Vitis High-Level Synthesis (HLS) 是Xilinx公司推出的一款基于C++等高级语言的开发工具,由Vivado HLS升级而来,它能够将高级语言转化为RTL语言,目的是针对大数据、AI、云等新兴领域,面向软件开发者,加快开发和验证速度。就三五年内而言,其在resource、latency、timing等方面必然是比不上直接进行RTL设计,但是它的优势在于极大的提高了开发、验证效率,大幅度降低了上手和开发的时间成本。
当然,现在的HLS工具还不能完美的直接将C++转化为RTL,需要coder在代码设计过程中具有一定的硬件思维,同时加入合理的optimization directives(HLS pragma),使结果更加符合预期。
下面介绍了一些directive,仅供参考,当然在手册ug902中还能找到更加详细的介绍,在github中的Vitis Libraries中还能看到大量的应用实例。
1. unroll,如下代码所示,unroll是将for循环内的代码展开成8份,也相当于使用8倍的资源去实现这个结构。factor指定的unroll份数必须是可以被循环次数整除的数。factor也可以省略,default时unroll份数就是循环次数。
for(int i=0;i<16;i++){
#pragma HLS unroll factor=8
x[i] = y[i];
}
2. 一个比较经典的方式来展示templete参数,unroll、dataflow使用的例子,如下所示,它实现了N个testCore模块并行执行。
templete
void design(int value[N]){
#pragma HLS inline off
#pragma HLS dataflow
for(int i = 0; i < N; i++){
#pragma HLS unroll
testCore(value[i]);
}
}
3. array partition:
int a[32];
int b[16][1024];
// a 不用partition即可做到ii=1
for(int i = 0; i < 16; i++) {
#pragma HLS pipeline ii = 1
a[i] = i;
}
// a 需要cyclic partition成4份才能做到ii=1 (这里不考虑双端口的情况)
#pragma HLS array_partition variable = a cyclic factor = 4
for(int i = 0; i < 8; i++) {
#pragma HLS pipeline ii = 1
for(int j = 0; j < 4; j++) {
a[i*4 + j] = i;
}
}
// a 需要block partition成4份才能做到ii=1 (这里不考虑双端口的情况)
#pragma HLS array_partition variable = a block factor = 4
for(int i = 0; i < 8; i++) {
#pragma HLS pipeline ii = 1
for(int j = 0; j < 4; j++) {
a[i + j*8] = i;
}
}
// 一次性全展开
#pragma HLS array_partition variable = a complete
// dim = 0 也能实现同样的效果
#pragma HLS array_partition variable = a dim = 0
// 对于二位数据b,把第一维全展开的写法
#pragma HLS array_partition variable = b dim = 1
// 对于二位数据b,把第一维cyclic展开成4份
#pragma HLS array_partition variable = b dim = 1 cyclic factor = 4

4. pipeline的使用,如下所示,当指定ii时,工具会按照这个目标去综合,最小做到设定值,如果不设定,默认ii=1(对于确定的设计建议明确的写出ii的值),当然,如果工具判断ii=1实现不了会按照最小的情况实现,当然,如果不期望pipeline,可以用off关闭。
for(int i=0;i<16;i++){
#pragma HLS pipeline ii=2
//#pragma HLS pipeline off
x[i] = y[i];
}
5. 其他常用的pragma:
//hls工具在分析代码时对某些函数块可能不是按照我们预期的做inline on/off处理,所以我们需要自己指定,是否inline,应该是在资源和时序之间权衡。
#pragma HLS inline off
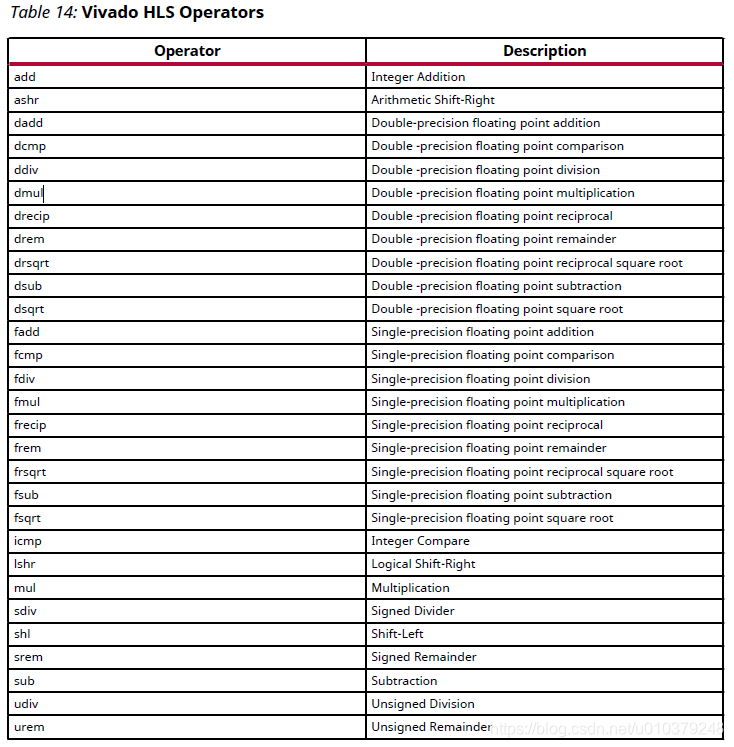
//对于操作符dmul,操作符如下表所示,它的意思是在当前函数内,最多使用16个dmul资源
#pragma HLS ALLOCATION instances=dmul limit=16 operation
//当我们自定义一个函数func时,如下所示pragma,可以限定pragma所在的函数所使用的func资源为limit份
#pragma HLS ALLOCATION instances=func limit=1 function
//指定计算的资源类型
#pragma HLS RESOURCE variable=temp core=AddSub_DSP
//指定array InitPara的存储资源类型,包括RAM_2P_BRAM,RAM_2P_URAM,RAM_2P_LUTRAM,FIFO_LUTRAM等等
#pragma HLS RESOURCE variable=InitPara core=RAM_2P_BRAM
// 最新指定数组资源类型的pragma
#pragma HLS bind_storage variable=InitPara type=ram_2p impl=bram
//指定循环的最大最小次数,用来分析latency,但只影响hls报告的生成。
#pragma HLS loop_tripcount min=10 max=10
//表明循环内变量buff_A每一次迭代计算互不依赖,谨慎使用(有些依赖问题工具不能自动判断处理,需要coder来自行指定,但是如果指定错误可能导致设计异常)
#pragma HLS dependence variable=buff_A inter false
//设计变量stream类型(fifo)的变量的深度,影响资源
#pragma HLS stream variable = testStrm depth = 32
//drective写在外部循环的内部,禁止与内部循环合并(拉平)
#pragma HLS flatten off
6. HLS设计的优化设计和Kernel level设计的一些心得。
Update:
HLS pragma 文档好像开始在这里更新了,也比较详细,推荐给大家。不同版本之间的pragma会有一定的区别,大家注意鉴别。
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/u010379248/article/details/102532100