前言
利用vivado高层次综合工具可将C代码综合成HDL语言。本文将详细解析一维有限长离散卷积的例子,并分析综合结果。另外,vivado HLS的使用方法见笔者另一篇博文: http://xilinx.eetrend.com/blog/13178 本文不再赘述。
维离散卷积原理
一维离散卷积就是卷积核与输入序列值两两相乘再求和,公式为:
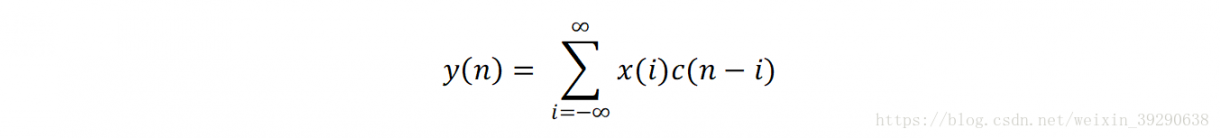
x为输入序列,y为输出数据,c为卷积核。在实际应用中,卷积核的长度是有限的。若卷积核的长度为N,则公式可以写为:
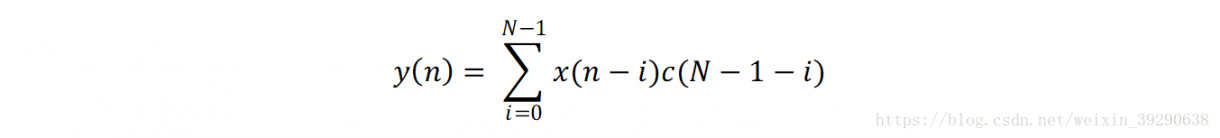
或:
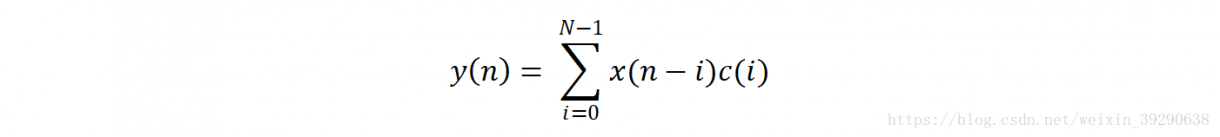
卷积计算的流程如图Fig.1和Fig.2。

Fig.1:当刚开始输入时,输入序列需要补0,使得参与卷积的序列长度与卷积核长度一致。
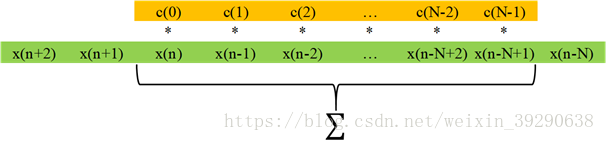
Fig.2:输入序列中,有N个数需要参与到卷积,在实际应用中,这N个数需要被临时存储在寄存器中,并且其值在不断地平移更新。每次卷积需要做N次寄存器值更新,N次乘法,N次加法(初始化sum=0)。
从上面的描述种可以看出:计算时,需要有一组寄存器临时保存输入x的序列,用s表示。寄存器的个数与卷积核长度相同,大小为N。以N=4为例,图Fig.3表示寄存器s的变化规则。s的赋值方式为s(3)=s(2),s(2)=s(1),s(1)=s(0),s(0)=x(t)。
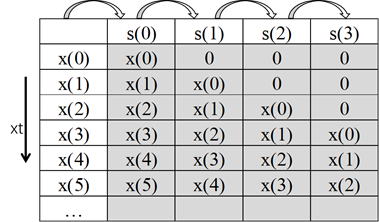
Fig.3:第一列代表输入信号x的时间序列,表格灰色部分每行表示不同输入时刻下,寄存器组s的对应的值。
一维离散卷积的C代码实现:
conv.h
#ifndef CONV_H_
#define CONV_H_
#define N 11
typedef int coef_t;
typedef int data_t;
typedef int acc_t;
void conv (
data_t *y,
coef_t c[N],
data_t x
);
#endif
conv.c
#include "conv.h"
void conv (
data_t *y,
coef_t c[N],
data_t x
){
#pragma HLS INTERFACE axis port=y //y接口综合成axis
#pragma HLS INTERFACE axis port=x //x接口综合成axis
#pragma HLS RESOURCE variable=c core=RAM_1P_BRAM//c接口综合成单口RAM
static data_t shift_reg[N];//临时寄存器
acc_t acc;
data_t data;
int i;
acc=0;
Shift_Accum_Loop: for (i=N-1;i>=0;i--) {
if (i==0) {//临时寄存器更新
shift_reg[0]=x;
data = x;
} else {
shift_reg[i]=shift_reg[i-1];
data = shift_reg[i];
}
acc+=data*c[i];//相乘累加
}
*y=acc;
}
注:输出不建议写成返回值,否则在优化时不能将其识别为一个端口。
高层次综合结果
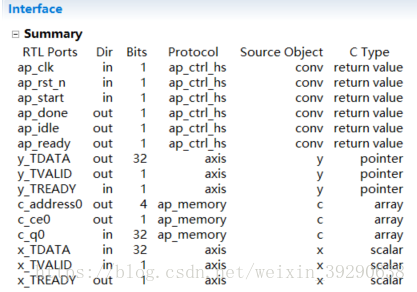
Fig.4:高层次综合的结果如上图所示。高层次综合实质上把C代码的串行指令综合成了FSM。 ap_xxx是代码综合后固有的接口,除了时钟和复位外,ap_xxx指代着FSM的状态。使用宏编译指令约束接口的综合。卷积需要多个时钟完成,所以输入和输出信号需要ready和valid指示信号。考虑到通用性,将x,y综合成axi-Strem类型的接口。卷积核一般存储在BRAM中,这里将其综合成单口RAM。
除接口外,我们还应该关注综合出的RTL逻辑所消耗的资源和性能,如图Fig.5和Fig.6。
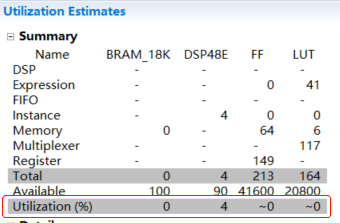
Fig.5:综合后所消耗资源量如上图。红框部分表示各项消耗资源所占选定型号FPGA芯片的百分比。

Fig.6 Latency代表锁定输入后,计算输出所需要的时钟数。Interval代表两次输入之间相隔的时钟数。从图中Summary一栏中可以看出,Latency和Interval的最小值与最大值是相同的,说明综合出的RTL结果具有时间稳定性。在Loop一栏中,描述了循环Shift_Accum_Loop的综合结果。Iteration Latency代表循环迭代一次所需要的时钟数,在本设计中,循环迭代一次相当于做完一次乘法。在C代码中,我们定义了卷积核的长度N=11,那么需要11次迭代完成一次卷积,所以Trip Count为11。所以循环的延迟时钟数为: 8*11=88。
从Fig.6的分析可以看出,C代码综合后的结果由三个环节组成:1.锁定输入,消耗1个时钟周期;2.循环计算卷积,消耗88个时钟周期;3.锁定输出,消耗1个时钟周期。三个环节总共消耗90个时钟周期。另外,参考Analysis->Performance中的结果,分析c代码的综合方式,如图Fig.7,Fig.8。

Fig.7: 上图中,第一列中的x read代表锁定输入环节,Shift Accum Loop代表循环计算卷积环节,node 47代表锁定输出环节。第一行中的C0~C8代表综合结果FSM的9个状态,每个状态执行1个时钟周期。x read在C0状态执行,Shift Accum Loop在状态C1~C8执行,node 47在状态C1执行。 Fig.7 中的Shift Accum Loop展开后,如图Fig.8。
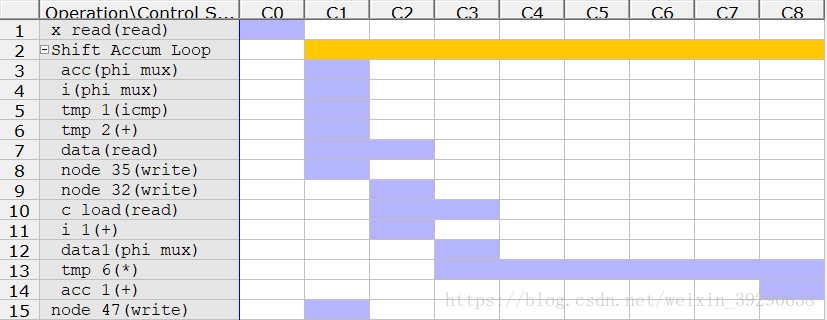
Fig.8:Shift Accum Loop展开后,可以初步分析出循环体内部的综合方式。Shift Accum Loop内部环节与C代码的对应关系如下表,Table.1。
|
acc(phi mux) |
选择分支输出acc的值,在C1执行 |
|
i(phi mux) |
选择分支输出i的值,在C1执行 |
|
tmp 1(icmp) |
比较i是否等于0,在C1执行 |
|
tmp 2(+) |
shift_reg的下标i的加法,在C1执行 |
|
data (read) |
data在两个时钟周期,根据两个条件分支,做了两次赋值,存在不同的临时寄存器中,分别在C1,C2 中执行 |
|
node 35(write) |
将x的值读取到shift_reg[0],在C1执行 |
|
node 32(write) |
将shift_reg[i-1]的值读取到shift_reg[i],在C2执行 |
|
c load(read) |
从BRAM中读取参数,需要消耗两个时钟周期,分别在C2,C3 中执行 |
|
i 1(+) |
每次迭代i自加(减),在C2执行 |
|
data1(phi mux) |
从两个条件分支中,根据i的值,选择一个值作为data值,在C3执行 |
|
tmp 6(*) |
将选出的data与c[i]做乘法,消耗6个时钟周期,在C3~C8 中执行 |
|
acc 1(+) |
将计算出的乘法值累加到acc上,在C8执行 |
综上所述,高层次综合将C代码串行的逻辑综合成并行的逻辑。例如:条件判断语句在C代码中的执行逻辑是从第一个条件分支开始(if),先计算条件判断,若成立则进入分支计算,若不成立则进入到下一个条件判断。而综合后的结果变为每个分支的计算在两个计算逻辑中同时并行执行,通过一个mux选出最终的结果。
综合结果优化
在默认设置下,C代码中的循环结构在综合时是不会被展开的,也就是说说循环体综合出的结果会被迭代N次才能算出最终结果。综合器用面积换速度的思想,将循环展开,增加了吞吐率。
Fig.9:在优化选项中将循环展开。(操作方法见见笔者另一篇博文:http://xilinx.eetrend.com/blog/13178
重新综合后,综合结果见Fig.10。
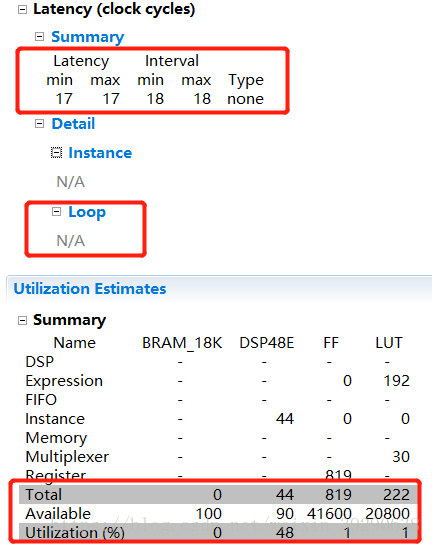
Fig.10:从结果可以发现,综合结果的Latency减小到了17,Loop中没有了多次迭代,但是资源占用率大大地增加了。
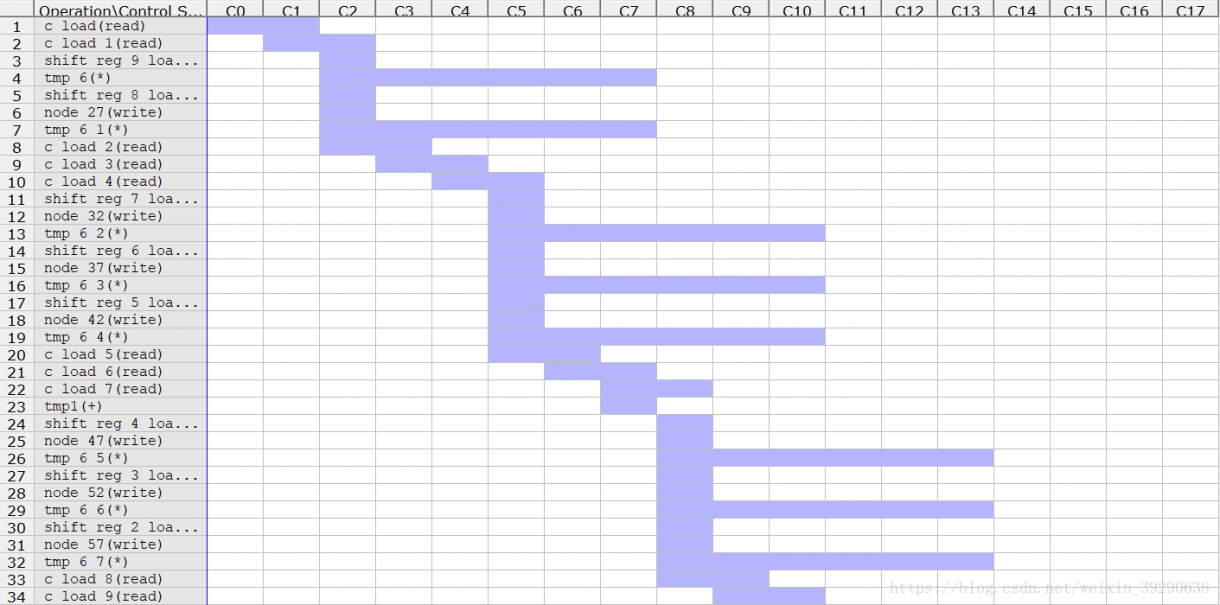

Fig.11:计算环节增加到了54个,FSM状态增加到了18个
本文转载自: https://blog.csdn.net/weixin_39290638/article/details/80246660





