近日,无问芯穹、清华大学和上海交通大学联合提出了一种面向 FPGA 的大模型轻量化部署流程FlightLLM,首次在单块 Xilinx U280 FPGA 上实现了 LLaMA2-7B 的高效推理。在单 batch 场景下,相比在同等工艺 V100S GPU 上使用 vLLM 推理框架和 SmoothQuant 量化库,FlightLLM 可实现 6.0 倍的能效比提升和 1.8 倍的性价比提升。相关工作现已被可重构计算领域顶级会议 FPGA’24 接收。

Both authors contributed equally to this work.
FlightLLM第一作者为清华大学电子系博士及无问芯穹硬件负责人曾书霖,通讯作者为上海交通大学副教授、无问芯穹联合创始人兼首席科学家戴国浩,清华大学电子工程系教授、系主任及无问芯穹发起人汪玉。
FPGA会议( ACM/SIGDA International Symposium on Field-Programmable Gate Arrays) 是FPGA(现场可编程门阵列,其主要特点是可编程的硬件结构)领域内最顶级的国际学术会议之一。据统计,2014至2023这十年间,被FPGA正式录取的工作中,来自中国研究团队主导的文章不足20篇。今年,FPGA 收到来自世界各地研究团队投稿90篇,最终收录23篇,录取率约为25.6%。其中Long Paper 19篇,Short Paper 4篇,本次无问芯穹团队被录取的工作FlightLLM属于Long Paper。
FlightLLM的目标是让大模型在边端延时敏感场景中的推理拥有更低能耗和更高性能。在这些场景中,行业内通常采用如稀疏化、量化的方法来压缩大模型以支持快反馈、低能耗的需求,而GPU 硬件平台仅能支持部分粗粒度的模型压缩方法,对于定制化的模型压缩方法的计算效率很低。
作者认为,FPGA 具有低成本、可配置、低功耗的特性,可成为加速大模型推理的潜在解决方案。但要想用好FPGA,仍需要解决计算效率不高、内存带宽利用率低和编译开销大的问题。FlightLLM 解决方案的核心思想是利用 FPGA 上特定的资源(如 DSP48 和异构存储层次结构)来解决这些挑战。
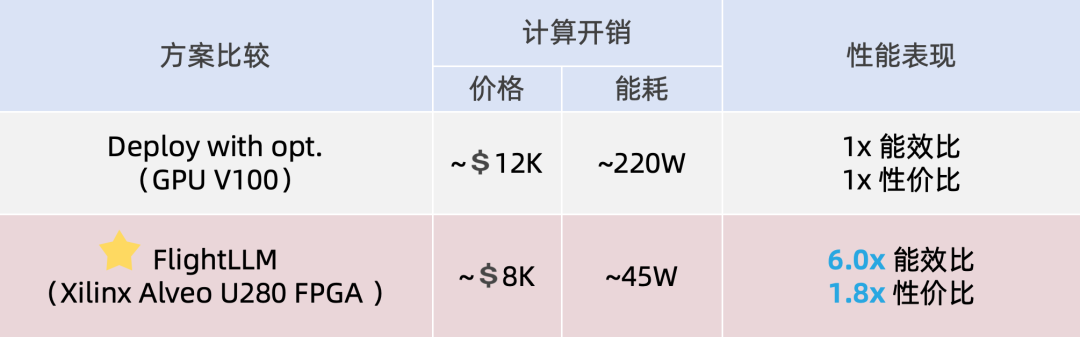
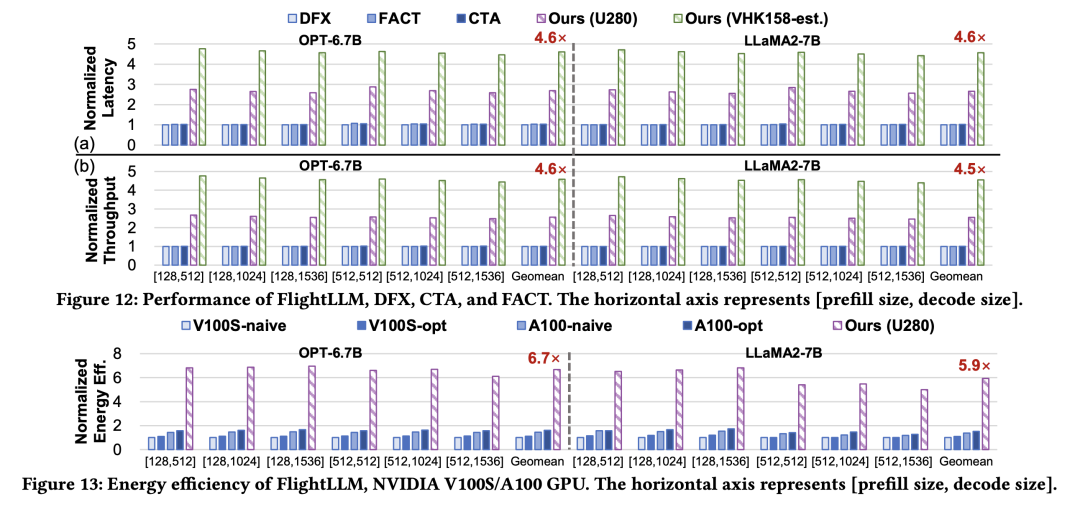
目前,作者已在 Xilinx Alveo U280 FPGA(16nm)上实现了 FlightLLM。在 OPT-6.7B 和 LLaMA2-7B 上的实验结果表明,FlightLLM 的端到端延迟优于 NVIDIA V100S GPU。此外,FlightLLM(基于 U280 FPGA 和 VHK158 FPGA)在能效上超过了 NVIDIA V100S 和 A100 GPU,分别提高了 6.0× 和 4.2×,在性价比上提高了 1.8× 和 1.5×。
一位给出了满分评价的审稿人在审稿意见中表示,“这(FlightLLM)是一项浩大的工程,作者提出了一种高度灵活的大模型架构,使量化和稀疏化得到了充分利用。这是一场全面‘对抗’GPU的‘战争’,我喜欢这个结果。”

在几乎所有可能对未来世界产生重大影响的产、研趋势中,高性能计算都处于关键位置。虽然设备的核心计算部件仍是 CPU 和 GPU ,但在一个人工智能算法不断进步、新标准不断涌现的时代里,加速这些日新月异的算法推理工作并保持灵活可变性是至关重要的。
在软硬件协同优化趋势下,FPGA 在灵活构建高效的大模型推理系统中将发挥越来越重要的作用。它被广泛地认为是通往 5G 通信、数据中心、无人驾驶等诸多千亿美元级别市场的钥匙。
伴随着这一部署流程的验证成功,无问芯穹正在将相应能力迁移到更多元硬件和商用集群中,并继续保持性能和能效上的领先性。目前FlightLLM 推理框架已被集成于无问芯穹服务于算力统一管理、调度、运营和运维的智算一体化平台Infini-AgilePod。结合无问芯穹大模型计算加速引擎Infini-ACC的软件能力,支持智算中心、私有化集群、边缘设备、端设备等多种芯片部署方式。为各类大模型任务的运行提供完整、便捷的工具集合,提升端到端运行效率。
本文转载自:无问芯穹





