作者:Txu,来源:AMD Xilinx开发者社区
增量综合流程:
增量综合的工作方式与增量实现流程相似,但仅适用于综合阶段,并且不会对紧随其后的实现阶段给予引导。
此流程需独立的综合参考文件(综合后 DCP),因此您需完成初始综合运行以获取首个综合后 DCP 文件。增量运行会复用设计中未更改的部分,并且仅对已更改的部分进行重新综合。复用的各部分会在分区级别予以保留。
您可通过下文获取有关这些部分的保留方式的更多信息:
https://support.xilinx.com/s/article/976545?language=zh_CN
以下图表显示了含脚本的非工程流程:
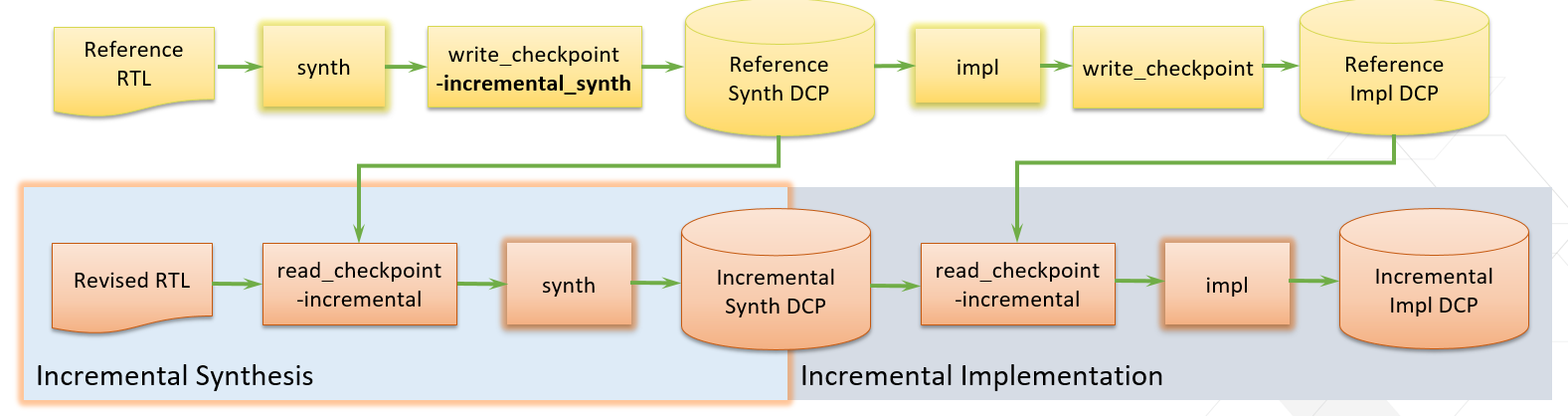
图:增量流程图表
在 GUI 中支持通过以下两种方法来指定参考检查点:
要在工程模式下启用自动模式,请打开综合设置,并选中“Automatically use the checkpoint from the previous run”(自动使用上一轮运行的检查点)选项。
在此模式下,综合运行将把最近的综合后网表自动复制到工程目录本地的
完成整个流程后,新布线的检查点即可立即用作为下一轮运行的参考检查点,并在运行复位时进行更新。 如不勾选自动模式,也可输入用户指定的 DCP 作为参考检查点,以便引导后续轮次的运行。

图:设计运行设置
何时采用此流程
当设计所含实例数量超过 50K 时,始终建议启用此流程。如果设计太小,由于改善的空间不够大,将忽略增量模式,设计将以正常流程运行。
当综合运行超过 20 分钟时,采用增量综合流程前后的运行时间平均比值为 2.06,改善显而易见。 下图显示了 26 个大型设计的加速趋势,在对设计进行有限的更改时,可节省大量编译时间(低至更改前的四分之一)。
下表所示每项设计所耗用的时间也证明,小幅更改设计的前提下,参考运行时间越长,通过增量运行节省的时间就越多。因此,大型设计利用该流程获益颇丰。
建议您始终为大型设计启用自动模式来运行增量综合。但要立即使用增量综合,必须向参考检查点写入综合数据。为此,可使用 write_checkpoint -incremental_synth 开关。


图:部分设计示例中的编译时间节省效果
此处随附的 getSynStepsRunTime.sh 脚本可用于为 synth_design 的每个阶段生成时间剖析表。
要运行该脚本,您可按如下示例所示使用此命令并为初始运行和增量运行生成表格。“actual”(实际)列和“phase”(阶段)列中罗列了用于每个阶段的时间和累计时间。
getSynStepsRunTime.sh ./vivado.log

增量综合运行期间,下列步骤的编译时间都比参考运行更短:“RTL Optimization”(RTL 最优化)、“Area Optimization”(面积最优化)、“Timing Optimization”(时序最优化)和“Technology Mapping”(技术映射)。
下表显示了用户设计示例。请注意参考运行与增量运行中每个综合阶段所耗费的时间。由于这些阶段占用了大部分的参考编译时间,因此对总体运行时间影响尤为显著。
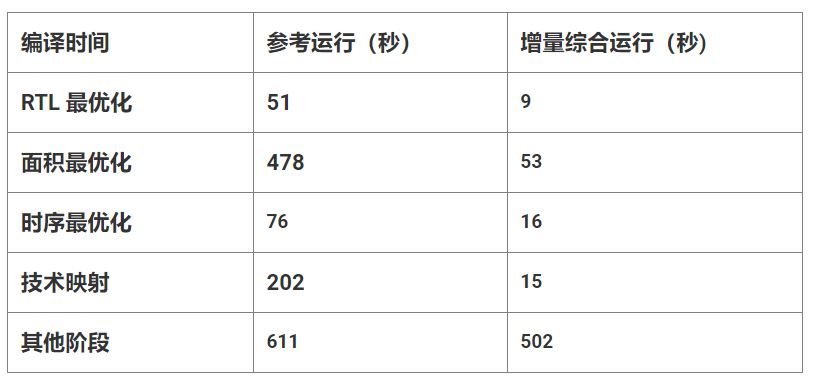
增量综合期间,“RTL Elaboration”(RTL 细化)、“Constraint Validation”(约束确认)、“Applying XDC Timing Constraints”(应用 XDC 时序约束)、“I/O Insertion”(I/O 插入)、“Global Opt”(全局最优化)、“Netlist Generation”(网表生成)等其他阶段以及其余用于拼接的阶段在时间上所呈现的改善较少。
注释:非关联流程 (out-of-context) 另有所用,它能让子模块像各 IP 一样来运作,因此需要更多手动干预,如创建模块封装文件和限定约束作用域。它也有助于改善编译时间,如果您有静态且无需更改的大型模块,那么此流程能节省该模块的最优化时间。
可能影响增量综合的因素
采用此流程前,以下操作有助于您充分发挥增量流程的优势:
另外,如果少量设计更改引入了参考设计中不存在的新时序问题,则可能需要增加工作量和运行时间,而且设计可能不满足时序。下图显示了 M1 模块和 M3 模块间路径因跨边界最优化而发生改变时,这两个模块进行重新综合的方式。
尽可能将更改局限在单一模块中,否则任何发生更改或消隐的分区都需重新综合。另外,为了防止发生跨边界最优化,您可在层级模块名称上使用 PRESERVE_BOUNDARY 属性,前提是您已寄存输入/输出模块端口。例如:
set_property BLOCK_SYNTH.PRESERVE_BOUNDARY 1 [get_cells [list {M1 M3}]]
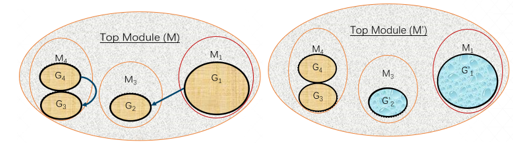
图:利用跨模块最优化情况下的综合参考运行对比增量运行
生成增量编译时间节省报告
综合运行 log 日志中包含网表复用百分比的详细信息。
在此示例中,仅对一个小型实例进行了修改,如果更改发生在某个子模块内,那么该表中也将列出该模块的名称。

总结
我们通过采用增量综合流程可以快速完成综合运行的迭代。该流程设置方便,并且对于设计一致性和编译时间节省都大有益处。如需了解更多详细信息,请参阅 (UG901)。





