Versal® AI Core 系列可借助 AI 引擎提供突破性的人工智能( AI )推断加速。此系列应用范围广泛,包括用于云端动态工作负载以及超高带宽网络,同时还可提供高级安全性功能。AI 和数据科学家以及软硬件开发者均可充分利用高计算密度的优势来加速提升任何应用的性能。鉴于 AI 引擎所具备的高级信号处理计算能力,它十分适合用于高度优化的无线应用,例如射频、5G、回程( backhaul )和其它高性能 DSP 应用。
本文档聚焦 AI 引擎内核编程,除单内核编程外,还涵盖了多方面的内容,如内核之间的数据通信,这些方面的内容都是将应用分区为多个内核以达成整体系统性能所必不可少的概念。本文档涵盖了以下设计进程:
• AI 引擎开发:创建 AI 引擎 Graph 及内核、库用法、仿真调试与剖析以及算法开发。还包含 PL 与 AI 引擎内核的集成。
如果您希望获取完整文档,请至文末链接进行下载。
AI 引擎架构概述
AI 引擎阵列由二维 AI 引擎拼块 (tile) 阵列构成,其中每个 AI 引擎拼块均包含一个 AI 引擎、存储器模块和拼块互连模 块。AI 引擎拼块二维阵列概览如下图所示。

图:AI引擎阵列
根据阵列中拼块的位置,存储器模块在其东西南北四向的相邻 AI 引擎之间共享。AI 引擎可访问其东西南北各存储器模块及其自己本身的存储器模块。AI 引擎通过专用存储器访问接口来访问这些相邻存储器模块,并且每次访问最大位宽为 256 位。AI 引擎与相邻 AI 引擎之间还可发送或接收级联串流数据。级联串流是水平方向从左到右或从右到左的单向串流,它通过卷绕方式移至下一行。AXI4 互连模块可提供 AI 引擎拼块之间的串流连接,并在串流接口与存储器模块之间提供串流到存储器 (S2MM) 或存储器到串流 (MM2S) 连接。此外,互连模块还可连接到相邻互连模块,以便以类似网格的方式提供灵活的布线功能。
下图显示了单个 AI 引擎拼块的架构。
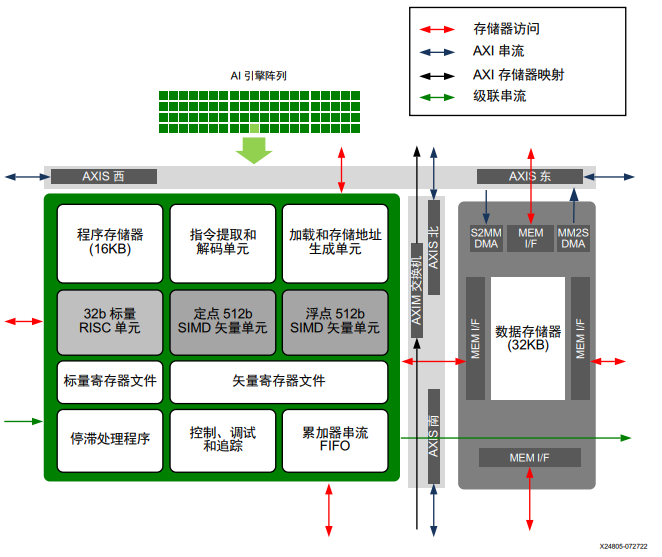
图:AI引擎拼块详情信息
每个 AI 引擎拼块都有一个 AXI4-Stream 交换机,它属于完全可编程的 32 位 AXI4-Stream 交叉开关矩阵。它支持含有反压的电路切换和包切换串流。通过 MM2S DMA 和 S2MM DMA,AXI4-Stream 交换机可提供往来 AI 引擎数据存储器的串流访问。此交换机还包含 2 个深度为 16 且位宽为 33 位(32 位数据 + 1 位 TLAST)的 FIFO,这两个 FIFO 可链接在一起构成深度为 32 的 FIFO,方法是通过电路切换将其中一个 FIFO 的输出链接到另一个 FIFO 的输入。
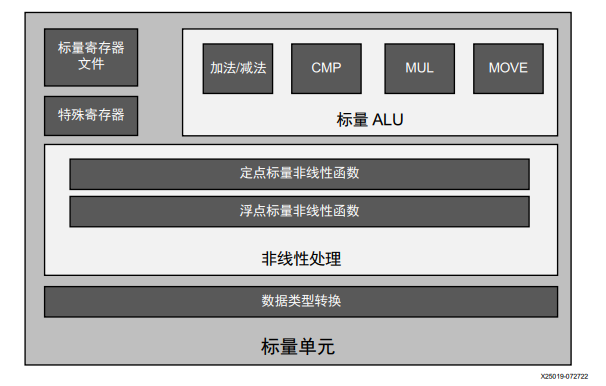
图:标量处理单元
获取完整版《AI 引擎内核编码最佳实践指南(UG1079)》,请扫描二维码进行下载。






