本文是该系列的第18篇。数字信号处理的内容博大精深,音频信号处理、数字图像处理、雷达信号处理等等都属于DSP系统。从本文开始将记录一些简单的音频信号处理算法在System Generator中的实现方法。本文将介绍如何搭建音频信号的采集与输出模型。
音频信号基础概念
音频信号属于一维信号,一些基本概念如下:
单声道音频信号采集与输出
1.搭建模型
在Simulink中添加block按下图连接:
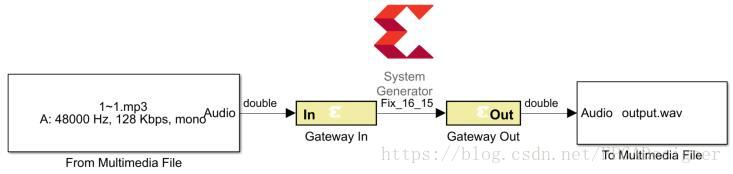
Simulink的Audio System Toolbox中包含了与音频相关的block。上图中的From Multimedia File的作用是读取音频文件,音频文件的相关信息会显示在图标上(mono即表示单声道):

“File name”中选择音频文件路径;“Number of times to play file”设置从文件中读取的音频信号时间;“Samples per audio channel”设置每个通道读取出的采样点数。音频信号需要通过Gateway In输入到FPGA,但Gateway In不能接收向量型数据,因此这个值通常设置为1更方便。
To Multimedia File用于将信号以指定音频格式写入文件:
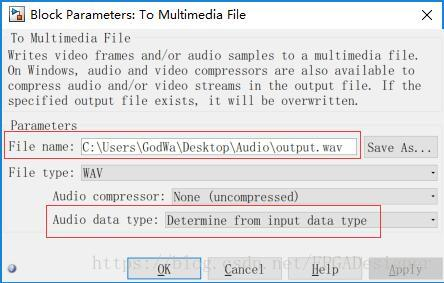
“File name”设置输出音频文件的路径;“File type”设置输出音频文件格式;“Audio compressor”选择采用的音频压缩算法;“Audio data type”设置输出音频的数据格式,这里设置为与输入相同。
此外,Audio System Toolbox中还有Audio Device Reader可以读取麦克风的音频数据;Audio Device Writer可以直接用扬声器播放声音而不用保存文件。但模型中使用这两个block时,仿真用时会比采用文件格式的输入输出长很多,因此在后面几篇的设计中都采用文件格式做音频采集与输出。
2.仿真验证
现在单声道的音频文件很难找,因此使用“格式工厂”将立体声音频文件转换为单声道音频文件,用于设计仿真。System Generator和Gateway In的采样频率设置为48000Hz,仿真时长设置为10s,即只采集和输出10s的音频信号。
本设计采集到音频信号后不做任何处理直接输出,播放输出的音频文件。仿真过程中的几个注意项以列表形式给出:
单声道采集、立体声输出
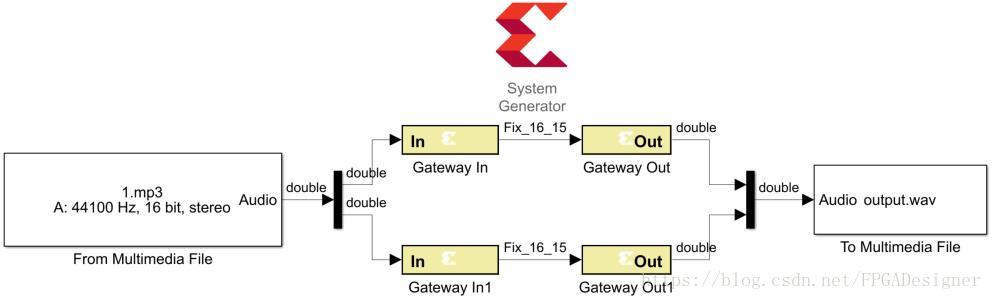
To Multimedia File这个block支持向量形式输入,会导出立体声音频文件。使用Simulink中mux可以将多路数据组合为一路。模型连接图如下:

采集的单声道音频分为两路,为了区别左右声道一路经过一定单位的延时,再由Mux组合成向量形式输出为立体声音频文件。延时的方法只是粗略的实现了效果,实际中会采用一些专门的DSP算法达到更好的音效。
立体声采集与输出
如果From Multimedia File读取的是立体声音频文件,会以向量的形式输出数据。如果把立体声音频信号直接接到Gateway In会提示如下错误:

System Generator block只支持标量数据类型。Gateway In的图标中输入数据也变成了“?”。需要采集立体声音频时,必须用demux这个block将各声道的音频分开,分别进行信号处理。模型如下图:
本文介绍了单声道和立体声音频信号在System Generator系统中的采集和输出方法,可以在此设计的基础上,在中间加入DSP算法做语音信号处理。
语音信号数字滤波
以前面文章讲述过的FIR数字滤波为例,做一个简单的DSP处理。语音信号的频率范围为300~3400Hz,老式电话通常选用8000Hz作为采样频率。设计一个FIR滤波器,将声音信号转换为“电话音”,按下图连接model:
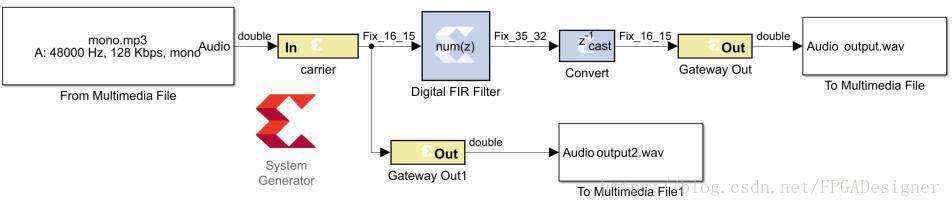
Digital FIR Filter的滤波系数配置如下:

对输入的信号用8000Hz重新采样,通带范围为300~3400Hz。Convert截取滤波输出信号的位宽。运行仿真,播放输出音频,会发现其声音如同电话中的声音一样。
文章来源:FPGADesigner的博客
*本文由作者授权转发,如需转载请联系作者本人





