ZYNQ MPSOC 搭建 LeNet-5 卷积神经网络
wyh102 在 周三, 10/25/2023 - 08:40 提交
LeNet-5 是一个非常经典和成功的卷积神经网络结构
LeNet-5 是一个非常经典和成功的卷积神经网络结构

Ultra96-V2支持使用PYNQ进行开发,PYNQ提供了一种利用Python在顶层通过overlay方式烧录FPGA相关的IP

赛灵思与魔视智能今日宣布,双方正合作推出一款面向汽车市场的解决方案。它将赛灵思车规级( XA ) Zynq® 片上系统( SoC )平台与魔视智能的卷积神经网络( CNN )IP 相结合,专门用于前视摄像头系统的车辆感知与控制。

本文描述 DPUCAHX8H,这是一种用于具有 HBM 的 Alveo 卡的高吞吐量 CNN 推理 IP。DPUCAHX8H 针对小图像尺寸网络进行了优化。

本文介绍 DPUCVDX8G,这是一种可配置的计算引擎,针对具有 AI 引擎的 Versal ACAP 设备中的卷积神经网络进行了优化。
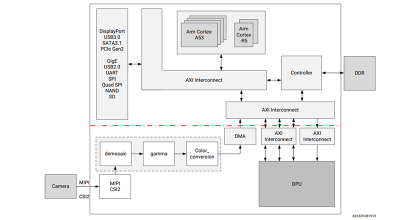
本文描述了用于卷积神经网络的 DPU。

对于 AI 推断,在提供与浮点媲美的精度的同时,int8 的性能优于浮点。然而在资源有限的前提下,int8 不能满足性能要求,int4 优化是解决之道。通过 int4 优化,与现有的 int8 解决方案相比,赛灵思在实际硬件上可实现高达 77% 的性能提升。

INT8提供了比浮点数更好的性能,精度可与AI推论相比。但是,如果INT8在有限的资源下无法满足所需的性能,则INT4优化就是答案。通过INT4优化,与当前的INT8解决方案相比,Xilinx可以在实际硬件上实现高达77%的性能提升。

针对卷积神经网络(CNN)在通用CPU以及GPU平台上推断速度慢、功耗大的问题,采用FPGA平台设计了并行化的卷积神经网络推断系统。通过运算资源重用、并行处理数据和流水线设计,并利用全连接层的稀疏性设计稀疏矩阵乘法器,大大提高运算速度,减少资源的使用

CNN由由可学习权重和偏置的神经元组成。每个神经元接收多个输入,对它们进行加权求和,将其传递给一个激活函数并用一个输出作为响应。整个网络有一个损失函数,在神经网络开发过程中的技巧和窍门仍然适用于CNN。很简单,对吧?
那么,卷积神经网络与神经网络有什么不同呢?