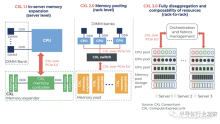
目前市场上关于数据中心、高性能计算领域、AI领域等场景的全新数据设备互联协议竞争标准,主要包含CXL,OpenCAPI、GEN-Z、CCIX、NVLink等,从各个标准联盟成立的时间线为CAPI->GenZ->CCIX->CXL。
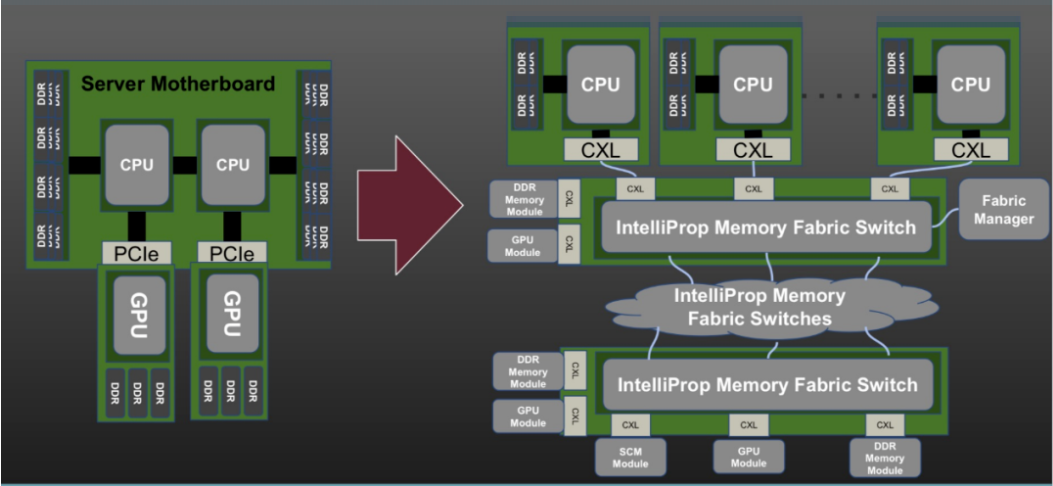
最近,OpenCAPI 和 CXL 将发布联合公告,表示这两个集团将联手,OpenCAPI 标准和财团的资产将转移到 CXL 财团。通过这种集成,CXL 将成为主导的 CPU 到设备互连标准,因为几乎所有主要制造商现在都支持该标准,而竞争标准已经退出竞争并被 CXL 吸收。
一、设备互联协议的背景
众所周知,在开放平台下,PCIE是目前高性能I/O设备普遍采用的总线类型,目前已经到Gen4,很快会到Gen5。但是PCIE总线的树形拓扑以及有限的设备标识ID号码范围,导致其无法形成一个大规模网络,这个问题在NVMe盘未普及之前显得不那么是个问题,但是NVMe盘得到广泛应用之后,会占用大量的PCIE同道数量,这使得原本捉襟见肘的PCIE总线资源更加紧张,GPU、NIC、FPGA/ASIC卡的接入数量就会被NVMe盘挤占,虽然可以用PCIE Switch来解决同道数量不够的问题,但是对于PCIE总线设备ID号的不足,PCIE Switch也并没有方便的解决方案,虽然可以用NTB方式来解决,但是这又需要在Host端OS内核底层增加一层驱动,这种对内核的变更使得该方案只适合用在封闭系统里,比如一些企业级存储系统。
PCIE的另外2个问题是,存储器地址空间隔离、不支持Cache Coherency事务。PCIE网络中的地址空间虽然也是64bit,但是其原本设计初衷是该网络的地址空间是私有的,与CPU的地址空间并不是原生融合的,需要地址翻译寄存器来做基地址翻译,然而对于Intel平台,这个翻译靠软件来执行,而且规则也很简单,就是不翻译,维持原有地址。
这样的话,虽然CPU可以直接访问PCIE网络中的地址,而PCIE设备也可以访问CPU地址空间中的地址(比如Host RAM),但是由于PCIE事务层不支持Cache Cohernecy事务的处理,所以PCIE设备端无法缓存CPU地址域中的数据,所以每次都必须去访问Host RAM来获取数据。
设备端无法缓存的话,每次都访问Host RAM有什么问题么?问题就是延迟太高,通过DDR同道直接访问内存延迟在40ns左右,而通过PCIE访问则会在100ns级别,如果是小尺寸访存请求,性能将会比较差。正因如此,对于目前的GPU、FPGA/ASIC等加速卡,普遍采用先将数据从Host RAM拷贝到加速卡上的内部存储器,计算,算完了再拷贝回Host RAM。
很显然,只要两招就能解决上述问题,第一就是将总线速率提升,降低访问延迟,第二就是在物理链路之上增加对Cache Cohernecy(下简称CC)事务的处理,也就是在设备一侧增加一个CC Agent与CPU一侧的Agent交互。
基于以上原因,各大公司开始分别组建了几个互联协议联盟。
二、主要设备互联协议介绍
1. CXL
成立时间:2019年,牵头方:英特尔
英特尔牵头成立了名为CXL(Compute Express Link)标准组织,以实现CPU与诸如GPU、FPGA等专用加速芯片间的快速互联,推动下一代数据中心的性能。
与CXL相似的标准组织有CCIX、OpenCAPI、Gen-Z Consortium(Gen-Z),这些标准组织也早在2016年已相继成立,其中CCIX与CXL同为以PCIe标准为底层连接协议。就各协议现有成员来看,包括AMD、IBM、Xilinx、华为均有参与到各协议中。

2. Gen-Z
成立时间:2016年,牵头方:惠普
Gen-Z 其实是一堆行业巨头不满意 Intel 技术垄断和演进的情况下,合作搞出的新型高速互连标准,AMD、ARM、博通、Cray、戴尔 EMC、HPE、华为、IBM、联想、Mellanox (NVIDIA)、美光、红帽、三星、希捷、SK 海力士、西数、赛灵思等等都在其中,CPU,模组,网络,服务器,存储,连接器,操作系统,硬盘,FPGA的龙头老大都已经齐聚一堂,好像也看到无处不在的大陆连接器线缆龙头大哥,立迅精密。
3. OpenCAPI
成立时间:2016年,牵头方:IBM
科技行业巨头IBM、AMD、DELL、EMC、谷歌、惠普企业集团(HPE)、迈络思(Mellanox)、美光(Micron)、英伟达(NVIDIA)和赛灵思( Xilinx)联合成立了OpenCAPI技术联盟,并发布了一个可将数据中心服务器性能提升高达10倍的开放式新规范,助力企业和云数据中心提高大数据、机器学习、分析与其他新兴工作负载的处理能力。
4. CCIX
成立时间:2016年
AMD、ARM、Mellanox、华为、IBM、高通和赛灵思七家公司正式宣布,共同成立CCIX(针对加速器的缓存一致性互联)联盟,致力于统一异构计算加速器标准。CCIX的驱动因素是需要比当前可用技术更快的互连,并且需要缓存一致性,以便在异构多处理器系统中更快地访问内存。因此,该联盟的工作集中在使硬件加速器以缓存一致的方式使用与多个处理器共享的内存。
5. NVLink
英伟达自己的标准,专门与 IBM 的 Power CPU 及其自己的 GPU 加速器进行连接。
6. Infinity Fabric
AMD自己的标准,专门用于将自家的 EPYC处理器和加速器进行连接。
三、总结:
随着 OpenCAPI 兼并到 CXL,这使得英特尔支持的标准成为主导的互连标准——以及行业未来的事实标准。竞争的Gen-Z 标准在今年早些时候同样被 CXL 吸收,而 CCIX 标准已被抛在后面,其主要支持者近年来加入了 CXL 联盟。因此,即使第一批支持 CXL 的 CPU 还没有发货,在这一点上,CXL 已经清除了障碍。
来源:高性能算力网络