一点。AMD 具有更高的性能、更低的功耗、更低的 CPU 成本、更少的内核。
AMD 的领先优势是开创性的。需要注意的一件事是,当每个内核的软件许可成本开始发挥作用时,这种领先优势在 TCO 方面会进一步扩大。这在运行 VMMark 的企业基准测试中得到了最好的体现。VMMark 每个磁贴运行 19 个具有代表性的 VM,然后查看可以运行多少磁贴以及速度。Genoa速度更快,可以处理更多的虚拟机。
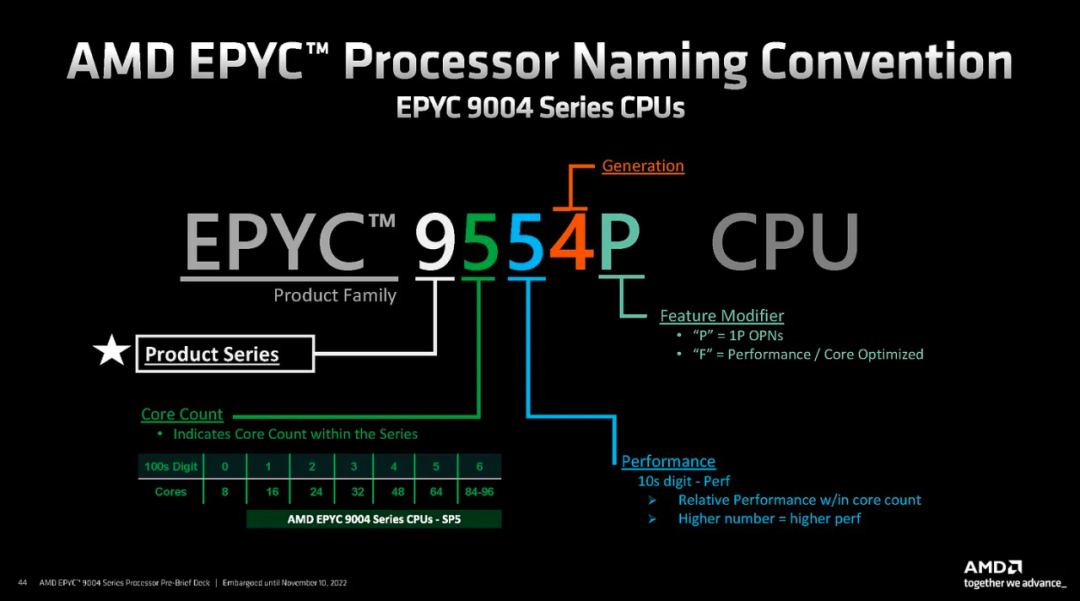
SKU 命名非常简单明了,每个数字都表示关键信息。

AMD 使 SKU 堆栈保持简单。与英特尔不同,没有一堆 SKU 锁定功能。有3个通用类别和18个SKU。核心性能 (F)、核心密度和平衡/TCO 优化。他们基于 1 个插槽与 2 个插槽支持进行细分。每个核心的价格也保持相对平稳。
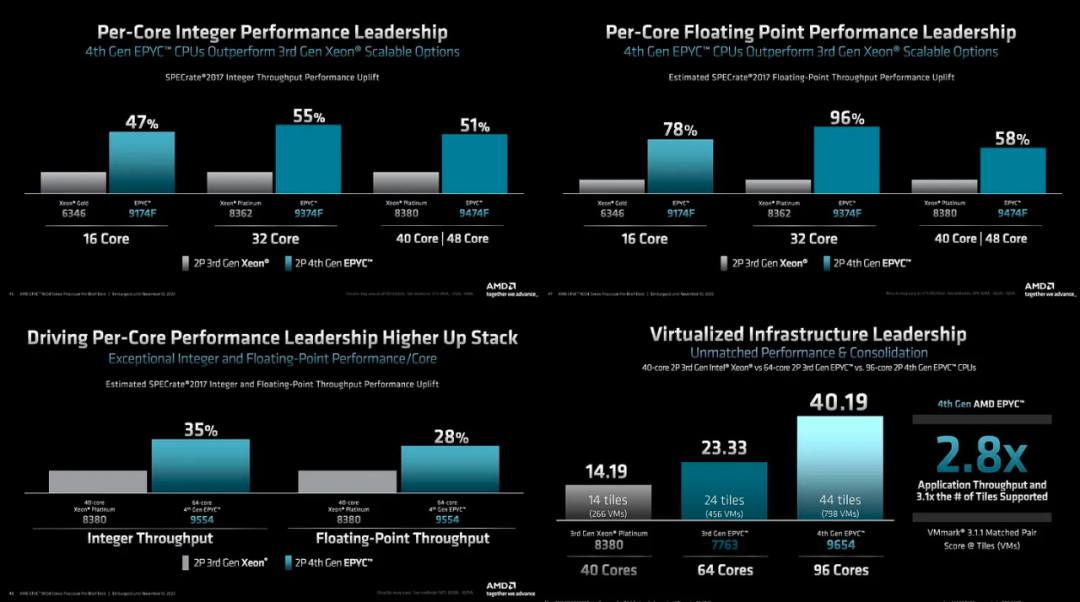
在 Genoa 中,AMD 在整数工作负载上的每核性能领先通常约为 50%,在浮点上则高达 96%,后者大部分是由于内存带宽和缓存。

SQL 基准测试值得注意,因为在一些数据库基准测试中,AMD 由于其较高的核心到核心延迟而落后。他们仍然会在其中许多方面落后,但在一些常用的方面差距正在缩小。Sapphire Rapids 的单片和 4 管芯高级封装方法的优势在于,这些海量关系数据库将大大降低内核之间的延迟。

在 HPC 性能比较中,96C 显示它仍然受到内存带宽的限制,但 32C 与 32C 显示Genoa的带宽优势是巨大的。

服务器整合是这里的重头戏。

如果使用 2P 与 2P 或 2P 与 1P 服务器,数字会有所不同,但结果是相似的。通常 3 个 CPU 合并为 1 个 CPU。

过去,AMD面对着一些问题,如工作负载不会在其中扩展,一些应用程序甚至会崩溃。Genoa拥有如此多的核心,能够访问大多数软件 ISV,因此Genoa结束了过去时期大部分痛苦。

最后一个点是关于机密计算。机密计算意味着软件不需要信任拥有硬件的所有者,同时能够保证数据安全。静态和动态数据,加密是一个很好理解的答案,但在使用中,答案很复杂。虽然Genoa并没有完全实现机密计算的愿景,但它在该领域带来了许多创新,使其更加接近。





