本文继续探讨微控制器 (uC) 到现场可编程门阵列 (FPGA) 接口。
第1 部分 1介绍了指导大型系统开发的 Verilog 设计理念。这是介绍寄存器传输电平 (RTL) 设计准则的关键部分,如时钟边界、频闪器的使用和双缓冲区的必要性。
第2部分 1介绍了 SPI 协议。回想一下,所选协议改编自802.3以太网帧,具有可变有效载荷长度和循环冗余校验 (CRC) 等概念,以提供数据完整性的度量。
第3部分 1介绍了 uC 到 FPGA 接口的高级视图。那篇文章中最重要的部分是这里重复的框图,作为图1,以方便你。
这一期的重点是框图的右上角。具体来说,就是可扩展双缓冲区的操作。
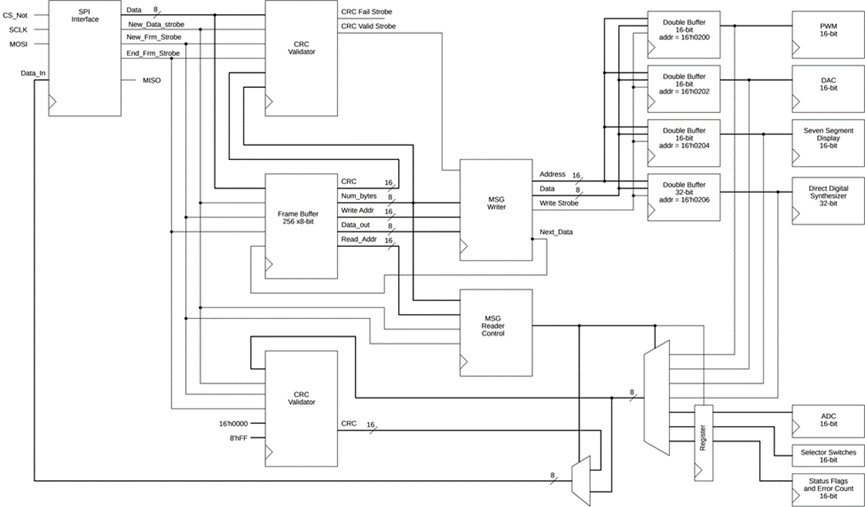
图 1 :显示FPGA数据流的顶层FPGA框图。
PWM 的回顾
在介绍双缓冲器之前,我们将简要探讨 Verilog 脉宽调制器 (PWM) 的工作原理。这一点很重要,因为双缓冲区最好被看作是硬件模块 (如 PWM) 的可寻址接口。
PWM 模块的顶层接口在这个 Verilog 代码片段中描述。观察该模块使用了位宽参数,并建立了最小和最大占空比限制。最后,观察PWM模块有一个[B - 1:0]输入矢量来设置占空比。没有显示的是在每个 PWM 占空比开始时读取输入的事实。
module PWM #(parameter
B = 12, // implies a 24.4 kHz PWM assuming a 100 MHz system clock
D_MIN_PERCENT = 0,
D_MAX_PERCENT = 95
)
(
input wire clk,
input wire enable,
input wire [B - 1:0] d_in,
output reg PWM,
output reg [B - 1:0] cnt
);
同步数据呈现
如图1所示,PWM 设计用于在更大的 uC 到 FPGA SPI 系统中工作。回想一下,SPI自然地使用字节宽度的数据元素进行操作。这与使用B定义的数据宽度操作的PWM形成鲜明对比。为了方便,我们假设 PWM 以16位的位宽度(B)实例化。
当系统更新与 PWM 输入相关的寄存器时,会出现一个问题。如果没有适当的注意,PWM 可能会在更新过程中执行读取操作。其结果是驱动器字节被分割成一个旧字节和一个新字节。这可能导致占空比的显著跃升,持续一个 PWM 周期。如果 PWM 用于 LED 指示灯,则可能不会注意到这一点。在更复杂的系统中,故障相当于一个强脉冲,并可能导致系统响铃或变得不稳定,具体取决于错误发生的时间和频率。
解决方案是实现前几篇文章中提到的双缓冲方案,后面将进行深入讨论。使用一组寄存器来捕获单个字节。当收集到完整的n字节数据时,更新第二个更宽的寄存器。第二个寄存器-双缓冲区-然后用于驱动其他模块,如代表性的 PWM。
双缓冲模块
双缓冲模块的框图如图2所示。在内部,它由四个主要部分组成。最重要的是输出寄存器。在这个例子中,它是16位宽,使其适合驱动16位 PWM。输出寄存器由单个8位寄存器驱动,在本例中它们被标记为 LSB 和 MSB。注意,所有的寄存器更新都是由双缓冲区的控制部分发起的。这是一个同步操作,其中所有元素响应主 100mhz时钟的滴答声。
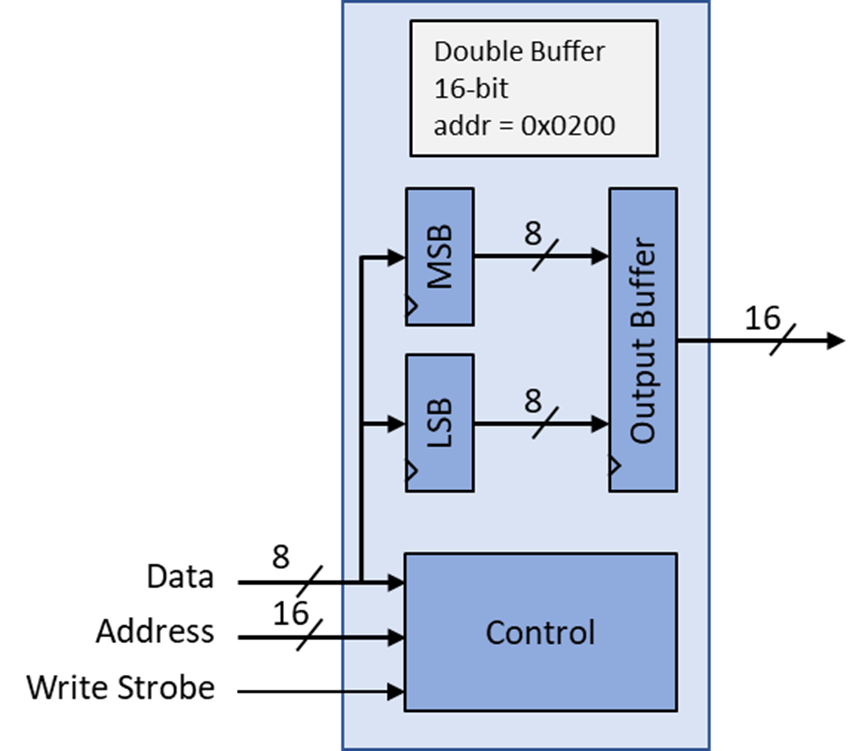
图 2 :双缓冲区的框图,显示了单个8位缓冲区与输出缓冲区之间的关系。
重要的是要理解,每个双缓冲区模块都是用特定的地址和特定的字节宽度实例化的,如下面的代码清单所示。注意,16位地址、8位数据和写频闪都涉及到加载缓冲区。当16位地址输入与实例化地址匹配时,数据传输就开始了。
module double_buffer #(
parameter BYTE_WIDTH = 2,
parameter BASE_ADDRESS = 16'h0200 // Starting address for the MSB
) (
input wire clk,
input wire [7:0] data,
input wire [15:0] address,
input wire write_strobe,
output reg [((8 * BYTE_WIDTH) - 1): 0] double_buffer_out,
output reg new_data_strobe
);
如图1和图2所示,这个 uC 到 FPGA 接口有一个底层的8位传输过程。在文章#2中首先介绍的命令帧中也隐含了一个连续写入操作。为了方便起见,这里将命令帧重复为图3。作为一个例子,让我们假设 PWM 和相关的双缓冲区以地址0x0200实例化。命令帧的写地址将被设置为0x0200,负载的前两个字节将保持所需的16位 PWM 值。

图 3 :构成uC到FPGA SPI协议基础的命令和响应帧。
当接收并验证命令帧时,MSG 写块(参见图1)将断言地址0x0200,该地址指向 PWM 的双缓冲区。它将把第一个有效载荷字节放到数据总线上。最后,它将为一个时钟周期断言写频闪。这将加载如图2所示的 MSB (大端)。
继续进行连续写入,MSG 写入器向前推进地址,断言下一个数据字节,然后脉冲写入频闪,从而将 LSB 加载到双缓冲区中。这个过程对命令帧中的每个字节继续进行,由帧的字节长度字段控制。
从本质上讲,消息编写器并不了解相关的双缓冲区的长度。它只关心断言地址、数据和写频闪的三步过程。这取决于双缓冲区模块来理解它们何时被寻址,以及何时接收到 BYTE_WIDTH 参数指定的必要字节数。
由于双级缓冲区的基址和字节宽度在实例化时是已知的,因此很容易确定何时接收到所有字节。在这个 PWM 示例中,双缓冲器计数到2,然后发送一个频闪来加载输出寄存器。
技术贴士 :数据可能首先访问最高有效字节 (MSB) 或最低有效字节 (LSB)。描述顺序的术语是“端序” (endian)。如果 MSB 先出现,则系统为大端序。如果 LSB 是第一个,则系统是小端序的。本文描述的双缓冲区和关联帧是大端序。
双缓冲区代码
双缓冲区的 Verilog 代码附在本注释的末尾。代码紧跟图2的框图,理解它可以扩展到n字节的宽度。这可以通过更改 BYTE_WIDTH 参数来实现。
这段代码的关键是 Verilog 生成操作符的使用。回想一下,generate 特性允许迭代地生成硬件。它的运作方式就像一个制造小部件的工厂。除了,在这种情况下,我们正在制作8位寄存器,其程序集的总数等于 BYTE_WIDTH 参数。我们可以在 Vivado 分层设计窗口中看到这一点,如图4所示。这些“制造”的块与它们在生成循环中定义的连续命名方案一起出现。
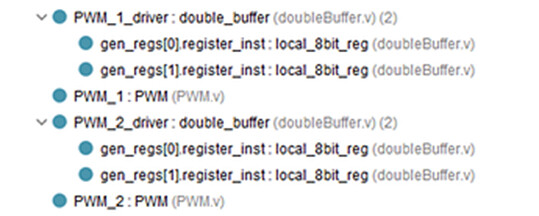
图 4 :在双缓冲区实例化中可以看到生成的字节宽度寄存器。
观察每个生成的9位寄存器都包含一个对应的 local_write_strobe。这是一个重要的设计方面,因为 “control” 部分使用它来加载相关的8位寄存器。
除了寄存器之外,生成循环还制造一个8位向量,每个8位寄存器的输出都连接到这个向量上。然后将这些N × 8位的包连接起来并传递到n字节输出寄存器。
代码的最后一部分确定n字节何时被收集。然后它更新输出寄存器并发送一个new_data_strobe。
控制部分有三个基本功能:
1. 当基址与实例化地址匹配时激活模块。
2. 维护一个计数器指向“制造的”8位寄存器。这个计数器对于连续写入是必不可少的。
3. 对相关的8位寄存器进行频闪。
4. 当N个8位寄存器被填满时,对输出缓冲区进行频闪。
技术贴士 :矢量是导线的一维数组。一个例子是“input wire [15:0] address”,它定义了一个16位的名为 address 的向量。
第4部分结束
虽然这段代码确实很复杂,但 Verilog 生成操作符提供了很大的灵活性。它消除了为每个期望的字节宽度构建独立模块的需要。
在下一部分中,我们将探讨基于 Verilog 的 CRC 生成器的操作。当这篇文章完成后,你将看到 FPGA 如何处理图3中所示的帧。
//**************************************************************************************************
//
// Module: Parameterized and Addressed Double Buffer
//
// This RTL is subject to Terms and Conditions associated with the
// DigiKey TechForum. Refer to:
// https://www.digikey.com/en/terms-and-conditions?_ga=2.92992980.817147340...
//
// Should you find an error, please leave a comment in the forum space below.
// If you are able, please provide a recommendation for improvement.
//
//**************************************************************************************************
// ______________________________________________
// | |
// | Module: double_buffer |
// | |
// | Parameters: |
// | BYTE_WIDTH = 4 |
// | BASE_ADDRESS = 16'h0000 |
// |______________________________________________|
// | |
// ==8=| data double_buffer_out |=V==
// ----| write_strobe new_data_strobe |----
// | |
// ----| write_strobe |
// | |
// ----| clk |
// |______________________________________________|
//
//
//** Description ***********************************************************************************
//
// This module works with a stream of parallel data. When the streamed address matches the
// parameterized address the module will store the byte width data into a buffer. The
// module than accepts consecutive data storing each byte in the associated buffer. When the
// module has received BYTE_WIDTH bytes, the data are transferred to the output buffer.
//
//** Instantiation *********************************************************************************
//
// double_buffer #(.BYTE_WIDTH(2), .BASE_ADDRESS(PWM_1_address) )
// PWM_1_driver(
// .clk(clk),
// .data(MSG_writer_data),
// .address(MSG_writer_address),
// .write_strobe(MSG_writer_strobe),
// .double_buffer_out(PWM_1_drive),
// .new_data_strobe(new_data_strobe) // optional
// );
//
//** Signal Inputs: ********************************************************************************
//
// 1) clk: High speed system clock (typically 100 MHz)
//
// 2) data: An 8-bit input. Data will be captured when address is within
// BASE_ADDRESS + BYTE_WIDTH (non-inclusive).
//
// 3) address: A 16-bit input. The module will respond to BYTE_WIDTH consecutive address starting at
// BASE_ADDRESS extending to BASE_ADDRESS + BYTE_WIDTH (non-inclusive).
//
// 4) write strobe: When pulsed, the data will be locked into the associated input buffers provided
// the address is within BASE_ADDRESS + BYTE_WIDTH (non-inclusive).
//
//** Signal Outputs ********************************************************************************
//
// 1) double_buffer_out: This BYTE_WIDTH is the output buffer in this double buffer module. It is
// updated in a single clock cycle after all the individual buffers have been updated. There
// is a one clock delay between the filling the last byte-wide buffer and a double buffer update.
//
// 2) new_data_strobe: a pulse active for the same clock cycle in which the double_buffer is updated.
//
//** Comments **************************************************************************************
//
// 1) TODO, Consider eliminating the one clock cycle delay and eliminating the most significant
// byte input register. Use care for a single byte instantiation.
//
//**************************************************************************************************
module double_buffer #(
parameter BYTE_WIDTH = 4,
parameter BASE_ADDRESS = 16'h0000 // Starting address for the MSB
) (
input wire clk,
input wire [7:0] data,
input wire [15:0] address,
input wire write_strobe,
output reg [((8 * BYTE_WIDTH) - 1): 0] double_buffer_out,
output reg new_data_strobe
);
//** CONSTANT DECLARATIONS *************************************************************************
/* General shortcuts */
localparam T = 1'b1;
localparam F = 1'b0;
//** Body *******************************************************************************************
wire [8*BYTE_WIDTH-1:0] concat_result;
reg delay_one_clk;
wire [7:0] buffer_data_out[BYTE_WIDTH-1:0]; // Array of 8-bit wires
// Generate N 8-bit registers
generate
genvar i;
for (i = 0; i < BYTE_WIDTH; i=i+1) begin: gen_regs
wire local_write_strobe = write_strobe && (address == BASE_ADDRESS + i); // Asserted only when the address matches
local_8bit_reg register_inst (
.clk(clk),
.data(data),
.write_strobe(local_write_strobe),
.q(buffer_data_out[i])
);
end
endgenerate
// Concatenate the outputs of the N 8-bit buffers dynamically
generate
genvar j;
assign concat_result[7:0] = buffer_data_out[0];
for (j = 1; j < BYTE_WIDTH; j=j+1) begin: gen_concat // Note the use of the + operator with the loop starting at 1 not 0
assign concat_result[j*8 +: 8] = buffer_data_out[j];
end
endgenerate
always @(posedge clk) begin // Delay one clock for the double buffer operation to
// allow data to be clocked into the last of the
// individual registers.
new_data_strobe <= F; // Default
delay_one_clk <= F;
if (write_strobe && (address == (BASE_ADDRESS + BYTE_WIDTH - 1))) begin
delay_one_clk <= T;
end
if (delay_one_clk)begin
double_buffer_out <= concat_result;
new_data_strobe <= T;
end
end
endmodule
module local_8bit_reg (
input wire clk,
input wire [7:0] data,
input wire write_strobe,
output reg [7:0] q
);
always @(posedge clk) begin
if (write_strobe) begin
q <= data;
end
end
endmodule
本文转载自:Digikey





