本文转载自:VLSI架构综合技术研究室
2011年《IEEE计算机辅助设计学报》(IEEE Transactions on Computer-Aided Design) 刊登了一篇题为 《FPGA的高层次综合:从原型设计到部署》(High-Level Synthesis for FPGAs: From Prototyping to Implementation)的主旨论文,介绍了高层次综合(HLS)领域当时的最新进展。该论文以AutoPilot为例,展示了HLS技术在多个方面的优势。论文还报告了第三方咨询公司BDTI和FPGA领域龙头公司Xilinx(已于2022年被AMD收购)使用AutoPilot进行独立测试的结果。结果表明,AutoPilot可以实现高性能和低成本的FPGA设计。这一论文的发表推动了FPGA行业对HLS技术的采用。Xilinx在收购了AutoESL 之后于2012年推出了自己的HLS工具Vivado HLS,Altera于2013年推出了基于OpenCL的HLS工具以及基于C++的HLS Compiler。如今,HLS技术已被广泛应用于各种领域,包括深度学习、生物信息学、数据处理、图像处理等。
我们将在这个系列文章中介绍高层次综合在几个重要应用领域取得的成功及挑战。这一篇主要介绍高层次综合HLS在深度学习领域中取得的成果。
在过去十年中,深度学习在许多应用领域取得了巨大的成功。深度学习推理的硬件加速受到了广泛关注。2015 年初,VAST实验室发布了世界上第一个 FPGA 驱动深度学习加速器,并使用 HLS 技术来加速 CNN的实现。此加速器在Xilinx Virtex-7 FPGA 中实现。DDR3 DRAM 作为外部存储,MicroBlaze 用于辅助加速器的启动、与主机 CPU 的通信和时间测量,AXI4lite 总线用于命令传输,AXI4 总线用于数据传输。CNN 加速器因此可以作为 AXI4 总线上的 IP核来工作。该工作具有重要意义:
. 使用 HLS 探索了 1,000 多种加速器配置,并收敛到一个在计算和通信方面都优化的解决方案。
. 一名研究生在不到 6 个月的时间内完成了实现,比谷歌发布 TPU 早得多。
. 与 16 线程 CPU 实现相比,速度提升了 5 倍,能耗降低了 25 倍。
受此结果的启发,大量创新的深度学习加速器被设计在 FPGA 上,其中许多是通过使用 C++ 或 OpenCL 的HLS来实现的。我们将重点介绍近期几个基于HLS来设计实现的重要工作。
FINN编译器
深度神经网络(DNN)的计算量很大,需要大量的存储空间来存储模型参数。为了满足成本和功耗要求,可以将输入、激活和模型参数进行量化(quantization)来降低表达的精度。这可以减少计算量和存储空间需求,同时提高吞吐量和功耗效率。在某些情况下,量化过的网络甚至可以比没有量化的网络有更好的泛化性能。FPGA在量化上有着很大的优势。其位级可定制性允许对系统不同部分的数值精度实现可控精确到每一位的设置。
由此Xilinx开发了基于FPGA实现量化深度网络推断的FINN编译器(https://github.com/Xilinx/finn)。其输入为Pytorch ONNX文件, 输出为C++描述文件并直连Vivado HLS实现全流程高层次综合。输出的C++文件是基于参数可调的深度学习网络架构的。FINN对深度网络的卷积层、池化层等各层进行了电路设计并实现了直接的映射。各层的电路设计是由处理单元(Processing Element, PE, 图1)、滑动窗口单元(Sliding Window Unit, SWU, 图2(a))、和矩阵向量阈值单元(Matrix-Vector-Threshold Unit, MVU, 图2(b))作为基本单元进行组合来实现。
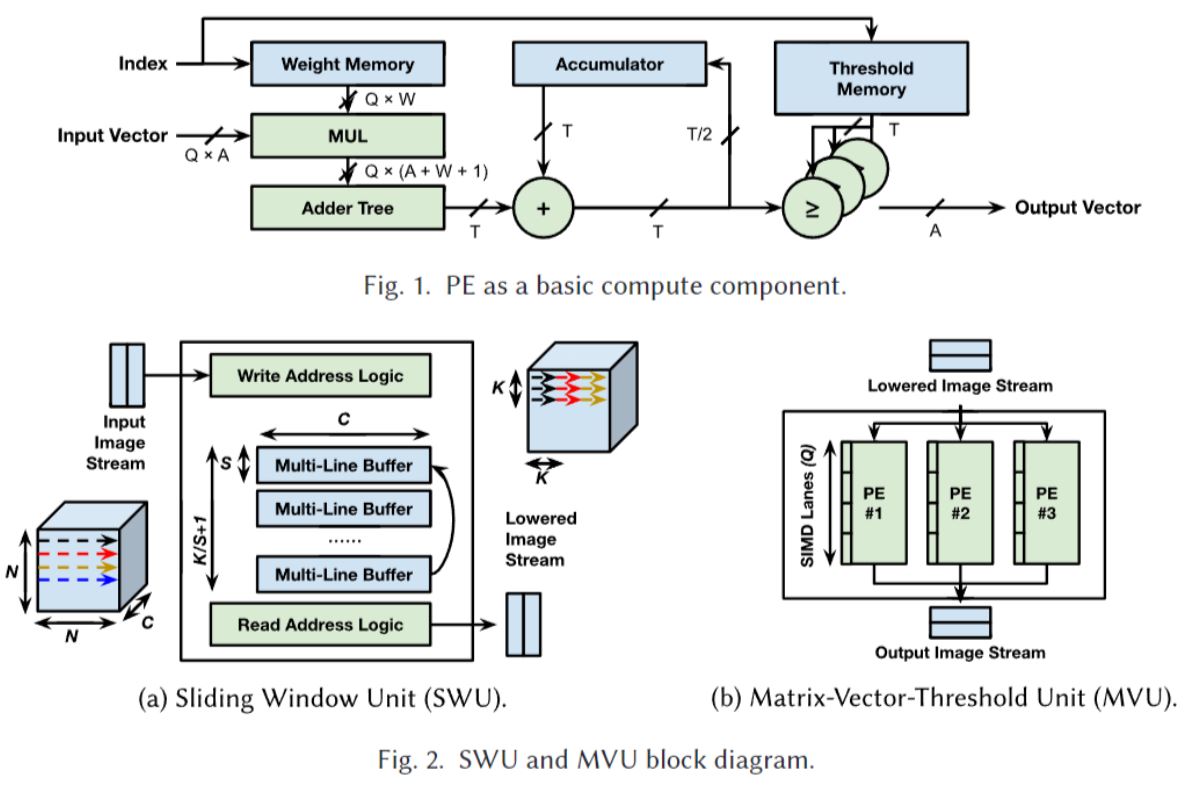
一个示意包含卷积层、池化层和全连接层的DNN 模型整体架构如下图所示。其中所有层都以数据流方式并发实现,所有权重都存储在片上。在此架构中,量化神经网络中的不同层可以很容易地实现不同的精度。此外,可以调整不同层的延迟/吞吐量权衡,从而使不同层的处理速率能够很好地匹配。
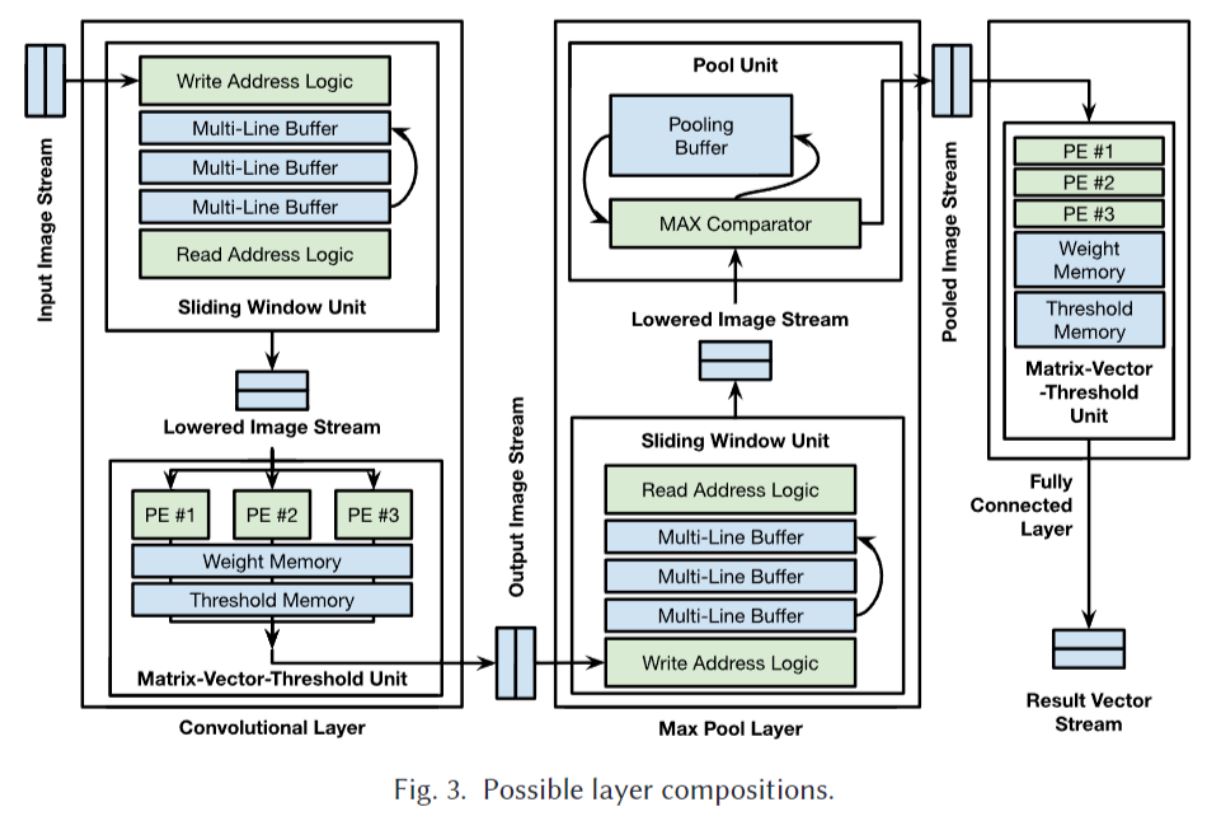
上述电路设计如果直接使用Verilog等硬件描述语言进行设计对工程师的技术门槛和开发周期要求都会很高。FINN 的一个重要贡献是可以直接从现有的通用机器学习描述出发直接生成电路。FINN的高层次综合输入是机器学习中普遍使用的PyTorch网络描述的 ONNX 文件且无需使用者有深厚的硬件设计基础。FINN会根据用户在 ONNX 中提供的量化神经网络表示,创建网络数据流模型并加以各类优化和转换以实现高效的各个计算内核(Kernel)实现。并计算数据流中每个节点的实现参数,使得深度网络中各层的执行时间大致相同即形成一个高效的流水线。
FINN可以根据指定实现的FPGA设备中可用资源的选择来最大化性能,合成相应的模板化 C++ 代码来实现每个计算节点。FINN 生成 的HLS 源代码一般会在循环上标记好所需的UNROLL pragma 和流水启动间隔 (initiation interval,II) = 1的循环优化设置。因此用户无需直接编写或优化 HLS 代码即完成电路实现。FINN生成的代码示例可以在 https://github.com/Xilinx/finn-hlslib/blob/master/mvau.hpp中找到。
许多机器学习系统侧重于实现大型、高精度的网络。FINN 则更倾向于实现具有很高吞吐量的量化网络,因为较小的网络可以完全展开并在每个时钟周期上实现流水线化(II = 1), 从而实现在 FPGA 中每秒超过2亿次推理。这种由HLS支持的功能有可能使机器学习在各类高速数据处理系统中得到广泛使用。
FracBNN
使用二元神经网络 (Binary Neural Netowrk, BNN) 在 FPGA 上加速深度学习应用引起了人们的极大兴趣。由于 BNN 具有 1 位权重和激活,因此常见的卷积操作被简化为位级操作。这些位级操作可以使用基于查找表 (LUT) 的逻辑在 FPGA 上高效实现。BNN 还减少了内存需求,使其成为使用FPGA进行加速的热门选择之一。
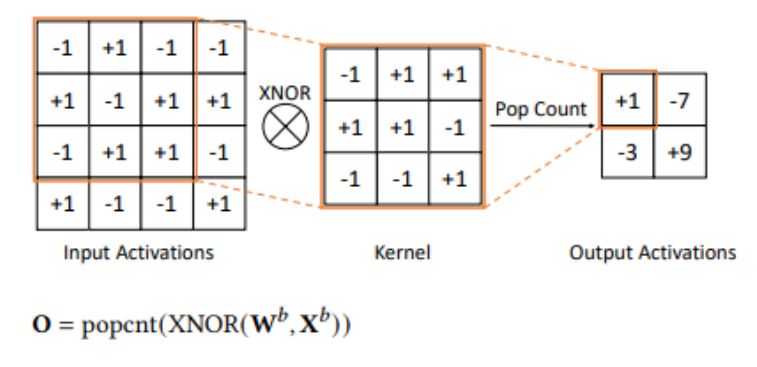
现有的基于 FPGA 的 BNN 实现因降低数值精度而导致准确性相对较低。此外,现有的 BNN 模型通常在输入层使用浮点权重和激活,这导致资源效率降低,因为浮点资源无法与其他层重复使用。FracBNN通过利用分数(Fraction)激活来大幅提高 BNN 的准确性,并且使用温度编码对输入层进行二值化来保持高准确性从而解决了这两个挑战。
具体而言,FracBNN 采用双精度激活方案,如果特定的卷积层权重与激活最高有效位(MSB)有可能显著影响最终准确性,则会额外计算并加上一个权重与最低有效位(LSB)的二进制卷积。这是通过对应用于激活最高有效位的第一个二进制卷积所含1的个数(popcnt)的学习阈值Δ来决定的。
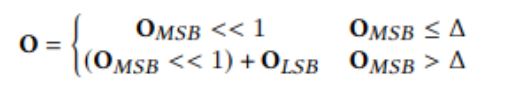
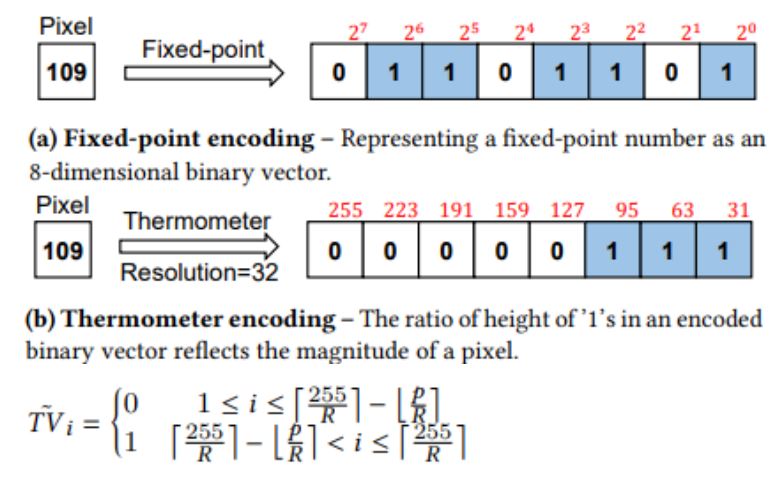
为了不显着降低准确性,对输入层进行二值化的挑战主要在于输入层的通道数。普通的RGB3通道对于BNN来说并不足够。FracBNN 将每个RGB每个通道的[0-255]像素各自转换为一个8 维二进制向量,从而增加了输入层的通道数。由下图所示FracBNN 不使用现有工作使用的传统定点数表示,而是使用温度编码方案对这些输入二进制向量进行编码,以均衡不同位的权重。与 FPGA 上最著名的 BNN 设计相比,FracBNN 在 ImageNet 上将 Top-1 准确性提高了 28.9%,同时将模型大小压缩了 2.5 倍。这是 BNN 方法首次在真实数据集上实现与 MobileNetV2 可比拟的准确性水平。此外,作者还成功展示了将 FracBNN 应用于嵌入式 FPGA 设备上高精度、低功耗、实时图像分类。
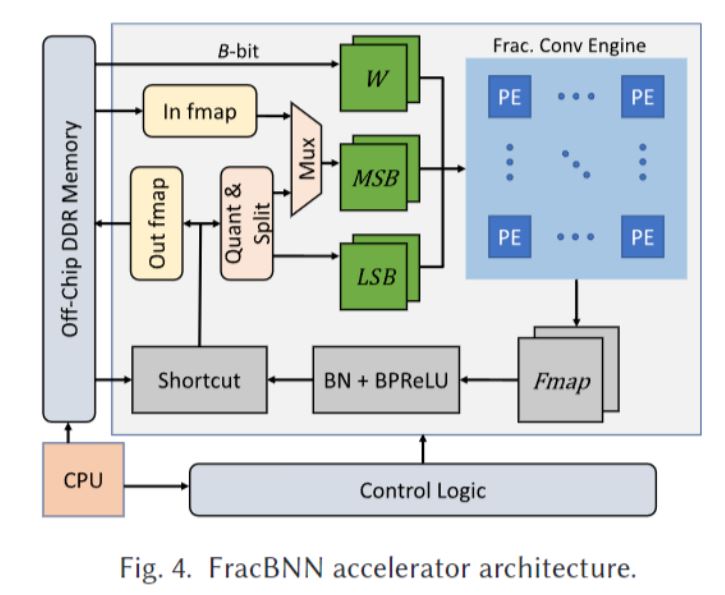
下图展示了 FracBNN 加速器的整体架构。要执行分数卷积,需要从片上block RAM 和片外 DDR 存储器分别获取2位特征图和1位权重。由于 FracBNN 层级处理网络,因此它可以将低精度特征图存储在BRAM 中以提高内存访问效率。获得特征图后,FracBNN 首先将每个 2 位特征拆分为 MSB 和 LSB。然后将其沿着通道维度打包成 B 位任意精度整数以进行并发访问。由于 FracBNN 从 DDR 加载权重,因此它必须将它们打包成 B 位向量以使精度与特征图一致。加速器将权重和特征图的集合传输到卷积引擎。
FracBNN的架构相当复杂,而HLS在FracBNN的实现中发挥了重要作用。在得到令人满意的结果质量 (QoR) 的同时,与基于硬件语言描述RTL的设计方法相比显著缩短了设计时间。两名研究生在几个月的时间内完成了整个 FracBNN的HLS设计。此外,HLS 能够快速探索各种设计空间,例如算子融合(operation-fusion)和定制buffer,这对系统性能至关重要。同时与另一种流行的基于覆盖层(Overlay)的FPGA设计技术相比,HLS可以快速实现特殊化非预设网络架构,提供了一种在 FPGA 上实现定制化特殊架构的有效方式。
Caffine
这项工作实现了对 FPGA 卷积神经网络(CNN)实现的软硬件协同设计。基于此可以开发利用Caffe作为其高层次综合HLS的输入并具有其他语言的可拓展性。
Caffine对于CNN的计算和传输部分分别做了优化。CNN的主要加速计算瓶颈在于卷积层和全连接层。通过测算发现卷积层是计算密集型而全连接层是存储密集型。因此需要对两层的计算分别进行优化。
对计算密集型的优化主要目的是尽可能地利用流水线(pipeline)和并行(parallel)的方式使得 II=1。对于单个卷积计算,如下图所示,Caffine利用多级数据并行来尽可能地使卷积计算电路获得高能效(LOOP UNROLL)。并利用多面体模型来提前计算循环边界来更好地实现流水线(LOOP PIPELINE)。在计算时为了增加效率,Caffine同时使用了双缓存(double buffering)技术使得在计算当前层的特征图与权值卷积时,下一层的特征图与权值已经提前从DRAM读进FPGA的BRAM。

整体上看,整个卷积计算架构如下图所示。可以看见其中的计算结构是一个脉动阵列的结构。Caffine同时使用了脉动阵列优化对电路进行加速使其可以支持更大的网络计算。
对存储传输的优化主要集中在全连接层的设计。通过对Kintex Ultrascale KU060 FPGA进行有效DRAM带宽测试发现,有效的 FPGA 带宽随着突发(Memory burst)长度的增加而上升,最终在某个突发长度阈值上趋于平稳。同时更长的接口位宽可以实现更高的峰值带宽。基于此,Caffine为了提升突发带宽和接口位宽,对DRAM的数据布局进行了调整以确保需要使用的数据保持在同一段连续空间。同时在这段空间里,为了减少相邻地址属于同一块数据同时写入同一块BRAM数据块造成写冲突的概率,数据之间根据BRAM数据块的标号进行了交错处理。

在对于CNN的计算和传输优化之后,往更深的层次来看CNN无论是卷积层还是全连接层其主要的操作都是矩阵乘法。现代CPU和GPU都有非常高效的库运算支持,所以倾向于将卷积层转换为全连接层以方便加速。在FPGA加速器设计中也有相同的考量。Caffine的设计与此相反,将全连接层转换为卷积层来避免转换成全连接层造成的数据复制从而抵消了FPGA的加速优势。Caffine提出的转换方式见下图, 一种是以输入为主的映射,另一种是以权重为主的映射。两种方法原理类似,都是将多个不同的全连接层乘法的乘数映射到同一个特征图和卷积核的空间里,从而统一了两种计算。不同的映射方式因此也变成了整个加速计算参数的求解空间的其中一维参数。

以上可以看出Caffine的设计中包含了很多的参数变量设置,比如tile size是多少,pipeline的目标II是多少,选择什么样的全连接层转换映射方式和映射尺寸大小等等。这些参数构成了一个庞大的求解空间。如果使用Verilog来实现以上电路和最优参数搜索流程几乎是不现实的。Caffine的另一个重要的工作在于为上述设计流程提供了HLS的软硬件协同设计解决方案。其软硬件协同设计流程如下图所示。用户只需要输入Caffe模型及调整一部分的高层次参数设置即可完成设计。Caffine的实现并不依赖于Caffe,因此任何合适的高层次前端语言及其解释器都能集成进来。
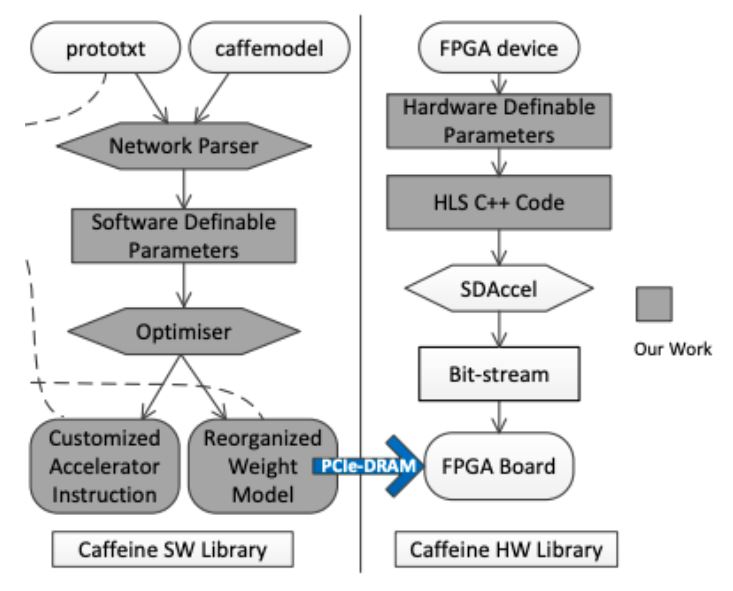
实验表现中Caffine使用了多种 FPGA 平台实现了 VGG16 和 AlexNet 网络。Caffeine 在中型 Xilinx KU060 FPGA 开发板上实现了 1460 GOPS 的峰值性能,这是到发表为止时公布的最佳结果。它比之前的 FPGA 加速器在 FCN 层上实现了超过 100 倍的加速。与 Caffe 集成的端到端评估表明,与运行 Caffe 的 12 核 Xeon 服务器相比,性能和能耗分别提高了 29 倍和 150 倍,并且比 GPU 实现的能效高出 5.7 倍。
AutoSA
这项工作主要是深度学习的高层次代码核(Kernel)映射到脉动阵列上。脉动阵列在上世纪70年代由H. T. Kung教授和Charles Leiserson教授提出并给出了形式化的定义。大概的意思是数值的计算是可以像心跳一样舒张收缩脉动化的,比如在3x3矩阵相乘时,行列向量之间错拍输入处理单元(PE),结果可以按节拍输出,比如行列输入分别在1,2,3拍进入,按列为单位输出分别在第3,4,5拍, 第4,5,6拍, 第5,6,7拍产生。
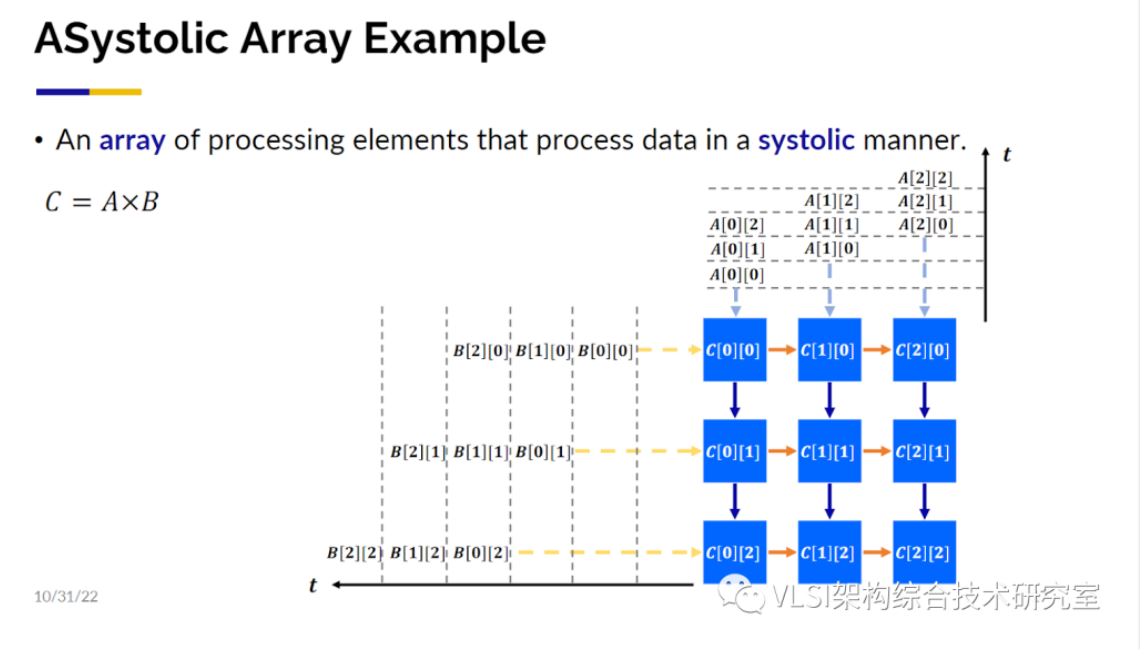
脉动阵列包含了很多大型矩阵和大量的并行处理,这带来了性能提升。脉动矩阵的另一个关注点在于局部临近计算,这优化了能耗。对传统芯片设计主要的性能影响指标并不是门的速度而是导线的速度。脉动阵列的布线只连接了相邻的处理单元。虽然脉动阵列的原理很简单,然而要设计出一块好的脉动阵列加速器并不是一件容易的事情。挑战在于不仅仅可以设计出一个脉动阵列的电路,而且是根据不同参数自动设计出最优的或者接近于最优的电路。即求解空间。AutoSA已经可以在这个求解空间内自动寻找最优解或者接近于最优的设计。接下来的工作我们又分成两大步骤,一个是计算管理,另一个是通信管理。对于计算管理这里用一个三循环的矩阵乘法来展示一下工作原理。这里第一个需要考虑的问题就是时间-空间映射。对这三个循环,需要决定哪几个循环可以映射到二维的空间域上同时计算,哪几个循环映射到一维时间维度上在处理器上进行常规的时间循环。解决这个问题使用了多面体模型(Polyhedral Model)来分析数据依赖,然后做一定程度上的穷举来缩小求解空间从而划出存在着最优解的子集。
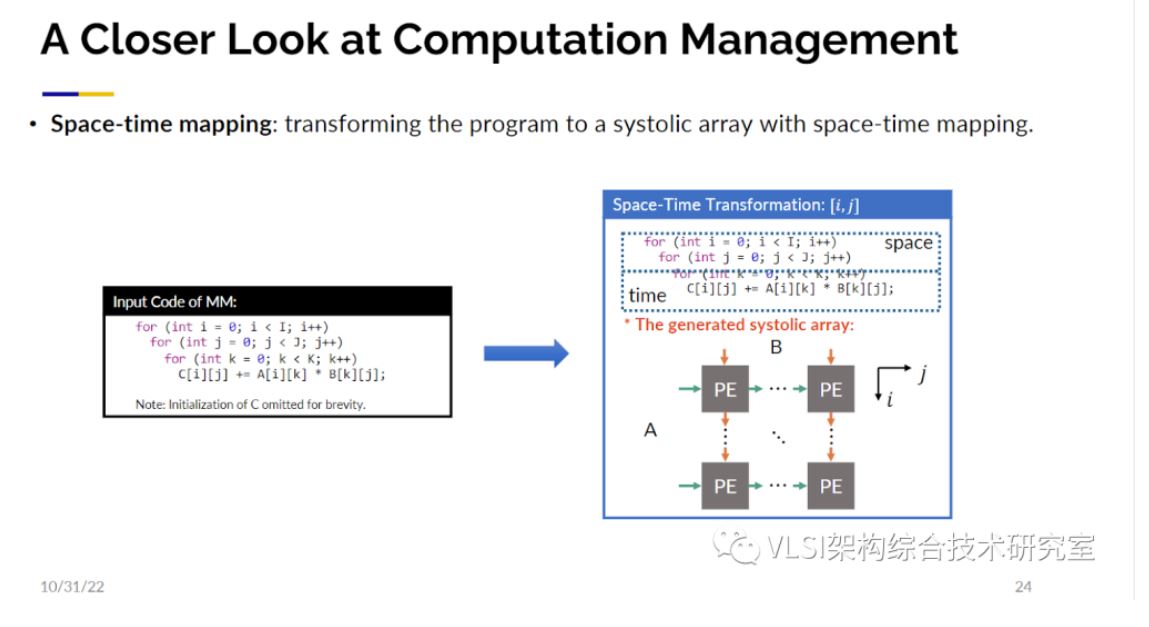
第二个需要考虑的问题是数据量。比如说需要处理10x24x24字节的数据,因为数据量大可能没有办法做到计算单元和每一个数据的对应。可能需要创建多个小一点的数组作为替代,我们称之为数组分块(Array Partition)。见图中的实例你可以把循环划分出一个个小块并在每一个小块上产生一个新的循环。这里AutoSA会对产生多大的小块这一参数进行优化。这还没有完,第三个需要考虑的问题就是时序。真正的电路并没有像当前时刻做计算然后传到右边的邻接节点然后在下一个时刻做新的计算这么简单。很多的运算比如说浮点数加乘需要花费好几个时钟周期。如果不做任何优化,相邻的处理单元可能需要等上5-10时钟周期才能得到数据。一个更好的方式是先开始计算一部分数据,比如说要花8个时钟周期。接着立刻在下一时钟周期对一块没有数据依赖的独立区域进行计算,这样每个时钟周期都能给相邻的处理单元一些数据。这就意味着你可能需要额外再分离出一些循环来实现上述操作,称之为延时隐藏(Latency Hiding)。最后脉动阵列处理单元不一定只能做一次加乘操作,这其中可以进行SIMD处理。可以有一个向量来同时处理16个运算。这也会产生额外的循环称之为SIMD循环。以上就是在计算管理上几个角度的考量。这些考量合在一起就形成了一个大的自动化求解空间。可以看见因为空间很大,也需要花一些时间来找到最优或接近最优的脉动阵列电路设计。

到现在为止对数据计算管理就有这么多的选项,对数据传输通信呢?其实传输通信才是关键,因为需要保证数据只在相邻的处理单元之间传递而不是广播数据。AutoSA通过做依赖分析来解决这个问题。可以在这个矩阵乘法的例子中发现A和B矩阵各自都有读后读依赖(Read-after-Read dependency)。接着发现操作中还有写后读的依赖(Read-after-Write dependency) 。因为C矩阵是在循环之间累加的。最后不同的数值会写在C矩阵不同的位置上。这样就能得到下图中的这张表来发现哪一个I/O组有着怎样的数据依赖关系。

AutoSA探索了脉动阵列设计的巨大解决方案空间,并在 FPGA 上实现了迄今为止报告最佳 INT-16 和 INT-8 加速结果。
FlexCNN
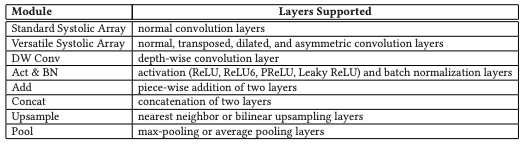
近几年对于卷积神经网络的构成有了更多的深入。除了普通的卷积层,卷积层可以被细分成以下或者更多的种类
. 深度可分离卷积(DSC)是一种特殊的卷积层,它将传统卷积层(N-CONV)的操作分为两步:深度卷积(DW)和逐点卷积(PW)。这可以显著降低计算量和参数量,并保持模型性能。
. 分步卷积层(T-CONV)或转置卷积层(也称为反卷积层)是一种上采样层,它使用训练好的权重来生成放大的高分辨率特征图。T-CONV 层常用于图像分割网络和生成对抗网络,例如 U-Net、DCGAN、ArtGAN、DiscoGAN、FSRCNN。
. 膨胀卷积层(D-CONV)通过扩展卷积滤波器的感受野来保持特征图的分辨率和覆盖率。一个使用 D-CONV 层的著名网络是 CSRNet。
. 非对称卷积层(A-CONV)是一种使用非对称滤波器尺寸(例如 1 × 5 或 5 × 1 滤波器)的普通卷积层。在硬件加速方面,这个层需要额外的逻辑来分别处理滤波器的每个维度。
上述几种细分的卷积层需要对应的电路优化设计来发挥最佳的效能。同时不同网络利用不同层之间的组合会给加速器的设计参数带来巨大变化。FlexCNN可以很好的胜任这项工作。
在硬件设计的数据读取层面,FlexCNN所做的优化包括融合层和并列层(Layer Fusion and Layer Parallelization)即有些层可以合并,有些层属于不同的数据流可以并行执行。这样一次DRAM的读写可以处理多层网络的计算。同时利用线缓冲器(line buffer)和MUX连接不同位置的数据实现动态循环分块(Dynamic Tiling)。以及其他多种方式减少DRAM的读写次数并充分利用每次DRAM读写的带宽。
在对于异型卷积层的处理上,以TCONV为例,FlexCNN采用了如下图所示矩阵分块并重组的方式实现了等效计算避免了大量和0相关的计算。并在传统脉动阵列的架构的基础上增加了out-collect层来对输出结果进行组装即图中不同色块的矩阵穿插放入输出矩阵Output FM的对应位置上。
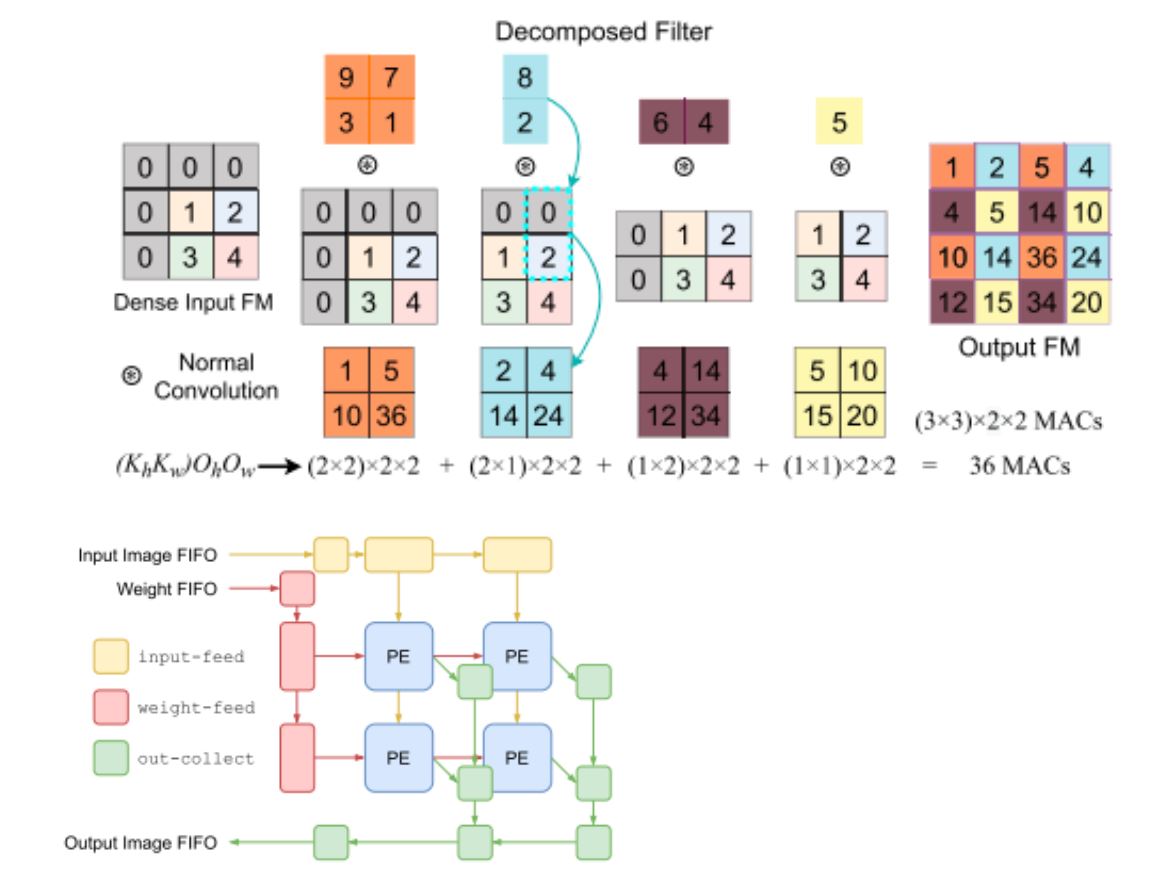
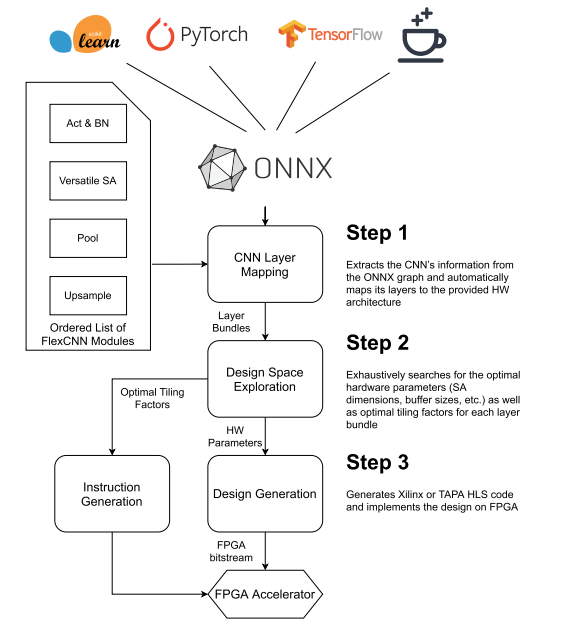
可以想象如果使用RTL直接设计FlexCNN是一件工程量巨大的工作。FlexCNN对上述优化利用高层次综合HLS实现自动化并提供了通用输入接口。如下图所示用户只需要提供通用机器学习语言的网络描述即可产生电路设计。FlexCNN流程中包含大量的解空间搜索问题。其通过modelsresource_est() 和 latency_est() 两个解析模型来估计资源和延时使用情况并迭代找到最优解。
OpenPose、U-Net 和 E-Net 等神经网络架构经过FlexCNN优化,性能提升了 2.3 倍。与标准脉动阵列加速器相比,对于转置卷积和膨胀卷积的加速分别高达 15.98 倍和 13.42 倍,平均面积开销为 6%。流水线集成使 OpenPose 的速度提高了 5 倍。
HLS在深度学习中的挑战
基于高层次综合HLS的设计方法可以高效地开发DNN深度学习加速器。目前流行的 DNN 模型通常具有规则的计算和内存访问模式,可以用嵌套循环轻松表示,而现有 HLS 工具对此提供了良好的支持。商业 HLS 工具还提供许多有用的语言构造(例如,任意精度整数/定点数类型)和优化指令/编译器指示(例如展开Unroll、流水线Pipeline、内存分区Memory Partition),这些对于在 FPGA 上实现快速 DNN 执行至关重要。
然而,在用户能够享受深度学习模型开发与其在 FPGA 上部署之间更短的周转时间之前,仍然存在一些障碍。第一个挑战在于验证。HLS 用户通常使用 C/RTL 协同仿真来验证 HLS 输出的功能。在某些情况下,在板上测试之前还需要进行协同仿真以获得更准确的性能估计。不幸的是,即使在减少的测试数据集上,计算密集型 DNN 模型的协同仿真也是一个相当耗时的过程,可能需要数小时的 CPU 时间。
另外一个挑战在于HLS 工具的 QoR 报告准确度问题。不准确的报告也可能是导致设计迭代速度变慢的另一个因素。事实上,HLS 资源使用通常与低级别 RTL 合成和工艺映射后的实际结果存在显著差异。对于量化的低位宽 DNN,这个问题更为突出,因为 LUT/FF 计数的高估可能会误导设计人员选择具有低并行化因子的次优架构使得性能变差。
参考文献
[1]Jason Cong, Jason Lau, Gai Liu, Stephen Neuendorffer, Peichen Pan, Kees Vissers, and Zhiru Zhang. 2022. FPGA HLS Today: Successes, Challenges, and Opportunities. ACM Trans. Reconfigurable Technol. Syst. 15, 4, Article 51 (December 2022), 42 pages.
[2]Michaela Blott, Thomas B. Preußer, Nicholas J. Fraser, Giulio Gambardella, Kenneth O’brien, Yaman Umuroglu, Miriam Leeser, and Kees Vissers. 2018. FINN-R: An End-to-End Deep-Learning Framework for Fast Exploration of Quantized Neural Networks. ACM Trans. Reconfigurable Technol. Syst. 11, 3, Article 16 (September 2018), 23 pages.
[3]Yichi Zhang, Junhao Pan, Xinheng Liu, Hongzheng Chen, Deming Chen, and Zhiru Zhang. 2021. FracBNN: Accurate and FPGA-Efficient Binary Neural Networks with Fractional Activations. In The 2021 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA '21). Association for Computing Machinery, New York, NY, USA, 171–182.
[4]C. Zhang, Zhenman Fang, Peipei Zhou, Peichen Pan and Jason Cong, "Caffeine: Towards uniformed representation and acceleration for deep convolutional neural networks," 2016 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Austin, TX, USA, 2016, pp. 1-8.
[5]Jie Wang, Licheng Guo, and Jason Cong. 2021. AutoSA: A Polyhedral Compiler for High-Performance Systolic Arrays on FPGA. In The 2021 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA '21). Association for Computing Machinery, New York, NY, USA, 93–104.
[6] Suhail Basalama, Atefeh Sohrabizadeh, Jie Wang, Licheng Guo, and Jason Cong. 2023. FlexCNN: An End-to-end Framework for Composing CNN Accelerators on FPGA. ACM Trans. Reconfigurable Technol. Syst. 16, 2, Article 23 (June 2023), 32 pages.





