Vitis™ AI 是赛灵思开发套件,用于在赛灵思硬件平台上进行 AI 推断。机器学习中的推断是计算密集型流程,需要大量存储器带宽以满足各种应用的低时延和高吞吐量要求。
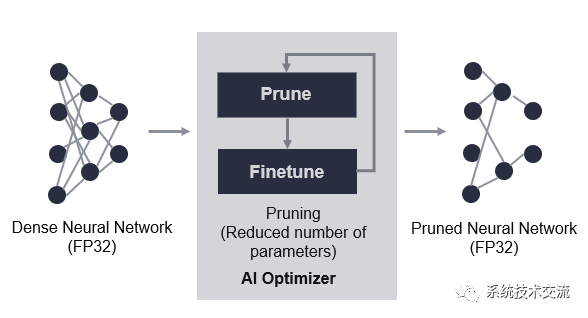
Vitis AI Optimizer(优化器)支持对神经网络模型进行最优化。当前,Vitis AI 优化器仅包含一项工具,称为“pruner”(剪枝器)。Vitis AI 优化器用于移除神经网络中的冗余内核,从而减少推断的总体计算成本。由 Vitis AI 剪枝器所生成的剪枝后的模型随后由 Vitis AI 量化器进行量化,然后部署到赛灵思 FPGA、SoC 或 ACAP 器件。
Vitis AI 为 Vitis AI 优化器提供了 Docker 环境。要构建并运行 Docker 镜像,请参阅 https://github.com/Xilinx/Vitis-AI#installation 文档中的“GPU Docker”部分。在 Docker 镜像中,有以下 Conda 环境可供使用:
Docker 镜像会将对这些框架进行剪枝所必需的工具和库加以封包。如果您有许可证,可以在 Docker 图像中直接运行 Vitis AI 优化器。
剪枝
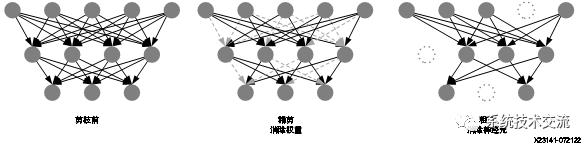
凭借高精度剪枝,可将对输出影响最小的权重设为 0,以便从推断图中跳过或移除对应的计算。这会得到稀疏矩阵(即,具有大量 0 元素的矩阵)。高精度剪枝能够以极低的准确度损失达成极高的压缩率。但能够实现高精度稀疏性的硬件加速器必须采用完全自定义的流水打拍实现,或者采用通用的“处理引擎矩阵”类型的加速器并添加专用硬件搭配权重跳过和压缩技巧。
Vitis AI 稀疏性剪枝器能在 M 值的每个连续块内为多种 N:M 稀疏性模式实现高精度稀疏剪枝算法。N 值必须为 0。在密集网络上,将对权重或激活进行剪枝以满足 N:M 结构的稀疏性条件。剪枝是沿输入通道维度来执行的。每 M 个元素中的最小的 N 个元素都将设为 0。M 的典型值是 4、8 或 16,N 将设为 M 值的一半,以达成 50% 的高精度稀疏性。这样自然即可得到高精度的 50% 稀疏性。
Vitis AI 稀疏性剪枝器支持为卷积层和完全连接的层设置权重和激活稀疏性。激活的稀疏性可为 0 或 0.5。当激活的稀疏性为 0 时,权重的稀疏性可设为 0、0.5 或 0.75。当激活的稀疏性为 0.5 时,权重的稀疏性(每个块中 0 权重的百分比 (M))只能设为 0.75。在 TensorRT™ 中可使用 NVIDIA® A100 GPU 来运行 M = 4、激活稀疏性 = 0 且权重稀疏性 = 0.5 的剪枝网络。
低精度剪枝
低精度剪枝也称为通道剪枝,其目的是对通道进行剪枝而不是对来自图的个别权重进行剪枝。结果可得计算图,其中对于给定层次,有一个或多个卷积内核无需计算。例如,剪枝前具有 128 条通道的卷积层在剪枝后可能只需计算 57 条通道。
通道剪枝十分适合硬件加速,可适用于几乎任何推断架构。但低精度剪枝在可达成的总体计算成本缩减(剪枝比率)方面受到限制。
低精度剪枝始终会降低原始模型的准确度。重新训练(精调)会对剩余权重进行调整以恢复准确度。此技巧对于具有常用卷积的大型模型(例如,ResNet 和 VGGNet)很有效。但对于 MobileNet-v2 之类的逐通道卷积模型,剪枝后的模型准确度会显著下降,即使剪枝率很小也是如此。

剪枝器旨在减少模型参数数量,同时尽可能降低准确度损失。这是通过迭代方式来完成的,如下图所示。剪枝导致准确度降低,重新训练可恢复准确度。剪枝随后重新训练即构成一次迭代。在剪枝的首次迭代中,输入模型是基线模型,并且已经过剪枝和精调。在后续迭代中,从先前迭代所获取的精调后的模型会变为新的基线。此进程通常会重复数次,直至获取期望的稀疏模型。迭代方法是必需的,因为在单次传递中无法在维持准确度的同时进行模型剪枝。如果一次迭代移除的参数过多,那么准确度损失可能过于剧烈,可能无法恢复。


以下提供了剪枝结果最优化建议的列表。经验证,遵循这些准则进行操作有助于开发者提升剪枝率同时减少准确度损失。
神经架构搜索
神经架构搜索 (NAS) 的概念是对于任意给定推断任务和数据集,在潜在设计空间内都存在多个网络架构,这些架构不仅有效而且具有极高的精度得分。通常开发者从熟悉的标准主干(例如,ResNet50)开始,并对该网络进行训练以得到最佳准确度。但在许多情况下,计算成本低得多的网络拓扑即可提供相似或更好的性能。对于开发者而言,使用相同数据集来训练多个网络(有时最多局限于使其成为训练超参数)并非选择最佳网络拓扑的有效方法。
NAS 可灵活应用于每个层次。通过最大程度减少剪枝后的网络损失,即可知晓通道数量或稀疏度。NAS 能在速度与准确度之间达成良好的平衡,但需要大量时间进行训练。此方法需执行四步式进程:
1. 训练
2. 搜索
3. 剪枝
4. 精调(可选)
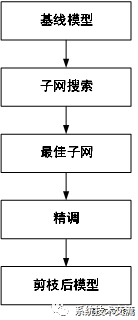
相比于低精度剪枝,一次性 NAS 实现可将多个候选“子网络”汇编为单个过度参数化的图 (graph),称为“超网”(Supernet)。训练最优化算法会尝试使用监督学习对所有候选网络同时进行最优化。完成此训练进程后,候选子网络会基于计算成本和准确度进行排名。开发者可选择满足自己要求的最适合的候选子网络。对于可实现逐通道卷积和传统卷积的模型而言,一次性 NAS 方法能够有效压缩此类模型,但所需训练时间长,并且对开发者的技能要求更高。
单步剪枝
单步剪枝会实现 EagleEye 1 算法。它仅通过采用了一个简单而又高效的评估组件,就得以在不同的已剪枝模型及其对应精调准确度之间引入强大的正关联,这个组件名为自适应批量归一化。它使您无需实际进行模型精调,即可获取可能达成的准确度最高的子网络。简而言之,单步剪枝方法会搜索一群满足所需模型大小的子网络(即,生成的剪枝后模型),并选择其中最有潜力的子网络。随后,通过对所选子网络进行重新训练来恢复准确度。
剪枝步骤如下所示:
1. 搜索满足所需剪枝率的子网络。
2. 从一群具有评估组件的子网络中选择潜在网络。
3. 对剪枝后的模型进行精调。
Once-For-All (OFA) 1 是基于 One-Shot NAS 的压缩方案。您经常会执行诸如压缩训练模型并将其部署到一个或多个器件上之类的任务。传统方案要求您为每个器件重复网络设计进程,并从头开始重新训练设计的网络,但由此会导致难以承担的计算成本。
OFA 引入了全新的解决方案用于克服这一难题:即设计 Once-For-All(一次训练多次部署)网络,此网络可在多种多样的架构配置之下直接部署。故而可以分摊训练成本。只需选择 Once-For-All 网络中的一部分即可执行推断。
OFA 可以在远超剪枝的更多维度内降低模型大小。它可以构建一系列不同深度、宽度、内核大小和图像分辨率的模型,并对所有候选模型进行联合最优化。经训练后,进化搜索即可发现在准确度与吞吐量之间达到最佳平衡的子网络。
对于原始模型中的每一层,Vitis OFA 允许您使用任意通道剪枝率和任意内核大小。原始模型拆分为具有共享权重的众多子网络,并成为一个超网络。子网络可以执行前向传递,并使用卷积权重的一部分进行更新。所有子网络都应在训练期间进行联合最优化。当所有子网络都妥善完成训练后,您可从超网络中搜索已达成准确度与吞吐量的最佳平衡的子网络。
为了获得最高压缩率,Vitis OFA 剪枝器可以基于逐通道卷积数量与常规卷积数量的比率来最优化搜索空间。如果逐通道卷积数量超过常规卷积数量,那么 Vitis OFA 剪枝器主要对内核大小 > 1 的卷积层进行压缩。这将导致超网络中通道宽度狭窄且准确度下降。
OFA 使用原始模型作为教师模型来指导子网络的训练。知识蒸馏允许将教师模型的输出用作为软化标签,以提供有关类内和类间的更多信息。Vitis OFA 使用自适应软知识蒸馏损失 (KDLoss 2 ) 和三明治规则 3 来改善性能和效率。相比于原始 OFA,Vitis OFA 可将训练时间减半。
本文来源于Vitis AI 优化器用户指南 (UG1333),仅用于分享学习
本文转载自:系统技术交流





