前言
相信大家对于Python的列表和元组两种数据结构并不陌生了,如果我问大家这两种数据结构有什么区别呢?列表和元组都是数组,列表是动态的数组可以修改,元组是静态的数组不可修改。除此之外,大家还能想到其他的区别吗?接下来就让我来详细给大家介绍一下吧。
列表中高效搜索算法
存储结构
为了更好的了解列表,先来看看列表存储结构,列表其实也就是数组。当我们创建列表时,系统就需要给这个列表分配一块存储空间用来存放地址,地址指向的就是列表中存放的数据。

需要注意的是,如果给列表分配了8块存储空间,那么实际上列表能用的空间只有7,第一块空间是用来存放列表的长度。
查询任意指定的元素时,只需要知道列表存储的起始位置和元素存储的位置(这里的位置不是指地址,而是指元素相对于起始地址的偏移量),就可以很快到查询到。因为每块存储空间占用的大小(存储地址)都是一样的,占用一个整形大小的空间用来指向列表中存放的数据,所以在查询元素的时候与列表中存放的数据类型无关。
例如:列表的起始位置是M,我们想要列表中的第k个元素,这时候只需要将指针移到M+k的位置,然后再读取数据就好了。也就是说,只要数据保存在一个连续的存储空间中时,查询指定位置元素的时间复杂度为O(1)。
列表查询
在介绍列表的存储结构的时候,已经知道了如果指定列表存储的起始位置,当需要查询指定位置元素时的时间复杂度为O(1)。那如果是已知元素的值,查询元素的位置,此时的时间复杂度又是多少呢?如果大家对这段话不是很理解,下面举例说明一下。
例如:有一个列表a为[5,3,7,8,2,1,4],此时如果想要获取a[2]的元素值时的时间复杂度为O(1),此时查询元素值与列表的大小无关。当我们想知道4是否在列表中,最简单的方法就是遍历数组中的每一个元素与我们寻找的元素一一比对是否相等,这种方法最差的时间复杂度为O(n),也就是没有找到符合位置的元素或者元素在列表的最后一个位置,Python内置的list.index()方法正是采用的这种算法。
面对这种情况,如果想要进一步提升算法的查询速度,有两种算法可以解决。第一种,更改数据结构,将列表改为字典,然后通过字典的键来获取值,此时也能够得到O(1)的时间复杂度,但是转换过程需要加入计算量,,而且字典的键不能重复。第二种方式就是,先对列表进行排序,然后再通过二分法查找元素是否存在列表中只需要O(log(n))的时间复杂度,但是排序还是需要引入一些计算量,这种先排序后查找算法在某些时候是最优的,当列表比较大的时候。
Python提供了一个bisect模块,可以保证你在向列表中插入元素的时候保持排序的同时添加元素,还提供了一个高度优化过的二分查找算法,这就是Python的强大之处,第三方库非常丰富,免去了重复造轮子的麻烦。bisect模块提供的函数,可以将添加的新元素插入在列表正确的位置上,使得列表始终满足排序,以便我们能够很快的找到元素的位置。
使用bisect模块向列表中插入元素
import bisect,random
random_list = []
for i in range(10):
#产生一个随机数
random_value = random.randint(0,100)
#使用bisect模块向列表中插入元素,并且保持列表排序
bisect.insort(random_list,random_value)
print(random_list)
#[3, 3, 5, 51, 53, 67, 68, 90, 94, 95]使用bisect模块查询元素的位置
import bisect,random
def find_list_index(insert_list,find_value):
"""寻找列表中与find_value最接近元素的位置
:param insert_list: 列表(由小到大排序)
:param find_value: 寻找的元素
:return: 列表中与寻找元素最接近的位置
"""
#bisect_left方法返回,列表中大于或等于该元素的位置
i = bisect.bisect_left(insert_list,find_value)
#寻找元素大于列表中最大值,返回列表的长度
if i == len(insert_list):
return i - 1
#寻找元素刚好等于列表中的这个元素
elif insert_list[i] == find_value:
return i
#寻找的元素在列表中某两个值之间
elif i > 0:
j = i - 1
#返回列表中与寻找元素大小最接近的位置
if insert_list[i] - find_value > find_value - insert_list[j]:
return j
return i
random_list = []
for i in range(10):
#产生一个随机数
random_value = random.randint(0,100)
#使用bisect模块向列表中插入元素,并且保持列表排序
bisect.insort(random_list,random_value)
print(random_list)
#[0, 1, 2, 13, 35, 37, 51, 64, 72, 86]
#查找与50最接近元素的位置
print(find_list_index(random_list,50))
#6列表和元组的区别
在前面也简单介绍过了列表和元组的一些区别,这里我们做个总结:
① 列表是动态数组,列表的长度可变,内容可修改
② 元组是静态数组,长度不可变,内容不可修改
③ 元组缓存在Python的运行时环境,所以在使用元组的时候不需要去通过系统的内核来分配内存
所以,对于不会改变的数据,建议使用元组进行存储,这样在读取数据的时候能够高效。而对于需要改变的数据,则选择列表进行存储。需要注意的是,列表和元组都可以存储不同的数据类型,即保存数据的时候允许混合类型,但是这样操作的坏处就是会带来一些额外的开销。
列表
前面也介绍过了,列表属于动态数组,所以列表的大小是可变的,当创建一个大小为N的列表时,此时列表的大小为N,那么如果我使用append方法添加一个元素时,此时列表的大小是N+1吗?
当然不是,实际上,当第一次使用append方法时,Python会先创建一个列表,用来存放之前的N个元素以及额外添加的元素。而分配给这个列表的大小不是N+1,而是M(M>N),这样做的主要目的是为了便于以后使用append的方法添加元素时,不需要频繁的去创建列表和复制数据。
列表的超额分配发生在第一次往列表中添加元素,创建列表时,是按照所需要的大小创建的,不存在超额分配。
列表的超额分配公式:
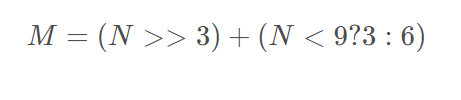
注意:并不是每一次append的时候都会导致超额分配,第一次添加数据的时候会发生超额分配,后面再添加数据的时候,只有当N==M的时候,即列表的空间已经满了没法存储更多的数据时,才会发生超额分配。虽然说,列表超额分配的空间并不是很多,但是如果列表的数量很多时,超额分配的空间还是不容小视的。
元组
元组是静态数组,所以当元组被创建之后其长度和内容都无法修改。虽然说,无法修改元组,但是我们可以将两个元组拼接成一个新的元组,而且不需要为新的元组分配任何额外的空间。这个操作类似于列表的append操作,唯一的区别在于当列表的内存耗尽的时候,再使用append时会开辟一些额外的内存空间,会导致部分空间的浪费。而元组是直接将两个元组相加再返回一个新的元组,这一过程不会产生额外的内存空间。
主要注意的是,在使用列表和元组保存同样的数据时,即使列表没用使用append操作,列表所需要的内存仍然是大于元组的,这是为了使得让列表能够记住更多自身的一些信息以便它们能够进行高效的resize。
除此之外,元组还有一个好处在于,资源缓存。Python也是一门垃圾收集语言,当某些变量我们不再使用的时候,系统就会自动回收释放内存,以便其他程序或变量使用。对于长度为1-20的元组而言,即使不再使用,也不会马上释放内存,而是留给以后使用。当需要创建新的元组的时候,就可以直接使用这块内存,而不需要再去向系统申请内存。
总结:要想高效的寻找列表中的某一个元素是否存在时,可以让列表进行排序,然后再去查找。对于不会改变的数据,建议使用元组进行保存,如果需要频繁修改数据还是使用列表。
本文转自: Python机器学习之路,作者:xiulian,转载此文目的在于传递更多信息,版权归原作者所有。





