作者:Ing.Giulio Corradi 博士,AMD 工业、视觉、医疗和科学首席架构师
从历史上看,在全面生产环境中,企业最宝贵的资产之一就是机器操作人员的经验,因为他们能预测出何时需要进行维护。工厂经理会报告任何异常行为,例如机器内的叮当声或咔嗒声,催促维护人员开展检查。如今,自动化水平的提升严重削弱了操作员觉察即将发生的故障的能力,并且大部分维护工作都是按计划进行,而非预测性维护,如果某些情况下未被发现或被忽视,则会引起不必要的工厂停运。
然而,近来席卷全球的新冠疫情迫使更多机器采用无人值守或远程值守的方式运行,现场运行被降至最低水平,维护团队规模被压缩。因此对工厂经理而言,为轻松预测故障而提高机器设备的自动检测、自我诊断能力成为眼下的战略优势。
故障预测与健康管理(PHM)等方法与预测性维护4.0(PdM4.0)等计划已经问世数年,但现在才从工厂经理的观察名单转为当务之急。目标是为自动运行和远程值守机器设备提供人工在环决策,进行最佳且及时的维护操作。
PHM 旨在采集和分析数据,通过算法检测异常和诊断即将发生的故障,以提供设备的实时健康状态,进而估算其剩余使用寿命(RUL)。相关的财务效益包括延长设备使用寿命,以及降低运营成本。
PdM4.0 是工业 4.0 和工业物联网(IIoT)计划的组成部分,其目的是进一步提高设备自动化水平,为设备配备更多的数据采集传感器,使用数字信号处理、机器学习和深度学习作为预测故障的工具并触发维护活动。
各项标准与配套的词汇、演示和指南已制定完成,如 IEEE 1451、1232,ISO 体系的 13372、13373、13374、13380、13381。它们为维护 4.0 奠定了共同的基础。
图 1提供了从计划维护向 PdM4.0 转型的路径。显然,随着向 PdM4.0 的转型不断深入,复杂性也随之增加。
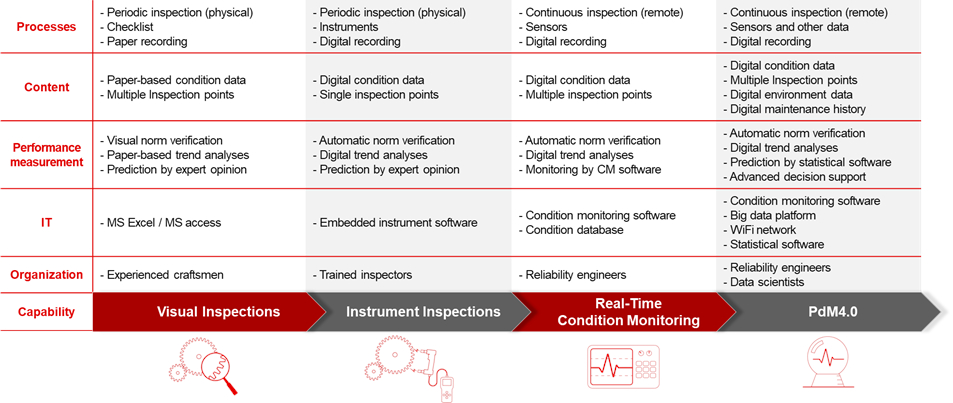
图1:以 PdM4.0 为最高限的预测性维护水平,来源:普华永道
挑战
然而,虽然 PHM 和 PdM4.0 的意图清晰并提供了一般性建议,但它们的实际实施并未完全实现,这是因为工厂经理或维护经理尚不具备所需的技能组合。要充分发挥 PHM 和 PdM4.0 的优势,必须思考以下问题:
大多数时候没有明确的答案。最原始的简单想法是采集工厂和机器设备产生的所有数据,将这些数据传递到云端的本地数据中心,并尝试使用数据分析从中提炼信息。这也被视为批处理数据。

图 2:从现场到云端的预测性维护流程数据
图 2所示的是通向云的数据漏斗以及有助于形成预测性维护的不同数据源。
并非所有的工厂和机器设备数据都相同。还有一些非结构化数据,如检查报告、维护日志、原材料和批次组织,这些数据与用于预测性维护的数据相关联。此外也有来自 ERM、EAM 和 MES 等企业自动化技术的结构化数据,它们提供了另一个信息来源,用于检验机器设备状况、工作量和使用情况。这也称为批处理数据。
大多数非结构化信息来自与边缘设备相连的传感器,因为数据流经常以毫秒为周期大量产生。
PdM4.0 推荐的分析框架如图 3 所示。

图 3:为 PdM4.0 提取数据的分析框架
基线分析功能可在实际事件发生后的几毫秒内检测到资产的异常行为。用于执行这些分析的数据通常属于相关资产的本地数据,并且依赖于资产正常工作时采集的数据。
诊断分析功能用于确定异常的根源,例如电机轴承失效,这需要具备故障状态的相关知识。诊断结果可以在几分钟内返回。
告知轴承剩余使用寿命的预后分析可能需要数小时才能返回结果,并且需要访问来自多个来源的多种类型的数据,才能做出预测。
实现架构
结构化数据和非结构化数据、批处理和流处理数据、速度和容量,这些都是工业 4.0 计划的宏大分析架构的组成部分,而预测性维护则搭载在此类框架上。两种主要架构正在兴起:
Lambda 架构
Lambda 架构是一种用于数据处理的部署模型,将传统的批处理管道与高速实时的流管道相结合,在面对快速产生的海量数据时,可提供数据驱动和事件驱动的数据访问。

图 4:Lambda 架构
图 4 所示的是 Lambda 架构。
Apache Kafka 是一种用于实现数据源(Data Source)的框架。它是一种分布式数据存储,针对实时、顺序和增量摄取以及处理流数据进行了优化。它充当中间存储,可以保存数据并为 Lambda 架构的批处理层和速度层提供支持。
批处理层(Batch Layer)通常使用诸如 Apache Hadoop 之类的技术来实现,以便能经济高效地获取和存储数据。为了确保所有传入数据的可信历史记录,这些数据被视为不可变且仅允许追加。
服务层(Serving Layer)会对最新的批量视图进行增量索引,以允许最终用户进行查询。处理过程以一种极度并行化的方式完成,以最大限度缩短对数据集的索引时间。
速度层(Speed Layer)通过索引最新添加的、尚未被服务层完全索引的数据来补充服务层。通常来讲,最靠近现场流数据的现场网关起着速度层的作用。它们摄取消息、过滤数据、提供身份映射、日志消息并提供到云端或本地网关的链接。如果这些网关也能执行本地分析和机器学习,那么向上游移动数据就没有优势,而且在确定现场网关平台的大小时,此功能需要考虑 CPU 和存储器大小的影响。
查询层(Query Layer)是数据科学家、工厂专家和管理人员查询所有数据(包括最近添加的数据)所需的,以提供近乎实时的分析系统。
Kappa 架构
许多机构可能同时拥有批处理、实时以及非常严格的端到端时延需求,要求可以在数据流层中采用包括数据质量技术在内的复杂转换。因此,Kappa 架构是一种流优先的架构部署模式。 Apache Kafka 的功能是摄取数据,并将数据传递到 Apache Spark、Apache Flink 等流处理引擎中进行转换,然后将富化后的数据发布回服务层,以实现报告和仪表板功能。
PdM4.0 边缘设备的硬件要求
要部署 Lambda 或 Kappa 架构,属于嵌入式系统的设备和边缘网关需要足够的算力性能和足够的内存。以 Apache Kafka 为示例进行重点讲解:Apache Kafka 可以部署到这样的嵌入式系统中,为 Lambda 和 Kappa 架构提供支持。Apache Kafka 可以采用不同的配置进行部署,包括裸机、虚拟机(VM)、容器等。以最低配置运行 Apache Kafka 的最低硬件要求是单核处理器和几个100MB 的 RAM。然而,这种小规模的实现方案不足以为 Lambda 和 Kappa 架构提供适当的服务质量。
具体而言,在 Apache Kafka 的系统概念中,消息流被划分成名为“话题”(topic)的特定类别。这些消息使用名为“生产方”(producer)的专用进程发布给特定话题。发布后的消息随后被存储在名为“中间代理”(broker)的服务器集群中。从根本上说,Kafka“中间代理”期望客户端“生产方”(现场设备)发送消息给系统,客户端消费者(边缘设备)拉出消息,管理客户端工具(在现场设备和边缘设备内)允许创建话题、删除话题,并配置安全设置。仅从这些对“中间代理”、“生产方”、“消费方者”和“管理工具”的基本要求,就可以洞悉需求的多样性。对于“生产方”,如果我们增加互联功能和数据采集功能,那么,算力性能和存储器占用就会成为嵌入式系统的严重问题。因此,要让这样的嵌入式计算系统提供合理水平的服务质量,应具备下列特性:
您可以在片上系统(SoC)、CPU 或 GPU 中找到一些上述功能,但某些器件 I/O 能力不足,某些器件的机器学习和数字信号处理能力有限,还有些器件不具备足够的互联能力。综合所有这些技术,另一种技术类别正异军突起。自适应计算加速平台(ACAP)集成了上述所有功能,包括面向机器学习和深度学习推断的矢量处理、面向运行相关框架的标量 CPU、面向实时数据采集和 I/O 密集型处理的紧密耦合可编程逻辑(PL)。这些功能结合高带宽片上网络(NoC),能提供对全部三种处理元素类型的存储器映射访问和对采集和处理数据的存储器访问。
ACAP 随后提供了实现基线所需的资源和靠近数据源的诊断分析功能,并能够集成 Apache Kafka 和其他集群系统等流处理框架。

图 5:ACAP 架构
结论
预测性维护是一项颇具挑战性的工作。我们在上文中介绍了如何让数据和分析要求与可用功能合理衔接。因篇幅有限,本文未能穷尽该架构的全部详情,但通过介绍 Lambda 和 Kappa 架构,揭示一条让速度层组件与批处理层组件协调运行的实现路径。为满足边缘端所需的算力,可充分发挥赛灵思 ACAP 等新型自适应计算器件的效力来管理这样的海量数据,在边缘嵌入式系统层面提供必需的服务质量。