本文转载自:寒听雪落的CSDN博客
一,Vitis-AI 概述
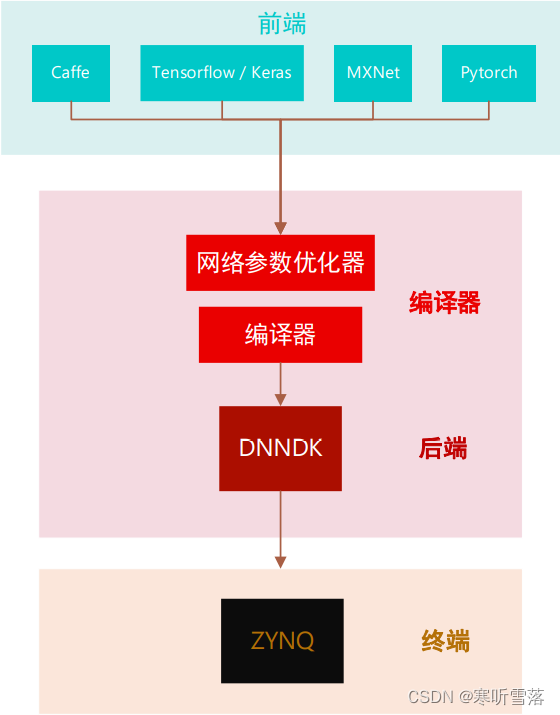
Vitis-AI在边缘计算设备的AI全栈部署框架中扮演了编译器端与后端的角色,接收前端 DNN (Deep Neural Network ) 框架训练后的网络参数IR(Intermediate Representation),并将其优化后编译并传递给后端。后端 DNNDK(Deep Neural Network Development Kit)为 Edge 终端提供了驱动和 API,还有调试运行的工具库。
二,DPU简介
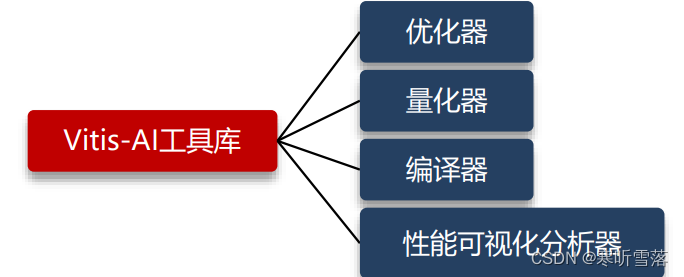
围绕着DPU的应用框架,Vitis-AI 开发环境中包括了 Vitis-AI 开发套件(DNNDK),用于在 Xilinx ZYNQ 系列的边缘或云端硬件平台上进行 AI 推断。DNNDK 由已优化的 DPU IP 核、深度神经网络 模型库、运行库与工具库构成。其中,Vitis-AI 提供的工具包括以下组成部分。
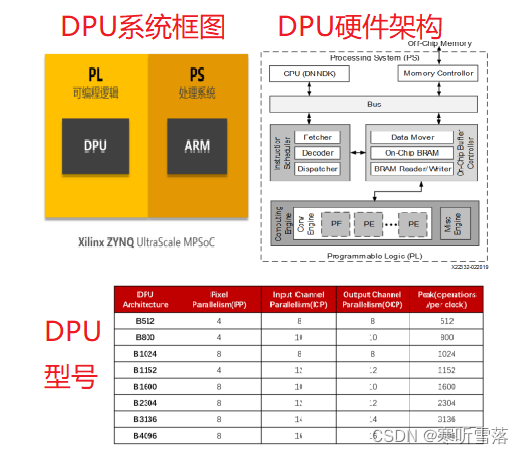
Xilinx深度学习处理器单元DPU是专用于卷积神经网络CNN加速的可编程引擎.DPU拥有专门的指令集,它使DPU可以高效地为许多深度神经网络的卷积部分提供运算任务。 DPU IP 可以作为模块集成到所选ZYNQ 器件的可编程逻辑PL中,并通过AXI总线连接到处理系统PS中。DPU可以访问的特定内存地址中输入的图像数据。此外DPU操作还需要 ARM 处理中断以协调数据传输。
DPU是位于PL端的用于卷积神经网络运算的专用处理器IP核 。启动后DPU从片外存储器中获取指令以控制计算引擎的操作。经优化的指令由DNNC生成,片上存储器用于缓冲输入,过程数据与输出数据,实现高吞吐量和效率。尽可能重用数据以减少内存带宽。深度流水线设计用于计算引擎。
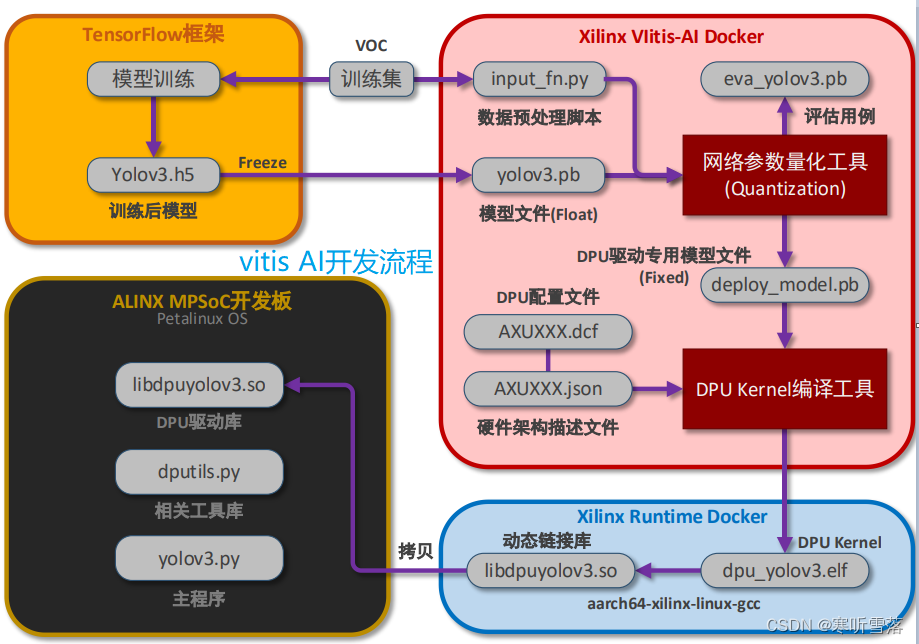
Vitis-AI开发工具中包含了DNN参数的量化工具与DPU Kernel编译工具。 下图将以车辆检测 DEMO为例,演示从YOLOv3模型参数文件的接收到在开发板上运行推断的完整开发流程。
三,网络参数的量化校准(Quantization&Calibration)
神经网络在主流框架训练完成后可导出网络模型.pb 文件,它包含了模型的参数信息。DPU导入该参数信息前,首先需要将其量化,即浮点数定点化。定点化过程中需要输入无需标签的测试集。

准备工作:网络结构可视化。使用Netro工具查看网络结构。
首先安装 snap 平台,然后安装可视化工具 Netron。
sudo apt-get install snapd
sudo apt-get install snapcraft
sudo snap install netron
在目录 Compile_Tools/下启动以分析网络参数文件:netron float/yolov3_voc.pb
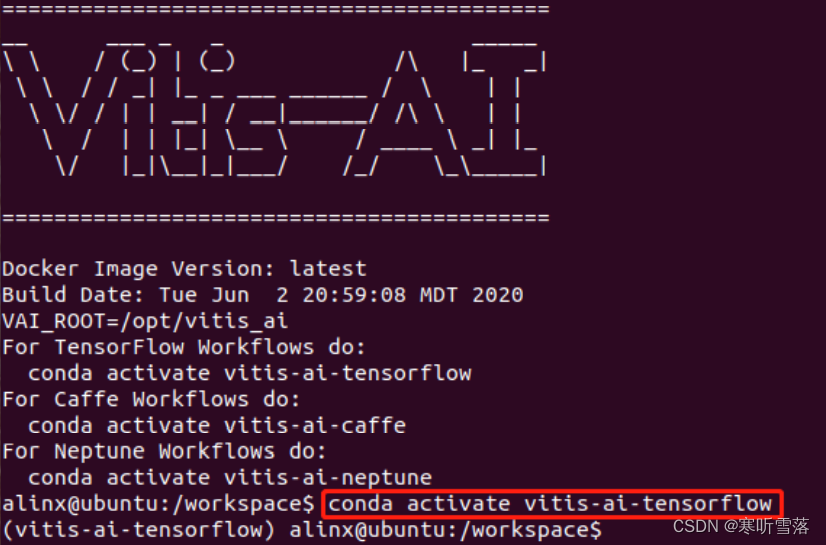
进入Vitis-AI Docker,输入如下命令激活Anaconda的tensorflow环境。注意,下面在Vitis-AI开发流程中,带有符号 vitis-ai-docker:$的命令都是在该环境中完成的。
vitis-ai-docker:$ conda activate vitis-ai-tensorflow
量化需要测试集数据来进行校准Calibration,预先准备好了校准用的数据集 Compile_Tools/model/vehicle/JPEGImages 。 此外 , 运行该脚本需要同路径下提供的 input_fn.py文件,它负责指示数据集的路径和图像数据的输入格式处理,用于与量化工具入口对接。进入路径 Compile_Tools/,运行source 1_tf_quantize.sh命令进行量化操作,打印信息如下:

分析:使用编辑器打开脚本 1_tf_quantize.sh,我们可以看到其中指定了网络的1个输入与3个输出节点。其中,输入与输出节点可在上文步骤中打开的Netron页面中单击该节点以查看节点名。
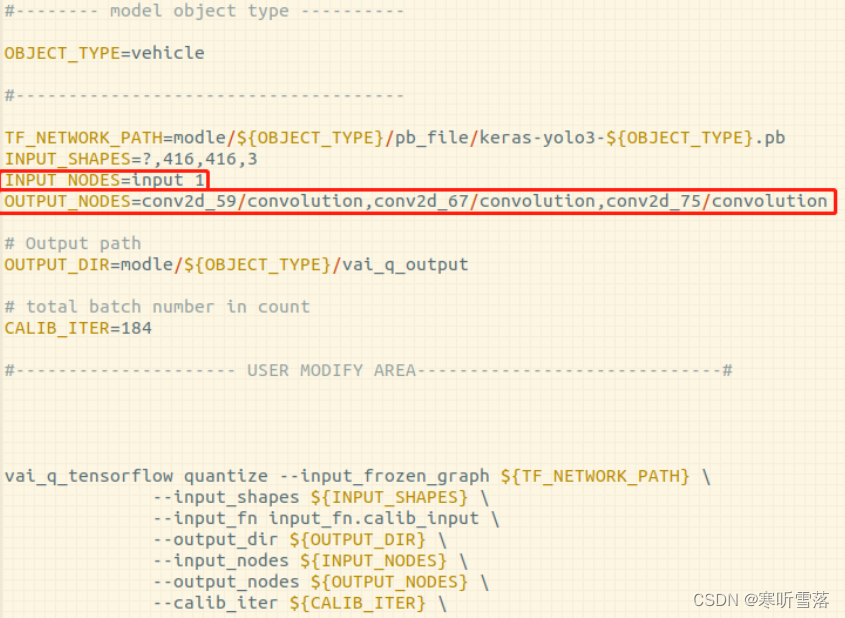
输入节点:input_1

输出节点:conv2d_59/convolution。和conv2d_67/convolution 和 conv2d_75/convolution。

四,DPU Kernel的编译
得到量化后的deploy_model.pb之后,现在进入DPU Kernel编译阶段,此外还需路径 Compile_Tools/device/AXU*器件名*_*DPU 型号*/下对应的.dcf 配置文件和.json描述文件。其中, 由于json已经描述了 dcf 文件的位置,编译时仅需包括.json文件即可。文件中需要输入绝对地 址,确认.dcf路径无误。注意:此时在docker中,根目录为/workspace。回到路径Compile_Tools/下,查看2_vai_compile.sh,确认.json的路径无误。(其中TARGET为器件名)
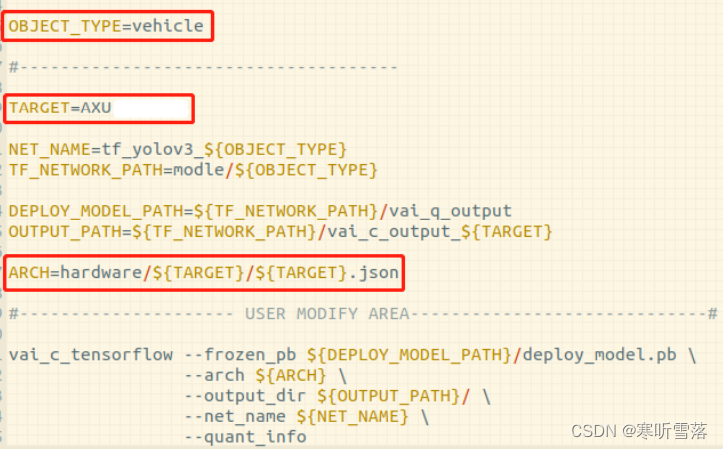
1. 执行指令编译DPU Kernel:source 2_vai_compile.sh
完成后生成的路径为model/vehicle/c_output_*器件名*_*DPU 型号*/ dpu_tf_yolov3_vehicle.elf。同时会打印 DPU kernel(yolov3)的相关信息
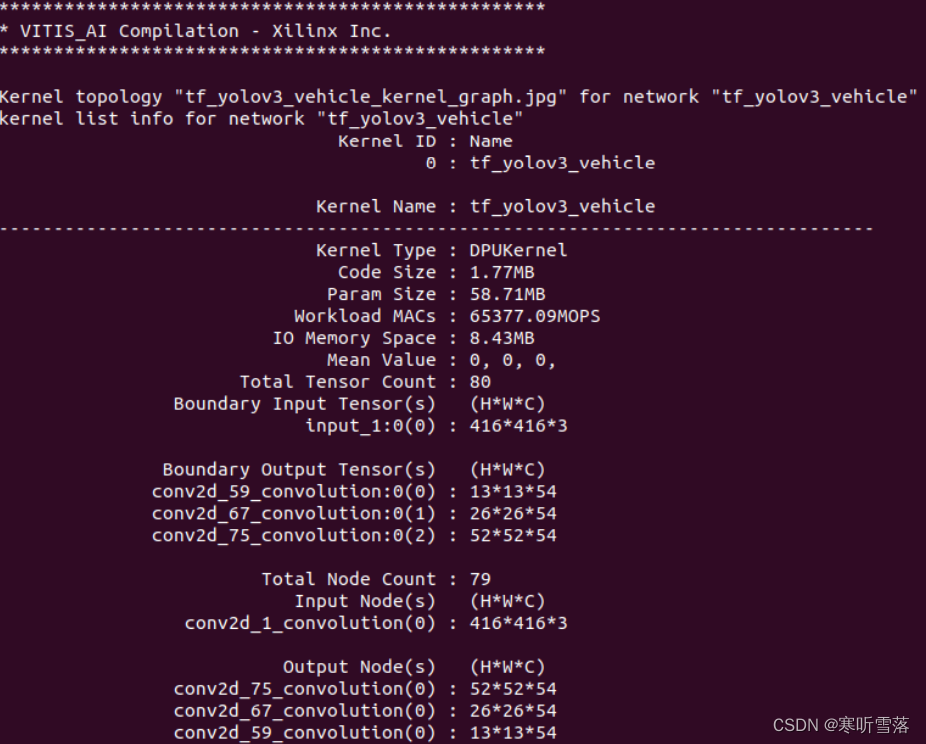
2,调用DPU Kernel分析工具:ddump -f dpu_tf_yolov3_voc.elf -a
Xilinx Vitis-AI中提供了一整套分析与 Debug 工具,其中包括了对生成包含DPU Kernel的.elf 文件的分析工具DDump,具体相关在后文附录中会给出。这里我们在.elf 生成的文件目录下, 使用 DDump 查看.elf 中yolov3 Kernel中包括输入输出接口在内的全部信息。
五,动态链接库.so文件的生成
有了.elf 文件之后,下一步需要交叉编译,用于生成动态链接库.so文件。它包含了yolov3 kernel,只需要python应用程序的驱动即可在目标板上进行yolov3推断。
1. 首先,我们需要下载新的Xilinx Runtime docker来使用64bit ARM GCC交叉编译工具链。启 动新的terminal窗口,在主 Vitis-AI 路径 Vitis-AI/目录下找到如下命令脚本下载并运行该docker。首次启动需要下载大小为3GB左右的镜像分包,下载时间取决于网络环境。
执行:./runtime-docker.sh
2,Runtime Docker启动完成后,回到实验工程目录下的Compile_Tools/找到并打开脚本 3_lib_compiler_runtime.sh,确认.elf 文件的路径是否正确(在 docker 环境下的路径),注 释掉最后一行。注意,带有符号runtime-docker:$的命令都是在Runtime Docker中完成的。

确认完毕后运行该脚本,进行交叉编译 :source 3_lib_compiler_runtime.sh
执行完毕后,会在.elf 文件所在的位置生成在目标板运行yolov3所需的.so文件(DPU Kernel 文件),将其拷贝至实验工程目录下的code/deploy_in_board/Alinx_DNN/ tf_yolov3_vehicle_deploy/。至此,为了在目标板上运行 yolov3 推断,在进行的 host 主机端PC的准备工作已经全部完成。

七,目标板petalinux系统镜像启动与初始化设置
应用程序 DEMO 部署:在PC端实验工程目录下的code/deploy_in_board/,将DEMO集目录 Alinx_DNN拷贝在目标板,由于测试图片较多,需要较长时间。目标板ip地址可用ifconfig命令查看
scp -r Alinx_DNN root@:~/
DNNDK 工具安装:在目标板上运行推断程序需要安装 DNNDK 工具支持。进入目标板系统,打开 terminal,进 入 Alinx_DNN 找到压缩的 dnndk 安装包,解压和安装步骤如下:
sh-5.0# cd Alinx_DNN
sh-5.0# tar -xzvf vitis-ai_v1.2_dnndk.tar.gz
sh-5.0# cd vitis-ai_v1.2_dnndk
sh-5.0# ./install.sh
八,在目标板上运行yolov3推断程序
确认 tf_yolov3_voc_deploy 文件夹里已有.so 文件,与要执行的 python 文件为同一路径。 本例所使用的是车辆识别网络,使用的测试集为车辆。接下来运行yolov3

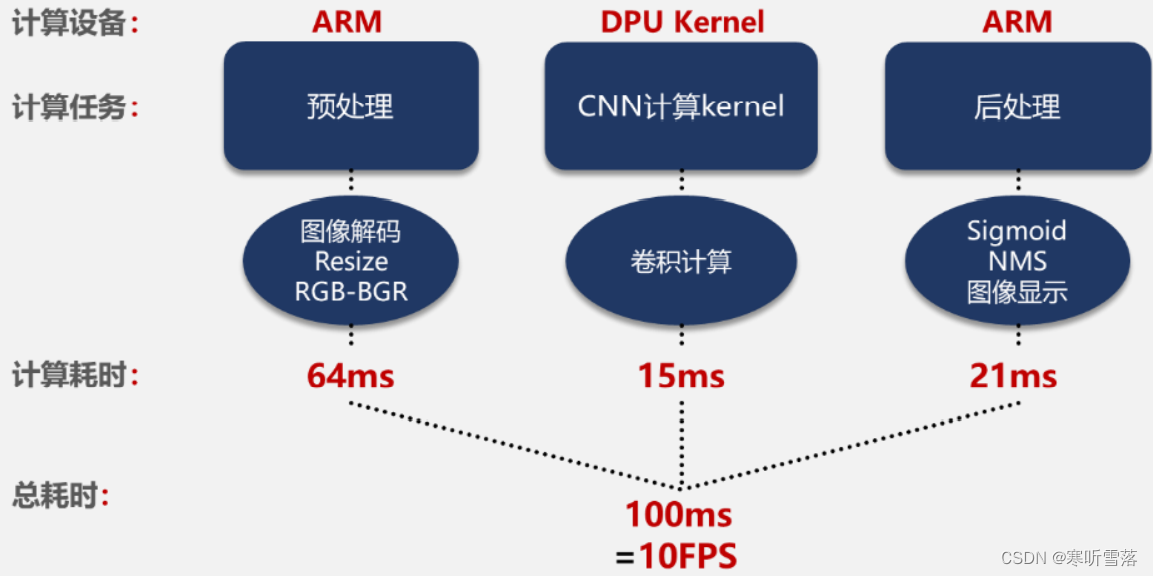
推断程序分析:通过工具可将.pb 文件编译成动态链接库,在目标板上 ARM 端使用 DNNDK API (Python) 将 预处理完成后的图像输入 DPU,并通过 API 获取 DPU 卷积运算后的数据。下图为目标板进行边缘计算任务的流程:
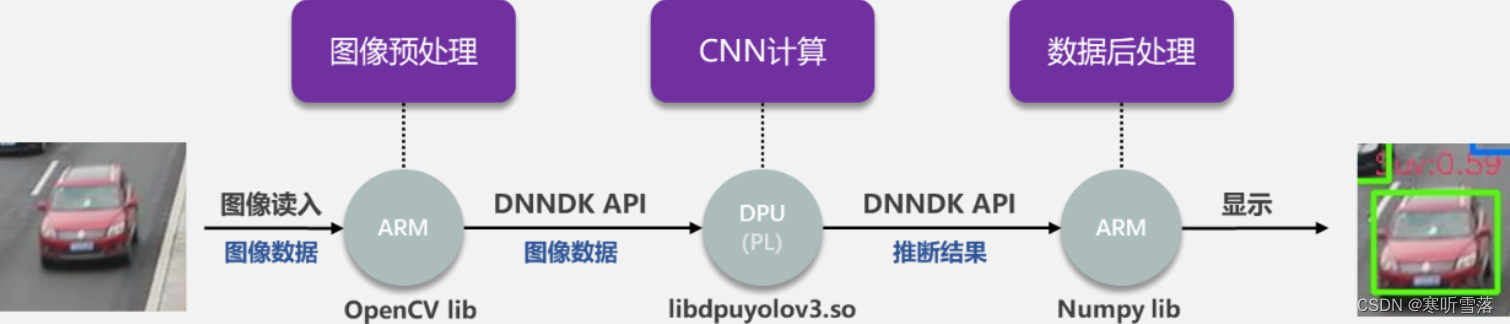
将编译好的动态链接库.so 与应用程序放在同一目录下,使用 DNNDK API 对.so 进行解 析,让 DPU 参照库文件按照我们预定的方式运行,最后使用 API 从 DPU 划分的内存中取出数据, 后处理后得到目标的坐标与类别信息并显示。经过测试评估,计算任务的平均耗时如下图所示: