本文转载自:XILINX开发者社区微信公众号
提取实现任务级 (task_level) 的硬件并行算法是设计高效的HLS IP内核的关键。
在本文中,我们将重点放在如何能够在不需要特殊的库或类的情况下修改代码风格以实现C代码实现并行性。Xilinx HLS 编译器的显着特征是能够将任务级别的并行性和流水线与可寻址的存储器 PIPO或 FIFO相结合。本文首先概述可以获取任务并行的前提条件,然后以DAG(directedacyclic graph) 代码为例,挖掘其中使用 fork-join 并行性,并结合使用 ping- pong buffer 启用了一种基于握手的任务级粗粒度的流水线形式。
我们理解任务级并行的时候可以想象成这样一个场景,每一个计算任务都是时间轴上向前奔跑的马车,马车与马车之间传输的货物就像是计算数据,他们需要管道去连接即 FIFO 和 PIPO ,FIFO 是一个先进先出存储器也就是说使用这样的管道传输数据的时候,数据进出的顺序不可以改变。而 PIPO 就是一个可寻址的存储器管道,数据在任务之间进出的顺序可以改变。
最糟糕的状态是什么?马车在时间线上顺序出发,A 马车到达终点后 B 再出发以此类推,就像是 CPU 中的单进程顺序执行模式一样,而FPGA中有可供并行化执行的数据传输管道,更多的资源就像是跑道一样,所以这个状态效率是最低的。

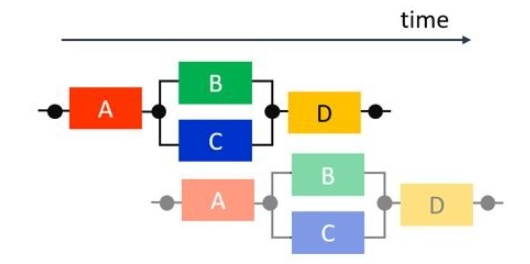
那么先做一点点改进,我们分析发现 B 和 C 马车不享有任何公用的数据或存储计算资源,也就是他们完全可以在 A 结束后并行执行,最后再执行 D,这种并行情况中含有顺序和并行两种模式,我们称之为交叉并行 (fork-joinparallelism)。 但是下一次进程仍然是顺序执行的。
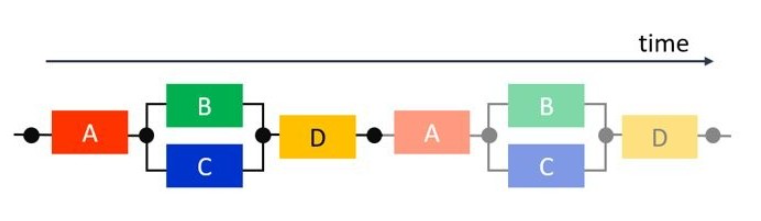
继续深入可以发现,四辆马车在跑完各自的任务后都有一段的闲置时间,提高吞吐量和资源重复利用也很明显是息息相关的。实现了进程之间的流水线执行的结果就如下图,每一辆马车在不同的进程中连续执行任务,向前奔跑,重复利用资源的同时它提升了吞吐量进而极大的减小了完成多个进程后的延迟。
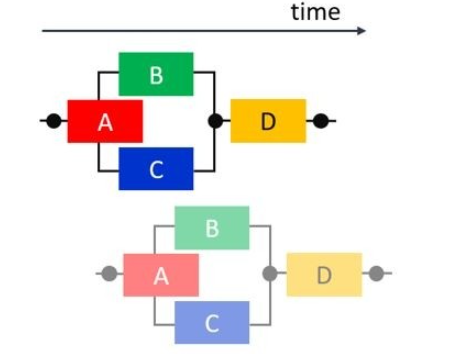
最理想的状态时什么?就是马车尽可能的一个挨着一个一起出发,并行奔跑,大家先后到达终点完成计算,在奔跑的过程中数据通过管道也完成了迁移,最终计算完的数据在最后一辆马车到达终点的时候产出。下图我们可以看到 B 和 C 开始执行的时间提前了,并没有等到A完全执行完毕,这和数据依赖息息相关,也就是说我们进一步挖掘并行性的路上发现:ABC 三辆马车都可以在增加马车数量 (扩增资源) ,建立数据管道的并行执行的前提下实现了。我们用资源换取了更大的并行性,这就是继续挖掘并行性上需要付出的代价。
奔跑的马车带着我们理解了任务级流水线的优化之路,下面我们结合代码看一看HLS工具会在哪些情况下阻止 dataflow 的实现。
在我们谈及 dataflow 的优化之前,我们先去了解在 HLS 提醒你报错的方式,其中修改属性config_dataflow-strict_mode (off | error | warning) 指令可以控制报错指令的级别,一般情况下默认是 warning 级别的报错,主要看我们的并行性需求。
以下是阻止任务级别并行性的常见情况:
1. 单产出单消耗模型违例(Single-producer-consumerviolations)
为了使 VitisHLS 执行 DATAFLOW 优化,任务之间传递的所有元素都必须遵循单产出单消耗模型。每个变量必须从单个任务驱动,并且只能由单个任务使用。在下面的代码示例中是典型的单产出单消耗模型违例,单一的数据流 temp1 同时被 Loop2 和 Loop3 消耗。要解决这个问题很容易,就是将两个任务都要消耗的数据流复制成两个,如右图的 Split 函数。当 temp1数据流被复制为 temp2 和 temp3 后,LOOP1,2,3 就可以实现任务级流水线了。
void foo(int data_in[N], int scale, int data_out1[N], int data_out2[N]) {
int temp1[N];
Loop1: for(int i = 0; i < N; i++) {
temp1[i] = data_in[i] * scale;
}
Loop2: for(int j = 0; j < N; j++) {
data_out1[j] = temp1[j] * 123;
}
Loop3: for(int k = 0; k < N; k++) {
data_out2[k] = temp1[k] * 456;
}
}void Split (in[N], out1[N], out2[N]) {
// Duplicated data
L1:for(int i=1;i<N;i++) {
out1[i] = in[i];
out2[i] = in[i];
}
}
void foo(int data_in[N], int scale, int data_out1[N], int data_out2[N]) {
int temp1[N], temp2[N]. temp3[N];
Loop1: for(int i = 0; i < N; i++) {
temp1[i] = data_in[i] * scale;
}
Split(temp1, temp2, temp3);
Loop2: for(int j = 0; j < N; j++) {
data_out1[j] = temp2[j] * 123;
}
Loop3: for(int k = 0; k < N; k++) {
data_out2[k] = temp3[k] * 456;
}2. 旁路任务 Bypassing Tasks
正常情况下我们期望流水线任务是一个接着一个的产出并消耗,然而像下面这个例子中,Loop1 产生了 Temp1和Temp2 两个数据流,但是在下一个任务 Loop2 中只有 temp1 参与了运算,而 temp2 就被旁支了。Loop3 任务的执行依赖 Loop2 任务产生的 temp3 数据,所以 Loop2 和 Loop3 因为数据依赖的关系无法并行执行。
void foo(int data_in[N], int scale, int data_out1[N], int data_out2[N]) {
int temp1[N], temp2[N]. temp3[N];
Loop1: for(int i = 0; i < N; i++) {
temp1[i] = data_in[i] * scale;
temp2[i] = data_in[i] >> scale;
}
Loop2: for(int j = 0; j < N; j++) {
temp3[j] = temp1[j] + 123;
}
Loop3: for(int k = 0; k <N; k++) {
data_out[k] = temp2[k] + temp3[k];
}
} 3. 任务间双向反馈 Feedbackbetween Tasks
假如说当前任务的结果,需要作为之前一个任务的输入的话,就形成了任务之间的数据反馈,它打乱了流水线从上级一直往下级输送数据流的规则。这时候 HLS 就会给出警告或者报错,有可能完成不了 dataflow 优化了。有一种特例是支持的:使用 hls::stream 格式的数据流反馈。
我们分析以下代码的内容:
当第一个程序 firstProc 执行的时候,hls::stream 格式的数据流 forwardOUT 被写入了初始化为10的数值 fromSecond 。由于 hls::stream 格式的数据本身不支持初始化操作,所以这样的操作避免了违反单产出单消耗原则。之后的迭代里,firstProc 通过 backwardIN 接口从 hls :: stream 读取数值写入 forwardOUT 中。
在第二个程序 secondProc 执行的时候,secondProc 读取 forwardIN 上的值,将其加1,然后通过按执行顺序倒退的反馈流将其发送回 FirstProc。从第二次执行开始,firstProc 将使用从流中读取的值进行计算,并且两个过程可以使用第一次执行的初始值,通过正向和反馈通信永远保持下去。这种交互式的反馈中,包含数据流的双向反馈机制,但是它就像货物一直在从左手倒到右手再从右手倒到左手一样,可以不违反 Dataflow 的规范,一直进行下去。
#include "ap_axi_sdata.h"
#include "hls_stream.h"
void firstProc(hls::stream<int> &forwardOUT, hls::stream<int> &backwardIN) {
static bool first = true;
int fromSecond;
//Initialize stream
if (first)
fromSecond = 10; // Initial stream value
else
//Read from stream
fromSecond = backwardIN.read(); //Feedback value
first = false;
//Write to stream
forwardOUT.write(fromSecond*2);
}
void secondProc(hls::stream<int> &forwardIN, hls::stream<int> &backwardOUT)
{
backwardOUT.write(forwardIN.read() + 1);
}
void top(...) {
#pragma HLS dataflow
hls::stream<int> forward, backward;
firstProc(forward, backward);
secondProc(forward, backward);
}4. 含有条件判断的任务流水
DATAFLOW 优化不会优化有条件执行的任务。下面的示例展现了这个违例。在此示例中,有条件地执行 Loop1 和 Loop2 会阻止 Vitis HLS 优化这些循环之间的数据流,因为 sel 条件直接控制了任务中的数据有可能不会从一个循环流到下一个循环。
void foo(int data_in1[N], int data_out[N], int sel) {
int temp1[N], temp2[N];
if (sel) {
Loop1: for(int i = 0; i < N; i++) {
temp1[i] = data_in[i] * 123;
temp2[i] = data_in[i];
}
} else {
Loop2: for(int j = 0; j < N; j++) {
temp1[j] = data_in[j] * 321;
temp2[j] = data_in[j];
}
}
Loop3: for(int k = 0; k < N; k++) {
data_out[k] = temp1[k] * temp2[k];
}
}但是我们都知道,其实这些任务之间存在条件判断和选择是非常常见的情况,只需要稍微改变代码风格就可以既保留条件判断,又完成任务流水。为了确保在所有情况下都执行每个循环,我们将条件语句下变化的 Temp1 移入第一个循环。这两个循环始终执行,并且数据始终从一个循环流向下一个循环。
void foo(int data_in[N], int data_out[N], int sel) {
int temp1[N], temp2[N];
Loop1: for(int i = 0; i < N; i++) {
if (sel) {
temp1[i] = data_in[i] * 123;
} else {
temp1[i] = data_in[i] * 321;
}
}
Loop2: for(int j = 0; j < N; j++) {
temp2[j] = data_in[j];
}
Loop3: for(int k = 0; k < N; k++) {
data_out[k] = temp1[k] * temp2[k];
}
}5. 有多种退出机制的循环
含有多种退出机制的循环不能被包含在流水线区域内,我们来数一数 Loop2 一共有多少种循环退出条件:
1. 由 for 循环定义的 K>N 的情况;
2. 由 switch 条件定义的 default 情况;
3. 由 switch 条件定义的 continue 情况
由于循环的退出条件始终由循环边界定义,因此使用 break 或 continue 语句将禁止在DATAFLOW 区域中使用循环。
void multi_exit(din_t data_in[N], dsc_t scale, dsel_t select, dout_t
data_out[N]) {
dout_t temp1[N], temp2[N];
int i,k;
Loop1:
for(i = 0; i < N; i++) {
temp1[i] = data_in[i] * scale;
temp2[i] = data_in[i] >> scale;
}
Loop2:
for(k = 0; k < N; k++) {
switch(select) {
case 0: data_out[k] = temp1[k] + temp2[k];
case 1: continue;
default: break;
}
}
}我们理解了可能阻止任务流水线的 5 种经典情况后,我们最后推出适用于 Vitis HLS 的Dataflow 优化的两种规范形式 (canonical forms) ,一种直接应用于函数,一种应用于 for循环。我们可以发现规范形式严格遵守了单产出单消耗的规则。
1. 适用于子程序没有被内联 (inline) 的规范形式
void dataflow(Input0, Input1, Output0, Output1)
{
#pragma HLS dataflow
UserDataType C0, C1, C2;
func1(read Input0, read Input1, write C0, write C1);
func2(read C0, read C1, write C2);
func3(read C2, write Output0, write Output1);
}2. 适用于循环体内的任务流水的规范形式:
对于 for 循环 (其中没有内联函数的地方),循环变量应具有:
a. 在 for 循环的标题中声明初始值,并设置为 0。
b. 循环条件N是一个正数值常数或常数函数参数。
c. 循环的递增量为1。
d. Dataflow 指令必须位于循环内部。
void dataflow(Input0, Input1, Output0, Output1)
{
for (int i = 0; i < N; i++)
{
#pragma HLS dataflow
UserDataType C0, C1, C2;
func1(read Input0, read Input1, write C0, write C1);
func2(read C0, read C0, read C1, write C2);
func3(read C2, write Output0, write Output1);
}
}有关 Dataflow 指令的原理,设计准则和规范形式都在本文讲解给大家了,更多设计例程可以参考Github(https://github.com/Xilinx/HLS-Tiny-Tutorials/tree/master/coding_dataflow... ),如有疑问欢迎交流!





