作者:姚颂 文章转载自:XILINX技术社区
云计算已经成为了一种新的计算范式。对于云计算而言,虚拟化是一项必不可少的技术,通过将硬件资源虚拟化,我们可以实现用户之间的隔离、系统的灵活可扩展,提升安全性,使得硬件资源可被充分利用。
从2018年起,因为FPGA的高可编程性、低延迟、高能效等特点,越来越多的云服务提供商,如Amazon、阿里云、微软Azure,都开始在云端提供了Xilinx FPGA实例,迈入了云计算发展的重要一步。但到目前为止,FPGA云服务都还是以物理卡的形式、面向于单一的静态任务,还没有很好的针对于云端FPGA虚拟化的解决方案。

为了解决这一问题,清华大学汪玉教授研究小组提出了针对深度学习加速的FPGA虚拟化方案,通过多核硬件资源池、基于分块 (tilling) 的指令封装、两级静态与动态编译的方式,来实现任务间的分离,同时保证快速的在线重编程;深度学习加速器的基础设计则基于汪玉教授小组2017年的Angel-Eye工作。相关论文也将在5月初举办的FPGA领域顶级会议FCCM2020进行在线报告。
如果想亲手测试的小伙伴,也可以根据github中的说明,连接服务器进行体验: https://github.com/annoysss123/FPGA-Virt-Exp-on-Aliyun-f3
总体介绍
如图1 (a) 所示,云端的FPGA一般为VU9P等资源比较多的FPGA芯片,可以同时支持多路的计算,因而是可以虚拟化的。公有云的虚拟化一般采用物理资源隔离,或者性能隔离的方式给不同用户分配计算资源,前者给不同用户分配完全不同的计算资源,后者使用动态重配置等方式使得多用户与多任务的情况下总体性能最大化。本项研究中,作为对照的基本设计,是在FPGA上部署一个大核,以时分复用 (TDM) 的方式让多个用户使用;而虚拟化设计则是选择空分复用 (SDM) 的方式来共享同一块FPGA的计算资源。
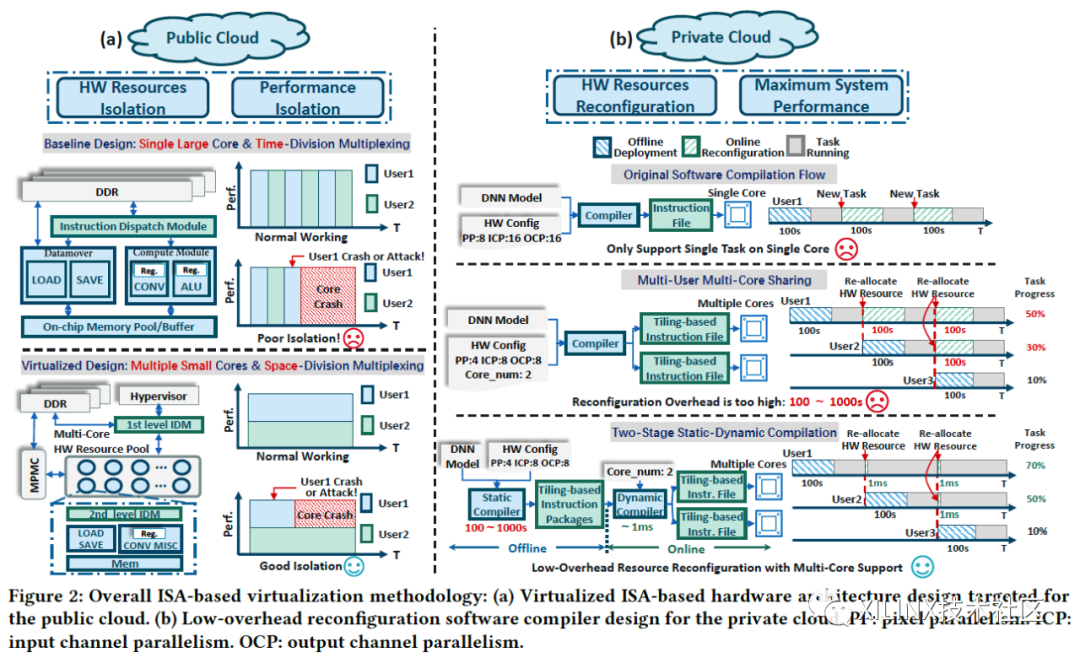
图1:基于指令集的虚拟化方法:(a) 针对公有云的硬件架构;(b) 针对私有云的编译器设计
而如图1 (b) 所示,在私有云的情况下,我们希望使得系统总的性能最优。如果FPGA允许多个用户使用,在新的用户申请资源后,系统需要给新用户分配硬件资源——如果需要重新烧写FPGA,或者重新编译生成指令,则切换的时间成本很高。为了让云端的虚拟化FPGA,可以更加灵活快速的支持动态的深度学习推理应用,本项虚拟化设计的编译器上分为了静态与动态的两个阶段:首先在离线部署阶段,先生成一些列指令的打包 (instruction frame package, IFP) ; 在运行时,则根据不同用户硬件资源分配的需求,给不同的核分配IFP,来实现快速的在线重配置。在这种情况下,在线编译器只需要处理较少的运行时信息,可以将重配置的时间降低到1ms左右。

图2. 基于FPGA的虚拟化深度学习加速器硬件架构
硬件与编译器设计
为了实现虚拟化方案,如图2所示,在硬件方面也需要和传统的深度学习加速器有很大的不同。为了能够实现FPGA的空分复用,该设计采用了多核资源池的设计,每个用户会被分配并且独占一定数量的小计算核。传统的指令分发模块 (IDM) 只是用来实现单核的指令分发与依赖性管理,为了能支持虚拟化,需要将IDM分为两级:
第一级IDM包括Instr Mem, Instr Decoder,Content-Switch Controller, 以及Multi-Core Sync. Controller四个模块。Instr Mem从DDR中取指并且缓存在片上,Instr decoder将指令分发到各个第二级IDM。Content-Switch Controller可以记录当前神经网络运行到哪一层,可以在任务切换时让计算核直接在已有的中间结果上运算。而Multi-Core Sync. Controller则是产生同步信号,让同一个用户分配的多个核的计算同步。
第二级IDM则负责每个核内的计算调度,Context-SwitchController模块根据上下文信息控制计算的重新开始,System Sync. Controller则在多核的计算同一个神经网络时,获取全局同步信号,用来控制该计算核与其他核的计算是同步的。

图3. 基于FPGA的虚拟化深度学习加速任务编译流程,左为静态编译,右为动态编译
为了让同一个神经网络可以动态分配到不同计算核上计算,需要将总的计算任务切成块(Tilling),这也是神经网络加速器设计中的一个重要思路。我们可以从多个不同维度去对神经网络进行切块,比如feature map的height维度,但是这会让指令之间的依赖性更加复杂,因此,本项研究中选择了feature map的width和outputchannel两个维度去进行切块。
如图3所示,左侧就展示了,我们对于一个神经网络的第i层,在height和outputchannel两个维度进行切块,每一块的一系列指令封装成一个IFP;经过一个简单的latency simulator,可以得到每一块的指令总执行时间T_1到T_N (或T_M) 。Allocator模块则会根据不同切块的计算延时,将计算任务均匀地分配到当前用户所有的多个计算核上,实现负载均衡,从而使得总体延迟最短。
实验结果
为了衡量本虚拟化方案的效果,研究小组分别使用了Xilinx Alveo U200板卡、Xilinx VU9P FPGA (阿里云上实例)、以及nVidia TeslaV100 GPU运行Inception v3, VGG16, MobileNet, ResNet50等四种不同的神经网络作为测试。硬件资源使用情况如Table 1所示。
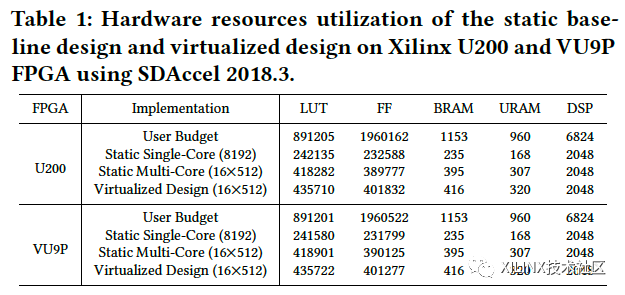
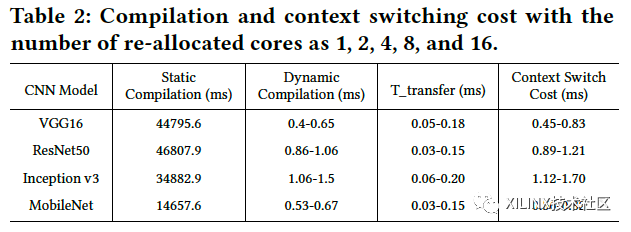
首先,我们需要衡量虚拟化方案带来的额外编译与任务切换的成本。如Table2所示,可以看到,静态编译大约耗费14.7-46.8秒,而运行时的动态编译大约耗时0.4-1.5ms。再加上下发指令文件到计算核并开始计算的时间,总体的动态重构成本在0.45-1.70ms,相对于静态编译可以忽略不计,实时的切换成本很低。
一个好的虚拟化方案,应该让用户获得的性能和计算资源的多少成线性。一方面,我们希望不同用户在分配到了同样的计算资源,可以获得同样的计算性能。另一方面,我们希望同样的用户,在获得更多的计算资源时,获得的性能能够随着计算资源数量线性增长。
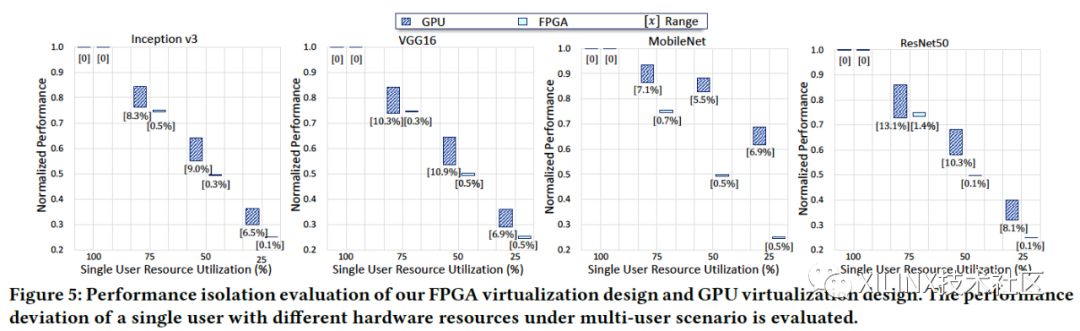
图4.FPGA平台与GPU平台在不同神经网络下性能隔离与理想情况的偏离
假设有4个用户,每个用户在获得25%,50%, 75%, 或者100%的计算资源情况下,我们希望性能与获得资源的是成比例的。图4展示了不同计算资源情况下,每个用户获得的计算性能相对于线性关系的偏离,如对于ResNet50,在分配50%计算资源的情况下,4个用户在采用GPU虚拟化方案实际性能有10.3%的差异,而FPGA方案则只有0.1%的性能差异。可以看到,FPGA虚拟化方案的性能隔离明显更好,同样计算资源可以获得一致的计算性能。
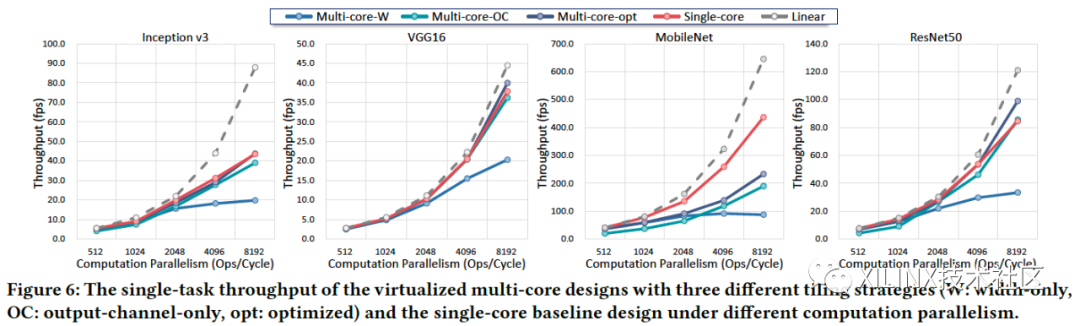
图5. 在不同tilling策略下,计算性能随着并行度的增长情况
由于FPGA虚拟化方案是由多个小核实现的,我们也会关心性能是否随着分配的计算核的数量可以线性增长。图5展示了使用FPGA虚拟化方案,在不同神经网络、在不同tilling策略下,随着计算核数量增加的计算性能提升情况。红线表示,如果直接使用一个大核,可以取得的性能,而“Multi-core-opt”表示从width和output channel两个维度根据延迟进行优化选择的策略。对于Inception v3和VGG16网络,多核的性能损失相对于单个大核只有 0.95%和3.93%;而对于MobileNet,多核性能则与单个大核性能有了31.64%的损失,主要原因是对于MobileNet,存储带宽影响更大,多核还是增加了带宽需求。我们也可以发现在如VGG16这样可并行程度较高的神经网络上,该方案取得了良好的线性度。而对于Inceptionv3以及MobileNet这样瓶颈主要在存储带宽的情况,哪怕是单个大核的情况,相对于纯线性增加,性能还是会有一定的损失,原因也是存储带宽的限制。
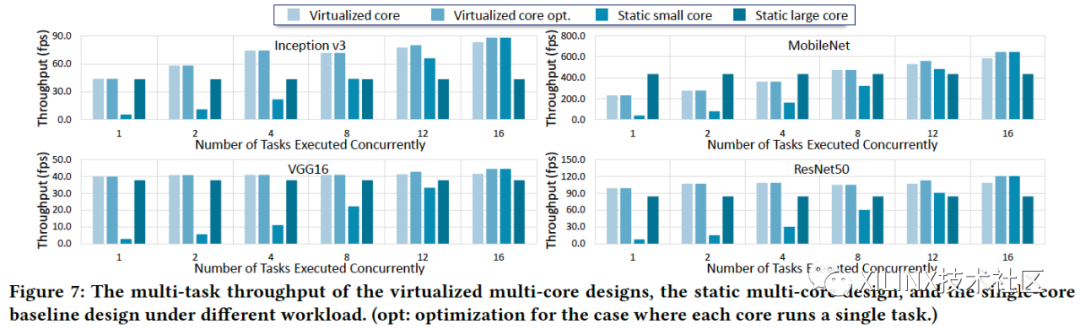
图6. 不同方案在多任务情况下的总吞吐量
最后,研究也测试了多用户、多任务的情况,性能以整个芯片总的throughput来衡量。如图6所示,从浅到深的柱状图分别代表虚拟化方案、计算核为单独任务优化的虚拟化方案、每个任务单独一个计算核、整芯片部署一个大核四种情况,在同时支持不同数量任务下的总性能。FPGA上共部署了16个计算核、因而可以支持最多16个任务同时运行。可以看到,在任务不多的时候 (1,2,4个) ,每个任务单独一个计算核没办法充分利用总的计算资源,因而总的性能较弱,而虚拟化方案可以实现好得多的性能,在任务数多起来以后,单个大核因为同时只能运行一个任务,总的性能得不到提升。而两种虚拟化方案,随着总任务数的提升,性能在稳步提升,在同时运行16个任务时,性能与每个core支持一个任务相同,都达到芯片的最大吞吐。
可以看到,该项研究提出的虚拟化方案,在性能隔离、性能scalability、多任务扩展等情况都有不错的表现,任务切换成本只有大约1ms的情况,单任务的性能损失在1%-4%左右,多任务的情况相对于静态的单核方案与静态的多核方案,分别可以实现1.07-1.69倍与1.88-3.12倍的性能提升。该篇论文也已经刊登在在arxiv平台:https://arxiv.org/abs/2003.12101,欢迎感兴趣的读者点击下载。
在未来,Xilinx技术社区也将带来更多最新的FPGA领域的研究进展。





