作者:Txu,AMD工程师;文章来源:AMD Xilinx开发者社区
增量实现自从首次获得支持以来,不断升级演变,在此过程中已添加了多项针对性能和编译时间的增强功能。
它解决了实现阶段针对快速迭代的需求,显著节省了编译时间,还能确保所得结果和性能的可预测性。
以下图表显示了在一整套困难的设计上采用增量实现流程后,所节省的编译时间的变化趋势:
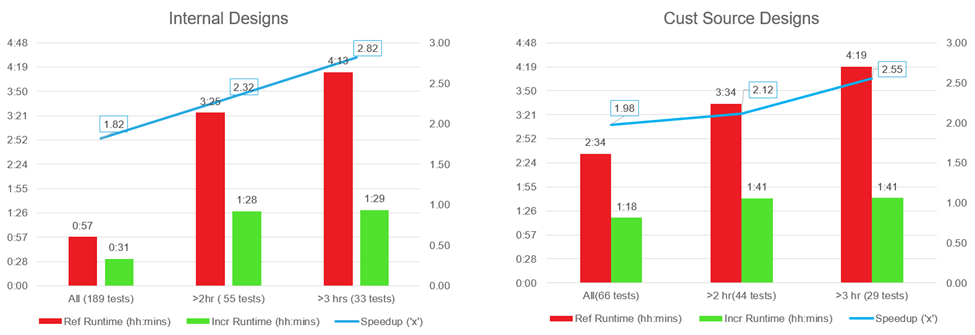
图 1:2019.1 内部设计和外部设计通过增量实现流程节省的编译时间
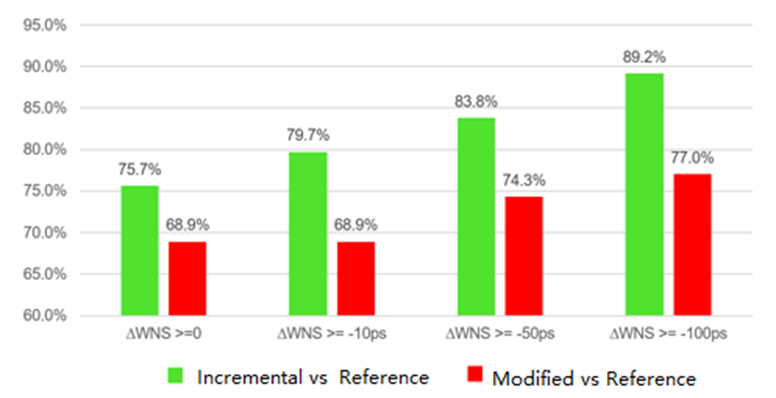
图 2:2019.1 利用增量实现流程保证 QoR 可预测性
图 1 显示,对于运行时间超过 2 小时的设计,使用该流程前的编译时间平均为使用后编译时间的 2.12 倍(设计更改最多为 10%),节省编译时间效果显著。
图 2 显示了少量 RTL 更改的 QoR 可预测性指标。ΔWNS 显示的是相较于参考运行轮次的 WNS 降幅。显而易见,相比于默认运行轮次,增量编译所得 QoR 可预测性更好。例外情况是,设计越小,初始化步骤在编译总时间中占用时间越多,所以应用增量编译给设计编译时间带来的助益就越少。
流程:
工程模式和非工程模式都支持此流程。如果您使用 read_checkpoint -incremental
在非工程模式下,read_checkpoint -incremental 应晚于 opt_design 而早于 place_design。
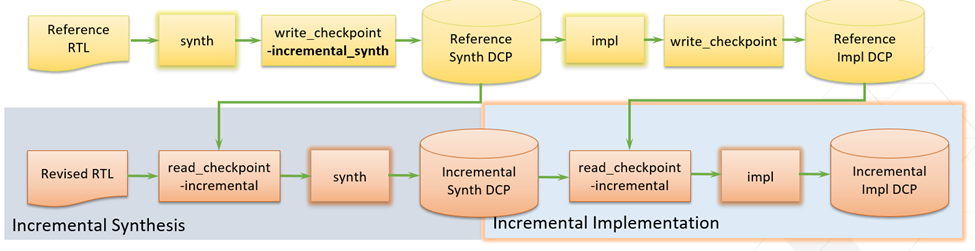
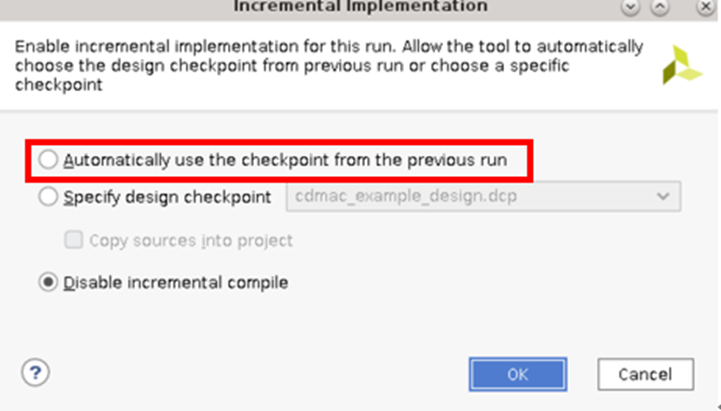
当前,自动模式和非自动模式均受支持。要启用自动模式,您可打开实现设置,并选中“Automatically use the checkpoint from the previous run”(自动使用上一轮运行的检查点)选项。如不勾选自动模式,也可将用户所需的 DCP 指定为参考检查点,以便指引后续轮次的运行。
何时使用此流程?
如果设计代码稳定并且可以后续执行少量代码修改,或者如果您当前正致力于时序收敛的最后冲刺阶段并且已接近完成,那么此流程很有用。在这两种情况下,您可能希望每个实现版本的生成周期都很短。
增量实现流程从参考检查点读取布局布线信息,并与当前 opt_design 后网表进行匹配比较。
匹配的单元将得到复用,新添加的逻辑经最优化后,将在默认流程中运行。匹配的单元与不匹配的单元之间也将进行交叉最优化。
因此,如果大部分逻辑可复用,并且设计接近满足时序,那么此流程对编译时间的助益最大。
另一个用例是,如果您的设计困难,且距离收敛相去甚远,但您想要在某些级别复用此设计(例如,SLR 级别、块类型级别、模块级别),那么也可以使用此流程。在此情况下,您可将增量模式更改为部分复用模式。
例如,以下约束行的效果等同于将所有 RAM 的位置从网表都反标注释到 XDC 内并在下一轮运行中应用约束:
read_checkpoint -incremental routed.dcp -reuse_objects [all_rams] -fix_objects [all_rams]
可能影响增量实现编译时间的因素
采用此流程前,请注意以下要点,这些要点有助于您充分发挥增量流程优势:
遵循默认运行行为时,Vivado 会遵循用户所选的运行策略,编译时间与非增量运行接近。
WARNING: [Project 1-964] Cell Matching is less than the threshold needed to run Incremental flow. Switching to default Implementation flow
有 3 条指令可供 place_design 和 route_design 使用:
Default(默认):获取与参考运行尽可能接近的结果。以参考设计 WNS 为目标。此模式能为典型用例达成最优化的编译时间。
Explore(探索):尝试尽可能改善时序。以 0.00 ns WNS 为目标。这会耗费更多编译时间。
Quick(快速):运行布局布线命令,不调用时序引擎。这可提供最优化的编译时间,在复用率高达 > 99.5% 的部分设计中,不影响 QoR。
在低复用模式下,支持所有 place_design 指令和 route_design 指令,并且该工具将以 0.00 ns 的 WNS 为目标。相比于高复用模式,这样可能会耗用更多编译时间。低复用模式对于在特定面积内难以完成布局布线的设计最有效。例如,复用正常运行的块存储器或 DSP 布局,或者复用间歇性达成时序收敛设计的特定层级。
在简短的布局布线运行中,Vivado 布局器和布线器的初始化开销可能会抵消来自增量布局布线进程的任何增益。对于运行时间较长的设计,初始化在运行时间中所占的比例较小,因此编译时间增益明显。
set_param general.maxThreads 8
生成增量编译时间节省报告
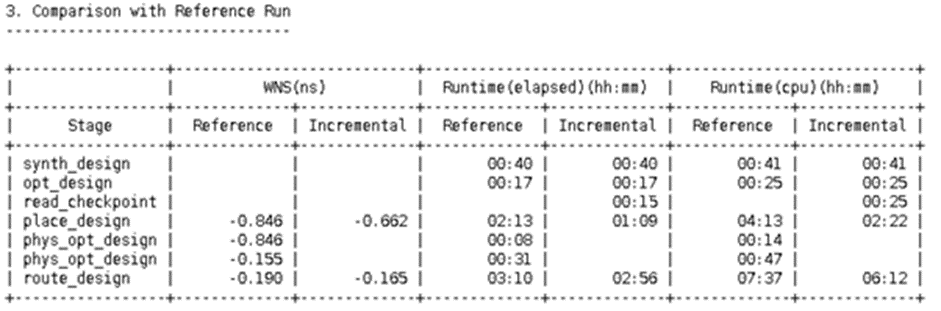
运行 report_incremental_reuse 命令,生成显示增量复用情况的报告。此报告的第 3 部分列出了编译时间(elapsed 和 cpu),显示了每一步耗费的编译时间。
由于增量运行的指引作用仅从 place_design 阶段开始,您需要注意,增量运行所涉时间将包含用于读入参考检查点的 read_checkpoint 步骤,并且增量编译时间的比较应仅从 place_design 开始。
下表显示了包含 read_checkpoint 在内的每个阶段的时间。
此外,新网表的更改量对增量运行时间的影响可能更大。
请注意,增量运行中的 phys_opt_design 步骤是可选步骤,在流程中调用该步骤时,它将以默认模式运行,以进一步优化未受指引的路径或已更改的路径,对复用的路径没有影响。
总结
通过采用增量实现流程,可以实现快速迭代的实现运行,但在运行此流程时需要考虑编译时间和 QoR(质量结果)方面的妥协。
如需了解有关此流程的更多详细信息,请参阅 (UG904)。