本文由半导体产业纵横(ID:ICVIEWS)编译自semianalysis
Bergamo是AMD 即将推出的 128 核服务器部件,它在 x86 CPU 性能方面树立了新的高度。
Bergamo的架构是云原生的,因为摩尔定律逐渐变得缓慢,它代表了数据中心 CPU 设计中的一个重要转折点。Bergamo 的核心是 Zen 4c,这是其成功的 5nm Zen 4微架构的全新 CPU 核心变体,可推动每个插槽拥有更多核心。
虽然到目前为止 Zen 4c 的官方细节相当少,但 AMD 的首席技术官在他们的Ryzen 7000 主题演讲中这样说:“我们的 Zen 4c,它是我们的紧凑密度的补充,它是我们核心路线图的新赛道,它在大约一半的核心区域提供与 Zen 4 相同的功能。”
在本文的深入探讨中,我们将分享对 Zen 4c 架构、市场影响、平均售价、销量、超大规模厂商订单转换的分析,以及 AMD 如何能够在保持相同核心功能和性能的同时将核心面积减半。
我们将研究为什么AMD 在 CPU 设计中追求这条新道路,以应对市场需求以及来自亚马逊、谷歌、微软、阿里巴巴、Ampere Computing以及英特尔 x86 Atom E内核的基于 ARM 芯片的竞争。

最后,我们看看 Bergamo 降低的生产成本和预期的销量,以及 AMD 未来在客户端嵌入式和数据中心产品线中采用密集核心变体的情况。在深入了解这些市场和架构细节之前,让我们首先谈谈背景。
摩尔定律终结的云CPU时代
Zen 4c 和 Bergamo 的设计背后的基本原理是提供尽可能多的计算资源,同时随着摩尔定律放缓而与硅的物理限制作斗争。尽管要求继续增加核心数量,但这种放缓是一种全行业的现象,给设计师带来了挑战。
随着 AMD 将他们的 128 核 Bergamo 推向市场,其竞争对手英特尔正在准备他们的 144核“Sierra Forest”部分。两者都在响应数据中心ARM CPU 内核的兴起,从亚马逊、谷歌、微软和阿里巴巴的超大规模内部努力到商业硅192核 AmpereOne 云原生CPU。
随着 Generative AI 的兴起,GPU、加速器和 ASIC 风靡一时,资本支出份额不断增加,但不起眼的通用 CPU 仍然是全球大多数数据中心部署的基础骨干。在云计算范例中,最大化计算资源同时最小化总体拥有成本(TCO) 是游戏的名称。
增加内核数量是节省功耗和成本的主要方法之一。插槽整合,即一个新的 CPU 取代四个或更多的旧 CPU,风靡一时。14nm 上有大量22到 28 核英特尔 CPU,耗电量大,需要更换。自 2010 年代中期以来,我们就没有基础架构更换周期,并且云已将服务器的生命周期从 3 年延长到6 年。随着新云原生 CPU 的性能/TCO 改进刺激开发,这种情况很快就会改变。
通过整合,不再需要缓慢且耗电的插座间和网络通信,并且需要更少的物理资源 (风扇、电源、电路板等)。即使在同一代中,两台 32 核服务器从根本上讲也比一台提供相同性能水平的 64 核服务器消耗更多的功率。在云中,使用更少、更大的计算节点在计算网络中启动、关闭和迁移客户端会更简单。
然而,更多的核心意味着更多的功耗。CPU 插座的热设计功率(TDP)在过去 7 年里飙升,从 140W 到 400W。2024平台将破解500W。
尽管如此,热密度增加对功率和冷却的限制意味着 TDP 不会随着内核数量的增加而相应增长,从而导致每个内核的功率预算下降。以高时钟速度和功率运行可最大限度地提高每个内核的性能和每平方毫米硅的性能,这是成本的基本单位。
目前的趋势是任何给定工作负载中,每瓦性能是最重要的因素,因此可以要求显著的价格溢价。看看 AMD 米兰到热那亚的过渡,仅仅由于部署密度和每瓦性能的提高,AMD 就能够要求80% 的价格上涨。
因此,CPU 架构师必须小心平衡其核心设计以优化每瓦性能。与此同时,随着摩尔定律的放缓,每个晶体管的成本与新的工艺节点持平,因此这项任务变得更加困难,因为需要控制晶体管预算和核心尺寸。

工程师在性能、功耗、面积等方面的信息不完善的情况下做出多变量权衡的基本设计决策。在性能、功率、面积(PPA) 曲线的一端是 IBM 的 Telum,它专注于为遗留大型机式应用程序实现每个内核的最大性能。为了为其银行、航空公司和政府客户改进产品,IBM 必须设计巨大的内核、5GHz 以上的时钟速度和最终的可靠性,这对于较新的容器化分布式工作负载来说成本太高。
另一方面是微控制器中的 CPU 和低功耗移动芯片,它们优先考虑能效和最小面积 (成本)。英特尔在智能手机革命中的失败意味着他们缺乏 ARM 在能效优化方面拥有的十年设计经验。
当 Apple 使用 M1 Mac 扩展其架构并击败英特尔时,不同的设计点就体现出来了。多年来,英特尔的高性能 P核变得越来越臃肿,因为他们继续以牺牲功率和面积为代价来追求每核性能和 6GHz 时钟速度。在服务器芯片中以 3GHz 的频率运行相同的核心并不是区城效率的最佳选择。
明年英特尔的 Sierra Forest 将通过将他们的 E-core 设计引入数据中心来解决这个问题。从他们的 Atom 低功耗内核系列衍生而来,英特尔可以为给定的芯片尺寸封装 3-4倍的内核。然而,E-cores 的警告是它们减少了指令集架构(ISA) 功能级别和较低的每时钟指令(IPC),从而导致更差的每核性能和效率。后者被许多工作负载中纯粹的核心数量增加所弥补。
英特尔开始在其客户端产品线中将E 核与 P核结合起来,以提高每平方毫米的多线程性能,ISA 不匹配会导致一些问题,例如在 P核上禁用 AVX-512 并需要硬件线程调度程序来管理工作负载分配到具有截然不同特性的核心。至于全 E 核 Sierra Forest,其重点是提供接近 P核 Granite Rapids 的插槽性能,同时使用更少的硅。它的继任者Clearwater Forest 将在性能和每个插槽的核心数上全力以赴。
回到 AMD,它既没有智能手机经验,也没有独立的低功耗核心血统设计团队。他们的Zen 核心还必须从 5.7GHz 台式机扩展到高效笔记本电脑和服务器。作为对 ARM 和Atom 的回应,他们创建了 Zen 4c。
Zen 4c 是 AMD 设计团队的共同努力,旨在推出个位于性能、功耗、面积(PPA)曲线不同点的内核,以更好地适应数据中心 CPU 工作负载的最新趋势。AMD 采取了相当机智的举措,采用了相同的 Zen 4架构,并在物理设计中采用了多种技巧以节省大量面积。
这意味着相同的 IPC 和ISA 功能级别,简化了客户端的集成。事实上,AMD 还在其低端4nm Ryzen 7000U“Phoenix”移动处理器中悄悄地将一些 Zen4内核替换为 Zen 4c内核。
在贝加莫,Zen 4c 允许 AMD 将核心数从96 增加到 128,同时节省面积和成本。这种设计理念的分歧将在未来几代硬件中增加。
接下来,在最终缩小范围并涵盖成本、ASP、超大规模订单转换、数量和非数据中心环境中的采用之前,让我们先介绍一下具体的技术细节。
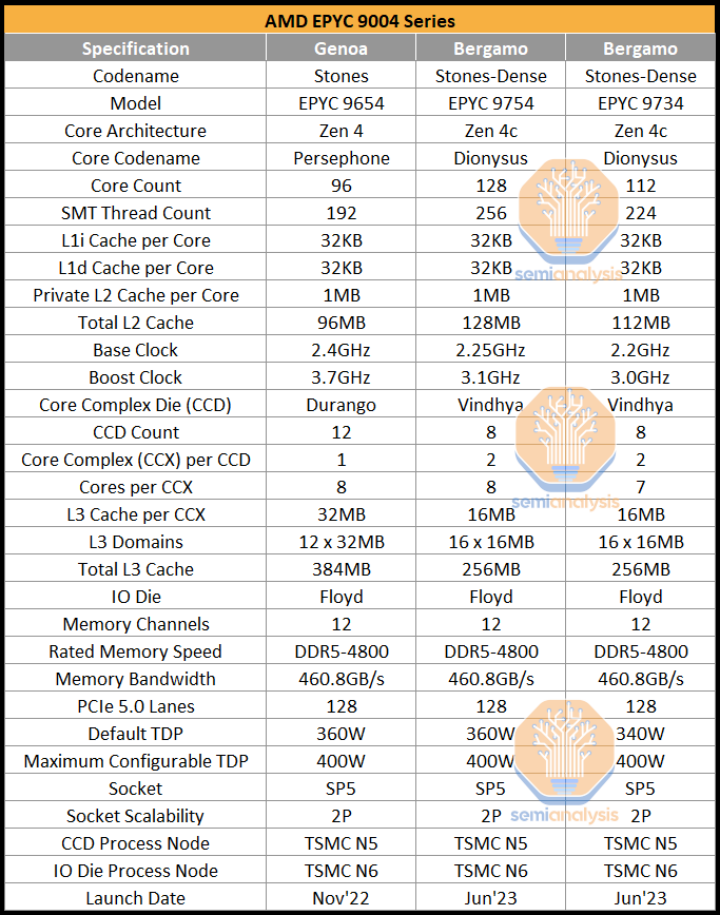
这是贝加莫的规格表及其与热那亚的区别
6 月将推出两种型号:完全启用的 128 核的EPYC 9754和缩减的 112核 EPYC 9734,其中 1/8 Zen4c 内核已禁用。与 Genoa 最好的96核 EPYC 9654相比,Zen 4c 使 Bergamo 能够在相同的 SP5 插槽和 360W TDP 中安装 1.33 倍的内核数。
Zen 4c 拥有与 Zen 4相同数量的私有缓存,具有相同的 L1和1MB L2。保持足够大的私有缓存在云和虚拟化环境中很重要。这有助于通过减少对共享资源的依赖来保持性能一致性。
Bergamo 的时钟速度也有所下降,基本时钟降低了 150MHz、提升时钟降低了600MHz。当然,相同360W 插座 TDP 中的更多内核意味着更低的工作频率。Bergamo在原始 CPU 吞吐量(内核x基本时钟)方面仍然具有 1.25 倍的优势,虽然 Genoa 可以提升得更高,但这只会在较低利用率的情况下有所帮助。Bergamo 专注于云环境,其中可预测的性能是关键,时钟速度的工作范围较低。
与 Bergamo 的另一个主要区别在于裸片和 L3 缓存配置。CCD 的数量从热那亚的 12 个减少到贝加莫的 8 个,这意味着贝加莫的每个 CCD 有 16 个 Zen 4c 内核,而热那亚有8个 Zen 4内核。
Bergamo 还看到了每个 CCD 多个 CCX 的回归,最后一次出现在EPYC 7002“罗马”一代上。这会将裸片一分为二,其中一半的内核只能通过长途往返IO裸片来与另一半通信。
这对性能的影响将在下面详细说明。虽然 Bergamo 的每个 CCX 仍有8 个内核可以进行本地通信,但它们的共享 L3 缓存已减半至 16MB。这种半尺寸的 L3 也出现在 AMD 的移动设计中,以节省面积。虽然这会在某些工作负载中损害 IPC,但这对 Bergamo 来说是有意义的,因为它较少关注共享资源,而更多地关注每平方毫米的性能。那些寻找大型 L3 选项的人可以期待 Genoa-X 及其高达 1152MB 的 L3。
Bergamo 使用与 Genoa相同的IO Die,因此 SP5 插槽IO与DDR5-4800的12通道128条 PCIe 5.0 通道和双插槽能力相同。然而,Bergamo的IO Die 仅连接到 8个CCD,而 Genoa 则为12个,这带来了一个问题:AMD 是否可以制作12 CCD、192核Bergamo?
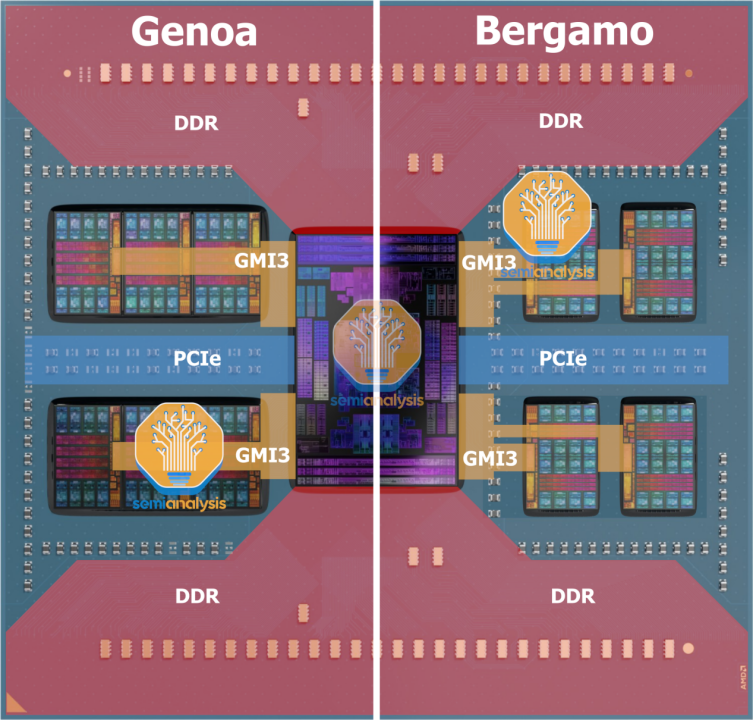
IO 芯片具有 12 个全局内存互连 3(GMI3) 小芯片链路,通过封装基板布线。在Genoa,远离IO Die的 CCD 的 GMI3线布线在较近的 CCD 的L3缓存区域下方。
事实证明,这在 Bergamo 上更加困难,因为 Zen 4c CCD 的更高密度意味着必须使用更多层将电线布线在较近的 CCD 的较小 L3 下方。我们可以通过 CCD 芯片放置看到这个的视觉结果。
在 Genoa 上,每组3个 CCD 并排放置,而在 Bergamo 上,CCD 之间留有间隙,以便为布线留出空间。该封装还在中间布线 PCIe,上下布线 DDR5,因此可用空间不足以容纳 12个 Zen 4c CCD。
模具拍摄、平面图和核心分析
这是 Bergamo的 Zen 4c CCD 的模版,代号为“Vindhya”。这是使用 Zen 4 CCD 的资产制作的,代号为“Durango”,由 AMD 在ISSCC 2023 上提供。请注意两个8核CCXCompute Complexes 彼此并排,每个都有16MB 的共享L3。L3也没有用于 3D V-Cache 的硅通孔(TSV) 阵列,从而节省了一小部分面积。这是有道理的,因为云工作负载不会从大量共享缓存中获益太多。
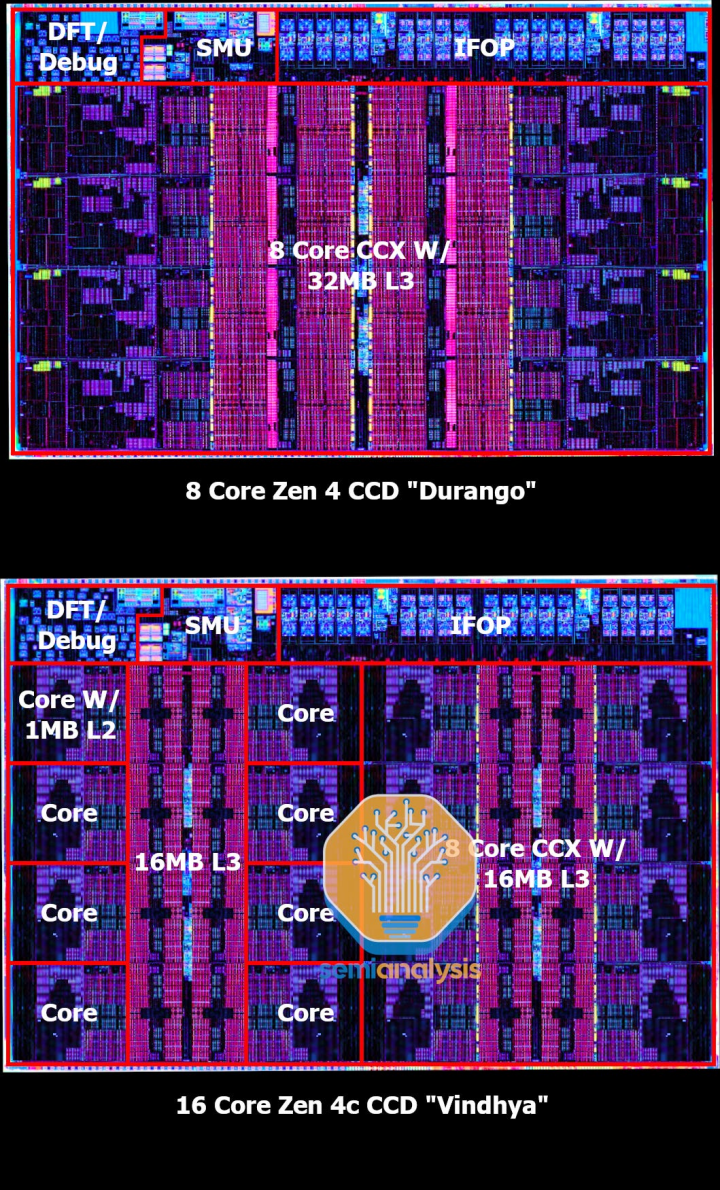
然而,这里真正令人惊叹的是芯片尺寸。16 个 Zen 4c 核心略大于8个 Zen 4核心。在ISSCC 2023 上,AMD 透露 Zen4的 CCD 为 66.3mm2。这是边缘没有芯片密封和划线的设计区域。Zen 4c的CCD设计面积只有72.7mm2,大了不到10%。
请记住,每个芯片上有双倍的内核、双倍的 L2 缓存和相同数量的 L3 缓存。核心必须大大缩小,以便在每个芯片上容纳更多的缓存,而面积只增加了一小部分。
关于小芯片互连,Infinity Fabric on Package(IFOP)在两个芯片上都是相同的,包括两个 GMI3-Narrow 链路。然而,虽然芯片支持它,但似乎没有使用两个 GMI3 链接的Zen 4c 模型。相反,来自两个独立 CCX 的信号通过单个链路多路复用到IO Die。

仔细观察核心会发现设计和布局上的明显差异。下表列出了代号为“Dionysus”的 Zen 4c与代号为“Persephone”的 Zen 4的区域细分。
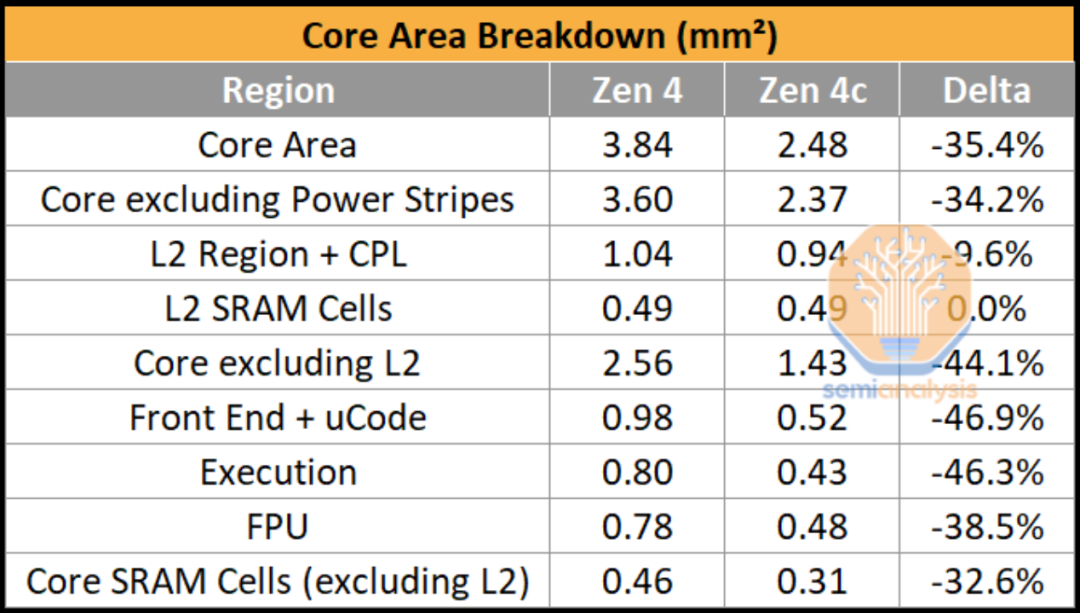
与 Zen4相比,Zen 4c 的核心区域下降了 35.4%,这是非常了不起的,因为它都包含1MB 二级缓存。虽然这意味着 L2 SRAM 单元占用相同的面积,但 AMD 能够通过使L2 控制逻辑更紧凑来减少 L2 区域的面积。不包括 L2 和芯片普适逻辑(CPL) 区域,核心收缩了惊人的 44.1%,引擎 (前端+执行) 区域几乎减半。
这就是 Papermaster 所指的,Zen 4c 的惊人工程壮举与 Zen 4的设计基本相同,具有相同的 IPC,只是实现和布局不同。浮点单元 (FPU)并没有缩小到完全相同的程度,这可能是由于thermal hotspots,因为 FPU 通常在承受重压时是内核中最热的部分。我们还注意到内核本身内的 SRAM 单元看起来也更加紧凑,面积减少了 32.6%。您可以通过右下角的Page Table Walker 清楚地看到这一点。
物理设计技巧
AMD 通过采用完全相同的 Zen 4寄存器传输级(RTL) 描述来创建 Zen 4c,描述了 Zen 4核心 IP 的逻辑设计,并使用更紧凑的物理设计来实现它。设计规则与台积电N5 上的两者相同,但面积差异很大。我们详细介绍了实现这一点的设备物理设计的三个关键技术。
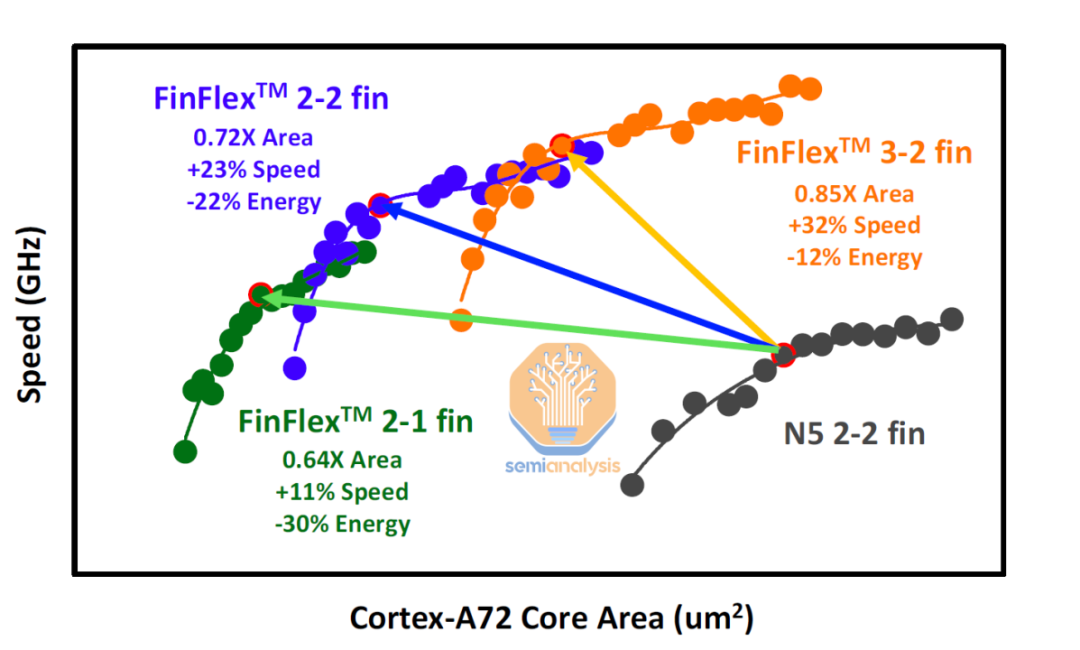
首先,降低设计的时钟目标会导致在合成内核时减少面积。这是在 TSMC 的 N5 和N3E 节点上合成的 ARM Cortex-A72 CPU 内核的速度与面积曲线。即使在同一节点上使用相同的核心设计,也可以选择核心面积和可在其上实现的时钟速度。
通过较低的时钟目标,设计人员在关键路径的设计上有更多的工作空间,从而简化了时序收敛并减少了清除宽松时序约束所需的额外缓冲器单元的数量。现在大多数设计都受到布线密度和拥塞的限制,较低的工作时钟使设计人员能够将信号路径压缩得更近,并提高标准单元密度。

标准单元密度是指设计中可放置区域中标准单元所占的比例。标准单元是功能性电路例如触发器和反相器,它们在整个设计中重复出现并组合形成复杂的数字逻辑。正如贴装软件的这个特写视图所示,它们有许多不同的尺寸。
蓝色矩形是标准单元格,而黑色区域是未填充的。我们突出显示了一个单元密度低、面积利用率约为 50% 的区域,以及另一个单元密度高、超过 90% 的区域。具有大量输入和输出信号引脚的标准单元会占用附近的布线资源,有效地阻塞标准单元放置的相邻空间。
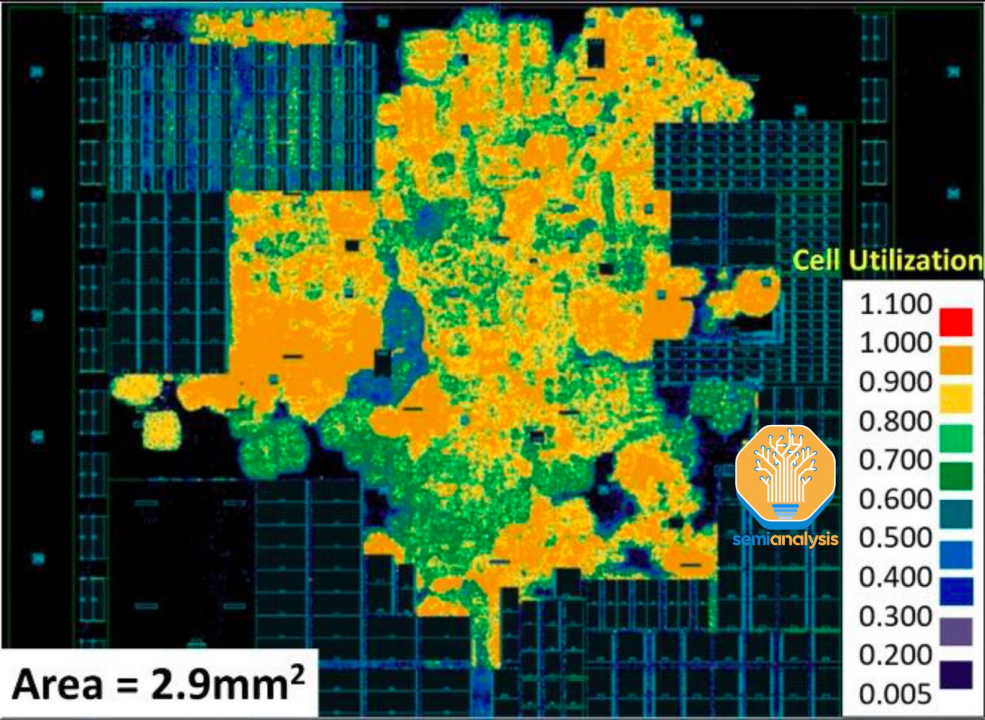
缩小以查看整个核心,可以生成一个单元密度图,该图概述了标准单元紧密堆积的区域(橙色、黄色)和面积利用率较低的区域(绿色、蓝色)。黑色矩形是放置在标准单元之前的大型 SRAM 宏。
这一切意味着 AMD 可以采用他们的 Zen 4核心并通过向下移动速度与面积曲线来直接缩小,并且核心看起来大致相似但具有更高的单元密度。然而,由于下一个物理设计方法,Zen 4c 看起来非常不同。

Zen 4c 看起来非常不同,因为它具有更扁平的设计层次结构和更少的分区。对于具有数亿个晶体管的如此复杂的核心设计,在布局规划中将核心分成不同的区域是有意义的,这样设计人员和仿真工具就可以并行工作以加快上市时间(TTM)。对电路的任何工程更改也可以隔离到一个子区域,而无需为整个核心重新进行布局和布线过程。
有意分离时序关键区域还可以帮助解决路由拥塞问题,并通过更少的干扰实现更高的时钟速度。我们看到 ARM 的 Neoverse V1和 Cortex-X2 内核在逻辑区域之间没有硬分区,布局尽可能紧凑。当查看物理管芯时,这些区域看起来是同质的。另一方面,我们看到英特尔的 Crestmont E-core 有许多可见分区,边界以紫色突出显示。
正如我们在 Zen 4 内核注释中所见,内核中的每个逻辑块都有许多分区,但在 Zen 4c中大大减少,只有4个分区 (L2、前端、执行、FPU)。通过合并 Zen 4中的这些分区,这些区域可以更紧密地封装在一起,通过进一步提高标准单元密度来增加另一种节省面积的途径。可以说 AMD 的 Zen 4c“看起来像一个 ARM 内核”。

最后一种减少面积的方法是使用更密集的内存。Zen 4c 减少了内核本身的 SRAM 面积,因为 AMD 已改用新型 SRAM 位单元。图为具有8 个晶体管的 8T SRAM 电路图中间的 4个晶体管用于存储1位信息,而2 对存取晶体管为2对字线和位线供电。
高性能的Out-of-Order核心具有多种功能,可以从同一块内存读取和写入,因此使用了这些8T双端口bitcells。与更密集的6T 单端口位单元相比,它们占用更多区域并且需要双倍的信号路由资源。
为了节省面积,AMD 用台积电开发的新 6T 伪双端口位单元取代了这些 8T 双端口位单元。
采用 5nm 技术的 4.24GHz 128X256 SRAM 操作双泵读写相同周期的相关论文中,台积电提出了一种具有单端口6T bitcell宏的高速1R1W 双端口32Kbit(128X256)SRAM。
提出了一种具有 TRKBL 旁路的先读后写(RTW)双泵 CLK 生成电路,以提高读取性能。采用双金属方案以提高信号完整性和整体操作周期时间。读出放大器中引入了本地互锁电路(LIC),以降低有功功率并进一步推动 Fmax。结果表明,在 5nmFinFET 技术中,慢角晶圆能够在 1.0V 和 100 摄氏度下达到 4.24GHz。
从描述中我们看到,台积电可以通过在同一时钟周期内进行顺序读写操作来模拟双端口位单元。虽然这不如两个独立的访问端口灵活,但面积的减少足以让 AMD 为Zen 4c 采用该技术。随着SRAM 面积缩放趋于平缓,我们将看到更多此类面积节省技术的发展。





