本文转载自: FPGA打工人微信公众号
注:本文由作者授权转发,如需转载请联系作者本人
接口综合
接口综合有两种,一种是block-level interface protocol和port-level interface protocol。block-level interface protocol只作用于顶层函数或者顶层函数的返回值,port-level interface protocol数量比较多,只作用于顶层函数的参数。
block-level interface protocol只有三种,分别是:ap_ctrl_hs、ap_ctrl_none、ap_ctrl_chain。和ap_ctrl_none相比ap_ctrl_hs作用于函数时,会产生额外几个输入输出。具体如下:
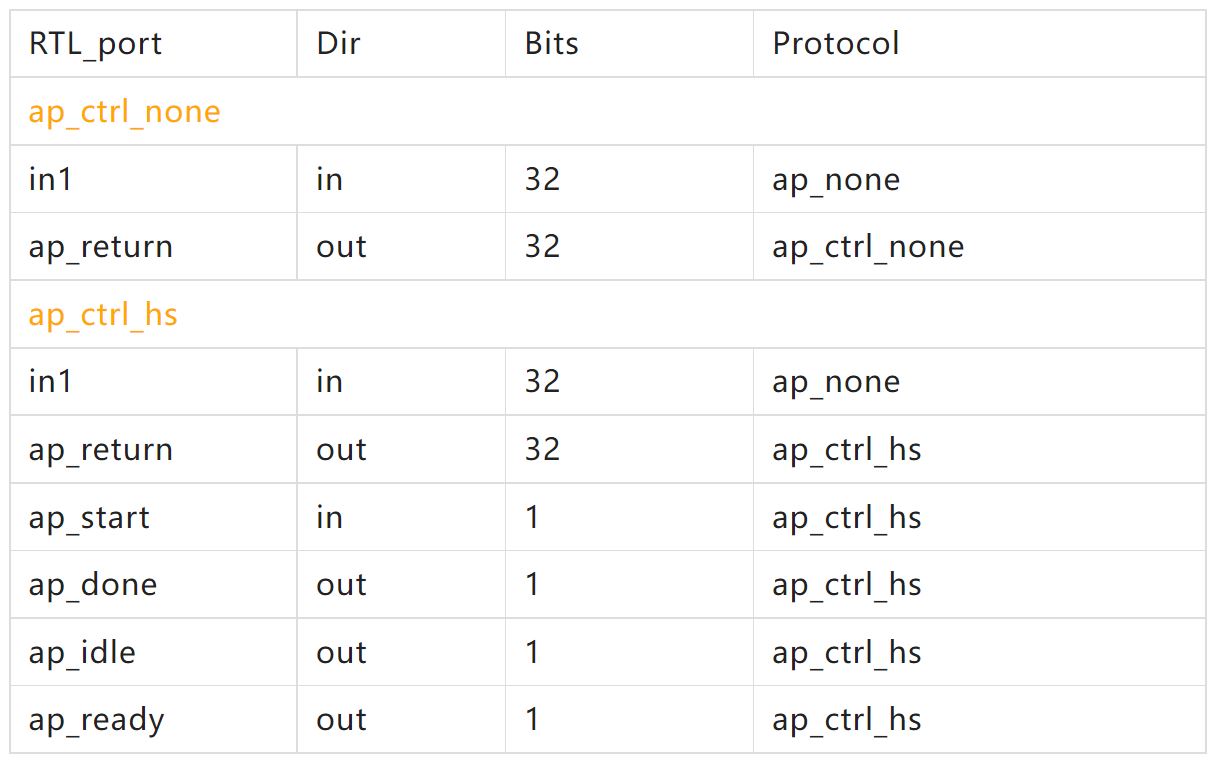
会发现ap_ctrl_hs多出来了ap_start ap_done ap_idle ap_ready这4个信号。ap_start为高表示下一级可以开始处理数据,这时ap_idle就会为低,表明module开始工作,处于busy状态,ap_ready为高,表明该module可以接收新的数据,ap_done为高表明输出结果。
port-level interface protocol默认为ap_none,表示没有接口协议,还有ap_stable、ap_ovld、ap_vld、ap_hs等。
常用的interface protocol如下:
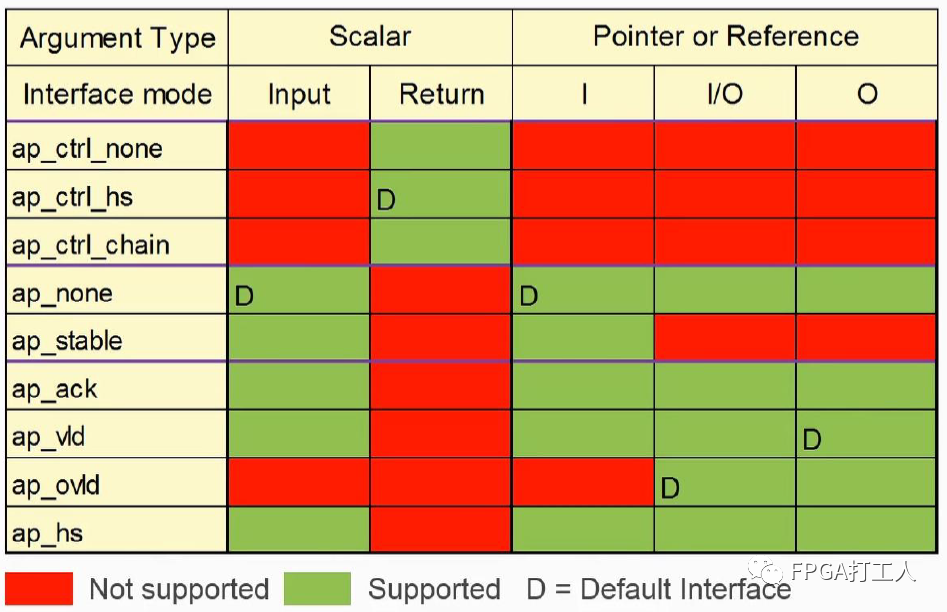
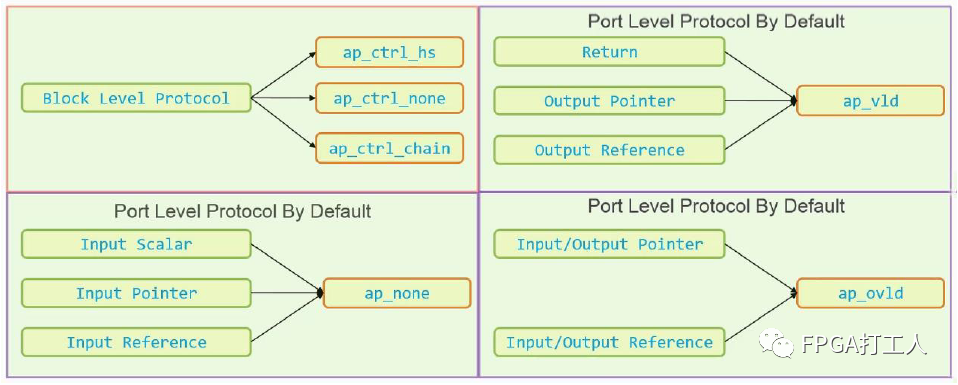
有时接口函数的参数也会出现数组。正常会映射为常用的memory接口,比如读写使能,读写地址等常用的控制信号和数据信号。正常HLS会自动分析映射为合适的RAM,但也支持手动设置。
typedef ap_int<8> data_t ;
typedef ap_int<17> out_t ;
out_t data_test(data_t data0, data_t data1, data_t data2 )
{
return (data0 * data1 + data2);
}
上面的code可以做个简单实验,在Directive界面右击data_test会出现Insert Directive,进入后在Directive选择INTERFACE,下面的mode选择接口综合mode,有时可能为了解决时序收敛问题,需要添加寄存器,直接勾选register即可。
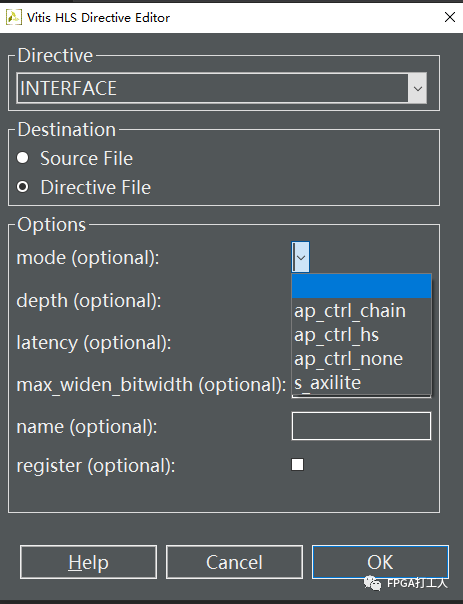
还有就是添加时钟使能信号,具体操作是右击solution,选择solution settings,在General界面找到config_interface,其子栏中勾选clock_enable即可。

for循环优化
HLS算法实现中,for循环应该是经常使用,所以for循环的优化也是重中之重。
for循环pipeline
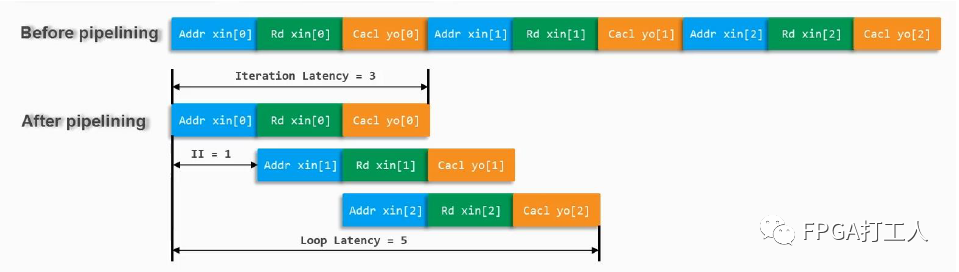
pipeline优化最大的优势是可以改善latency和interval。在没有设置pipeline时,整个for循环的操作是按时间的先后顺序执行的,设置之后,有种流水线操作的方式,虽然执行一次for循环的时间没变,但整个for循环执行时间进行了大量缩短。
for循环UNROLL展开
unroll展开可以理解为RTL的面积换时间操作,for循环中使用的电路是同一套,展开后将循环电路复制若干份,具体多少可自己设置。
前面两个都可在Directive中设置。

会发现设置PIPELINE时,有个rewind的设置,正常情况下,在执行完一次for循环后,会有一个时钟周期的空档期,才会执行下一次循环,该设置是为了让两次for循环之间没有空挡,尽可能降低整个的latency。
在设置UNROLL界面中的factor就是将for循环中的电路复制多少份。
for循环-循环合并
循环合并我个人觉得,这个功能应该不如前两个,循环合并毕竟有时可以直接在设计code时解决,但HLS还是提供了选择,可以简单熟悉熟悉。比如下面的code:
add:
for(i=0; i
c[i] = a[i] + b[i] ;
}
sub:
for(i=0; i
d[i] = a[i] - b[i] ;
}
会发现两个for循环都是对a、b两个数组进行计算,可以通过LOOP_MERGE指定合并优化。
要注意几点:
若循环边界不同但都为常量,合并之后选择更大的作为新的循环边界;
若其中一个循环边界为变量,不支持合并。
for循环-数据流
主要就是DARAFLOW优化指令。比如下面的code:
loop_A:
for(i=0; i
x[i] = a[i] + 4 ;
}
loop_B:
for(i=0; i
y[i] = x[i] * b[i] ;
}
loop_C:
for(i=0; i
c[i] = y[i] - 5 ;
}
若把每个for循环当作一个整体,会发现三个for循环之间有种数据流的状态。这种就可以用到DATAFLOW优化。在没有使用DATAFLOW时,三个循环会顺序执行,设置DATAFLOW后,多个for循环之间就可以有交叠,降低了latency。

但是,DATAFLOW不是所有code形式都是支持的,有局限性。

具体详细的区分可参考下面的文章:
剩余的优化应该就是从code层面进行优化了。