作者:Florentw,AMD工程师;来源:AMD开发者社区
简介
在先前 AI 引擎系列博文中,我们讲解了 AI 引擎域上的 AI 引擎应用。
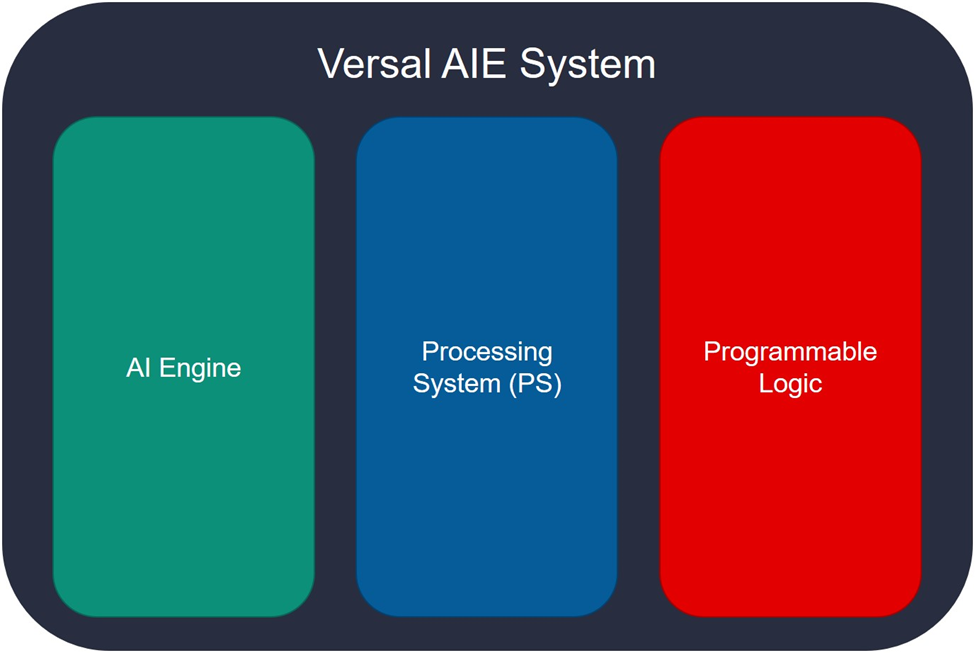
但正如我们在 AI 引擎系列的第一部分中所见,要在 Versal™ 硬件上运行 AI 引擎应用,很可能需要将 3 个域结合在一起来使用:AI 引擎、处理器系统 (PS) 与可编程逻辑 (PL)。
在本文中,我们将演示在这 3 个不同域上运行的完整系统示例。
要求
以下教程要求您:
- 对 AMD 工具有基本了解
- 具有 C/C++ 编程语言的基本知识
- 已安装 Vitis™ 2021.1 统一软件平台
- 拥有有效的 AI 引擎工具许可证
- 从 Xilinx.com(链接)或从 GitHub(链接)下载的 VCK190 基础平台
- 通读前几篇 AI 引擎系列博文
打开完整系统工程示例
这是 Vitis IDE 中集成的完整系统工程示例。我们将使用 AI 引擎系列 1 一文 中所述步骤将其打开。
1) 打开 Vitis 2021.1 统一软件平台 IDE,选择工作空间存储库。
2) 在“Welcome”(欢迎)页面上,单击“Create Application Project”(创建应用工程),如果未显示“Welcome”页面,请单击“File > New > Application Project”(文件 > 新建 > 应用工程)
3) 在显示的“Welcome”页面上,单击“Next”(下一步)。
4) 在平台选择页面上,选择 xilinx_vck190_base_202020_1 平台,然后单击“Next”。
注意:如果该页面中未列出名为 xilinx_vck190_base_202020_1 的平台,请确保您已从 GitHub 或 Xilinx.com 下载该平台
5) 使用“Add”(添加)按钮添加该仓库。
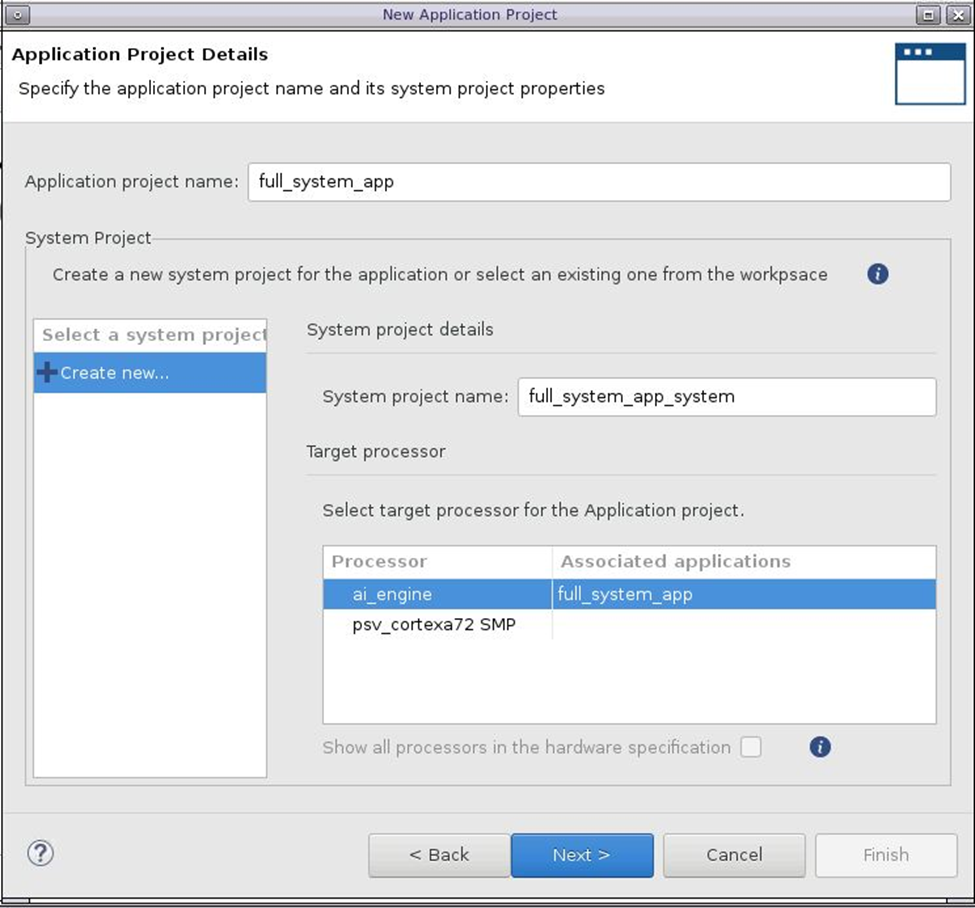
6) 创建名为 full_system_app 的新应用,该应用将在 ai_engine 上运行,然后单击“Next”:
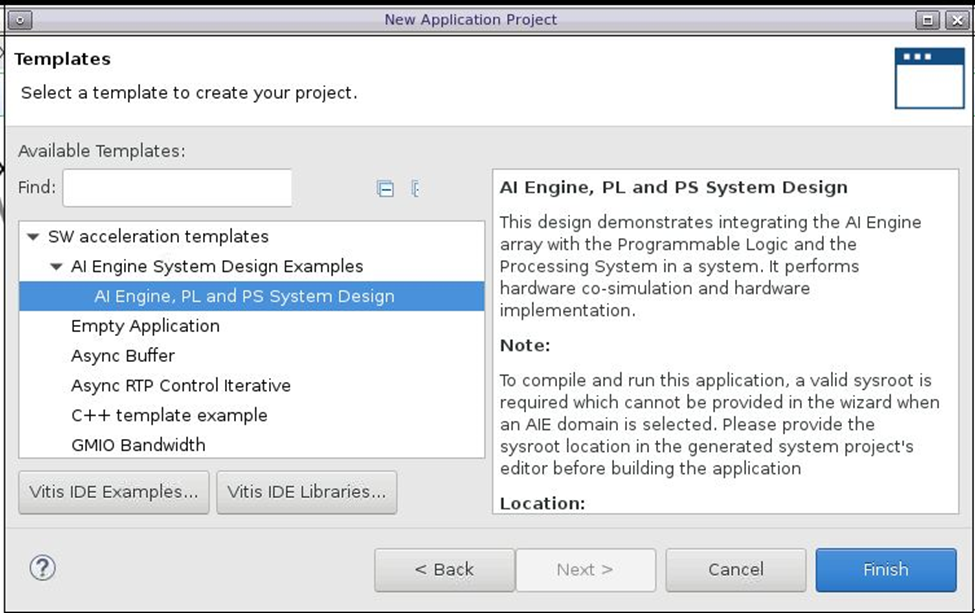
7) 在“Domain”(域)页面上,单击“Next”。
在“Templates”(模板)页面上,选择“AI Engine, PL and PS System Design”(AI 引擎、PL 和 PS 系统设计):
分析模板系统
在“Explorer”(资源管理器)窗口中,可以看到创建的 full_system_app_system 工程包含 4 个子目录:
full_system_app_aie [aiengine]:这是将在 AI 引擎域上运行的应用。
full_system_app_kernels:该目录包含 RTL 内核,这些内核将在 PL 中执行,用于将 PL 域连接到 AI 引擎域。请注意,在其他系统中,RTL 内核也可能完全独立于 AI 引擎。
full_system_app_system_hw_link:该目录将包含最终系统,其中所有域都连接在一起
full_system_app [xrt]:这是 PS 上运行的应用。

RTL 内核
展开 full_system_app_kernels 目录,并打开 full_system_app_kernels.prj。
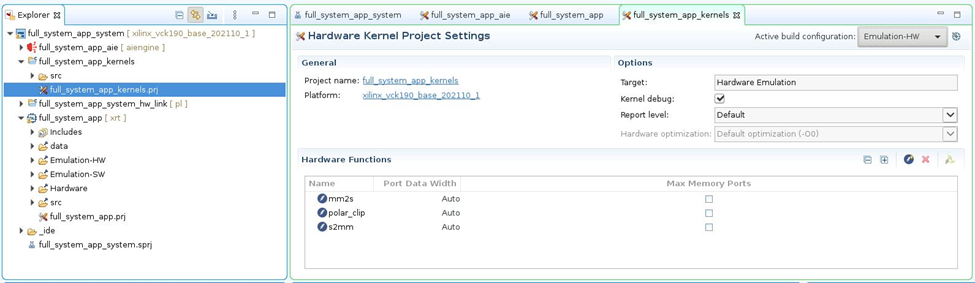
在“Hardware Functions”(硬件函数)部分中可见,该工程包含 3 个 RTL 内核。MM2S(存储器映射到串流)和 S2MM(串流到存储器映射)都属于 Data Mover IP,将用于为 AI 引擎馈送源自 DDR 存储器的数据。polar_clip 内核是处理内核,将接收来自 AI 引擎的数据,处理后将其发回给 AI 引擎。
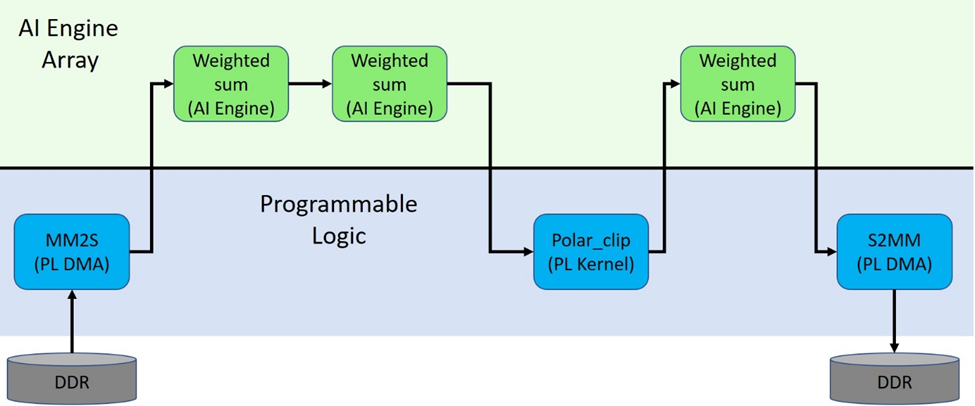
我们利用现有信息即可开始绘制系统视图,如下所示:

AI 引擎应用
现在来看看 AI 引擎应用中的 AI 引擎计算图 (graph)。打开 full_system_app_aie/src 下的 graph.h 文件
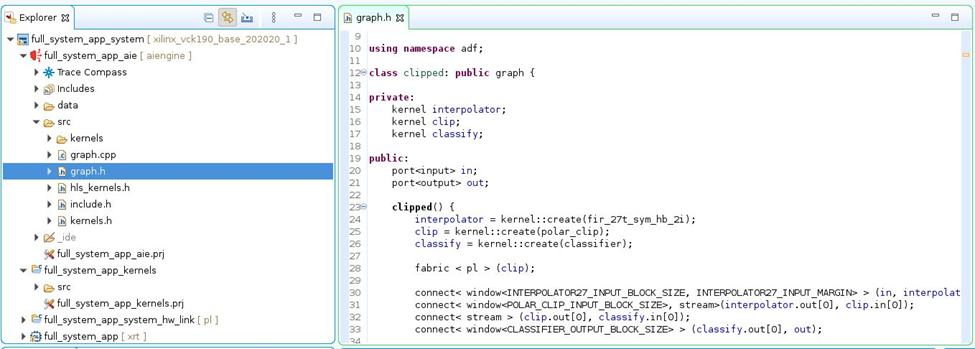
在 graph.h 文件中,可以看到此计算图包含 2 个内核:interpolator 和 classify。
interpolator = kernel::create(fir_27t_sym_hb_2i);
classify = kernel::create(classifier);
这些内核与计算图端口之间的连接定义如下:
graph.in -> interpolator -> graph.clip_in → graph.clip_out -> classify -> graph.out
connect< window<INTERPOLATOR27_INPUT_BLOCK_SIZE, INTERPOLATOR27_INPUT_MARGIN> >(in, interpolator.in[0]); connect< window<POLAR_CLIP_INPUT_BLOCK_SIZE>, stream >(interpolator.out[0], clip_in); connect< stream >(clip_out, classify.in[0]); connect< window<CLASSIFIER_OUTPUT_BLOCK_SIZE> >(classify.out[0], out);
打开 graph.cpp 文件。在该文件顶部有 4 个 PLIO(要连接到 PL 的 I/O),分别名为 in0、out0、pl_to_ai_source 和 ai_to_pl_sink,这些 PLIO 均已定义、已添加到平台并已连接到该计算图。
PLIO *in0 = new PLIO("DataIn1", adf::plio_32_bits,"data/input.txt"); PLIO *out0 = new PLIO("DataOut1",adf::plio_32_bits, "data/output.txt"); PLIO *pl_to_ai_source = new PLIO("polar_clip_in",adf::plio_32_bits, "data/input1.txt"); PLIO *ai_to_pl_sink = new PLIO("polar_clip_out", adf::plio_32_bits,"data/output1.txt"); simulation::platform<2,2> platform(in0,pl_to_ai_source, out0,ai_to_pl_sink); clipped clipgraph; connect<> net0(platform.src[0], clipgraph.in); connect<> net1(clipgraph.clip_in,platform.sink[1]); connect<> net2(platform.src[1],clipgraph.clip_out); connect<> net3(clipgraph.out, platform.sink[0]);
我们利用此新信息即可更新系统视图,如下所示:
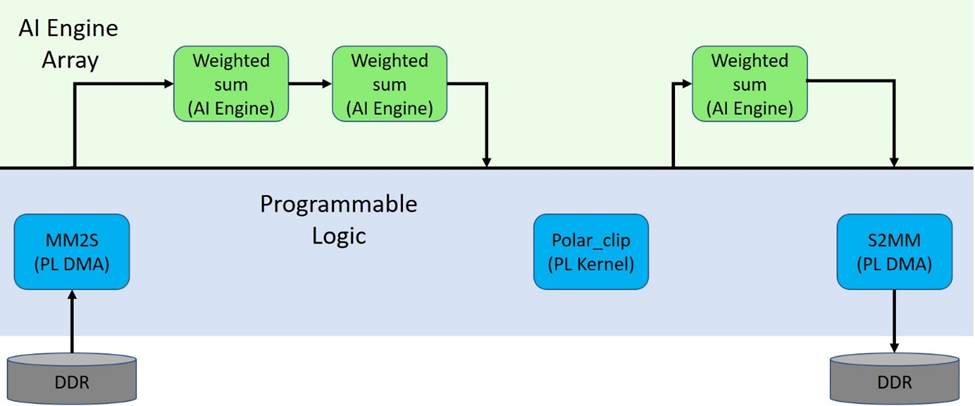
但在 MM2S、S2MM 和 polar_clip PL 内核与 AI 引擎之间缺少连接。此连接是在硬件链接应用中通过 v++ 来建立的。
硬件链接应用
v++ 硬件链接应用用于将各域(主要是 AIE 与 PL)连接在一起。只需观察传递给 v++ 的选项即可检查将要建立的连接。
在“Assistant”(助手)视图中,右键单击 full_system_app_system/full_system_app_hw_link/Emulation-HW 下的 binary_container_1,然后单击下列设置:

在“Binary Container Settings”(二进制容器设置)中,查看 v++ 配置设置:
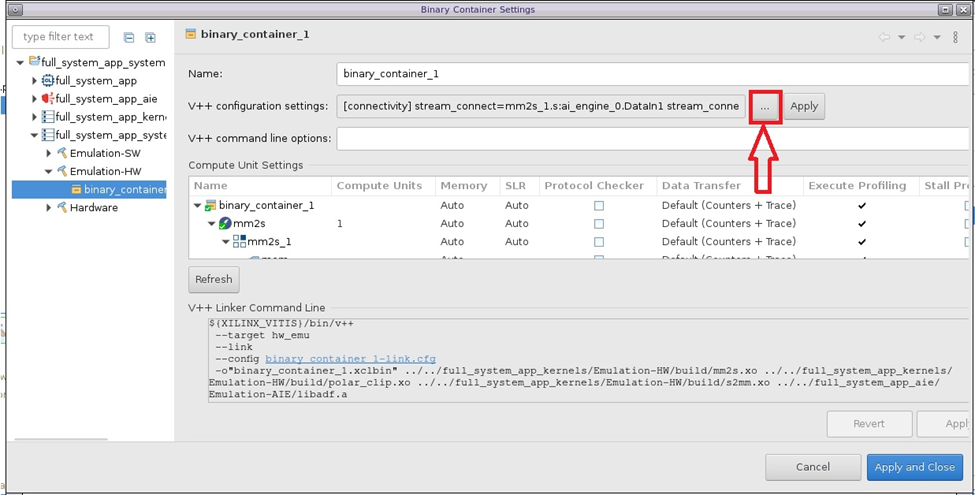
这将打开以下窗口以显示 v++ 配置设置:

从中可见,已指定下列连接选项:
[connectivity]
stream_connect=mm2s_1.s:ai_engine_0.DataIn1
stream_connect=ai_engine_0.DataOut1:s2mm_1.s
根据《AI 引擎工具和流程用户指南》(UG1076) 所述,计算单元(或内核实例)的命名约定是 <kernel>_#,其中 # 表示 CU 实例。
因此,对应于该工程内的内核 mm2s、s2mm 和 polar_clip 的 CU 名称分别是 mm2s_1、s2mm_1 和 polar_clip_1(使用 Vitis GUI 时,CU 的第一个实例始终是
例如,在此工程中,要将 mm2s_1(计算单元名称)的名为 s(内核接口名称)的 AXI4-Stream 接口连接到 ai_engine_0(计算单元名称)IP 中计算图的 DataIn1(接口名称)输入,所使用的选项如下:
stream_connect=mm2s.s:ai_engine_0.DataIn1.
这样即可完成系统视图,如下所示:
后续步骤
在下一篇博文中,我们将构建系统、分析部分生成的输出,并在硬件仿真中运行。