随着机器视觉技术的快速发展,传统很多需要人工来手动操作的工作,渐渐地被机器所替代。
传统方法做目标识别大多都是靠人工实现,从形状、颜色、长度、宽度、长宽比来确定被识别的目标是否符合标准,最终定义出一系列的规则来进行目标识别。这样的方法当然在一些简单的案例中已经应用的很好,唯一的缺点是随着被识别物体的变动,所有的规则和算法都要重新设计和开发,即使是同样的产品,不同批次的变化都会造成不能重用的现实。
而随着机器学习,深度学习的发展,很多肉眼很难去直接量化的特征,深度学习可以自动学习这些特征,这就是深度学习带给我们的优点和前所未有的吸引力。
很多特征我们通过传统算法无法量化,或者说很难去做到的,深度学习可以。特别是在图像分类、目标识别这些问题上有显著的提升。
视觉常用的目标识别方法有三种:Blob分析法(BlobAnalysis)、模板匹配法、深度学习法。下面就三种常用的目标识别方法进行对比。
Blob分析法
在计算机视觉中的Blob是指图像中的具有相似颜色、纹理等特征所组成的一块连通区域。Blob分析(BlobAnalysis)是对图像中相同像素的连通域进行分析(该连通域称为Blob)。其过程就是将图像进行二值化,分割得到前景和背景,然后进行连通区域检测,从而得到Blob块的过程。简单来说,blob分析就是在一块“光滑”区域内,将出现“灰度突变”的小区域寻找出来。
举例来说,假如现在有一块刚生产出来的玻璃,表面非常光滑,平整。如果这块玻璃上面没有瑕疵,那么,我们是检测不到“灰度突变”的;相反,如果在玻璃生产线上,由于种种原因,造成了玻璃上面有一个凸起的小泡、有一块黑斑、有一点裂缝,那么,我们就能在这块玻璃上面检测到纹理,经二值化(BinaryThresholding)处理后的图像中色斑可认为是blob。而这些部分,就是生产过程中造成的瑕疵,这个过程,就是Blob分析。
Blob分析工具可以从背景中分离出目标,并可以计算出目标的数量、位置、形状、方向和大小,还可以提供相关斑点间的拓扑结构。在处理过程中不是对单个像素逐一分析,而是对图像的行进行操作。图像的每一行都用游程长度编码(RLE)来表示相邻的目标范围。这种算法与基于像素的算法相比,大大提高了处理的速度。

但另一方面,Blob分析并不适用于以下图像:
1.低对比度图像;
2.必要的图像特征不能用2个灰度级描述;
3.按照模版检测(图形检测需求)。
总的来说,Blob分析就是检测图像的斑点,适用于背景单一,前景缺陷不区分类别,识别精度要求不高的场景。
模板匹配法
模板匹配是一种最原始、最基本的模式识别方法,研究某一特定对象物的图案位于图像的什么地方,进而识别对象物,这就是一个匹配问题。它是图像处理中最基本、最常用的匹配方法。换句话说就是一副已知的需要匹配的小图像,在一副大图像中搜寻目标,已知该图中有要找的目标,且该目标同模板有相同的尺寸、方向和图像元素,通过统计计算图像的均值、梯度、距离、方差等特征可以在图中找到目标,确定其坐标位置。
这就说明,我们要找的模板是图像里标标准准存在的,这里说的标标准准,就是说,一旦图像或者模板发生变化,比如旋转,修改某几个像素,图像翻转等操作之后,我们就无法进行匹配了,这也是这个算法的弊端。
所以这种匹配算法,就是在待检测图像上,从左到右,从上向下对模板图像与小东西的图像进行比对。

这种方法相比Blob分析有较好的检测精度,同时也能区分不同的缺陷类别,这相当于是一种搜索算法,在待检测图像上根据不同roi用指定的匹配方法与模板库中的所有图像进行搜索匹配,要求缺陷的形状、大小、方法都有较高的一致性,因此想要获得可用的检测精度需要构建较完善的模板库。
深度学习法
2014年R-CNN的提出,使得基于CNN的目标检测算法逐渐成为主流。深度学习的应用,使检测精度和检测速度都获得了改善。
卷积神经网络不仅能够提取更高层、表达能力更好的特征,还能在同一个模型中完成对于特征的提取、选择和分类。
在这方面,主要有两类主流的算法:
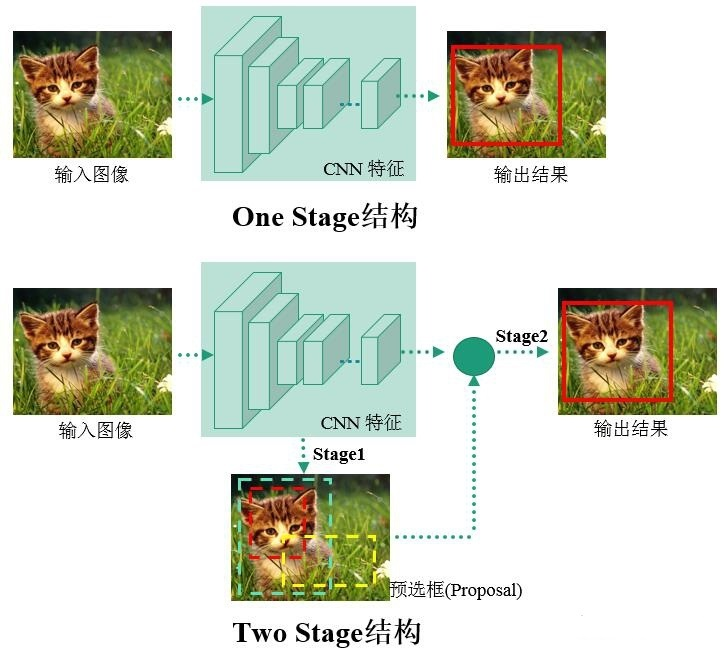
一类是结合RPN网络的,基于分类的R-CNN系列两阶目标检测算法(twostage);
另一类则是将目标检测转换为回归问题的一阶目标检测算法(singlestage)。
物体检测的任务是找出图像或视频中的感兴趣物体,同时检测出它们的位置和大小,是机器视觉领域的核心问题之一。

物体检测过程中有很多不确定因素,如图像中物体数量不确定,物体有不同的外观、形状、姿态,加之物体成像时会有光照、遮挡等因素的干扰,导致检测算法有一定的难度。
进入深度学习时代以来,物体检测发展主要集中在两个方向:twostage算法如R-CNN系列和onestage算法如YOLO、SSD等。两者的主要区别在于twostage算法需要先生成proposal(一个有可能包含待检物体的预选框),然后进行细粒度的物体检测。而onestage算法会直接在网络中提取特征来预测物体分类和位置。
两阶算法中区域提取算法核心是卷积神经网络CNN,先利用CNN骨干提取特征,然后找出候选区域,最后滑动窗口确定目标类别与位置。
R-CNN首先通过SS算法提取2k个左右的感兴趣区域,再对感兴趣区域进行特征提取。存在缺陷:感兴趣区域彼此之间权值无法共享,存在重复计算,中间数据需单独保存占用资源,对输入图片强制缩放影响检测准确度。
SPP-NET在最后一个卷积层和第一个全连接层之间做些处理,保证输入全连接层的尺寸一致即可解决输入图像尺寸受限的问题。SPP-NET候选区域包含整张图像,只需通过一次卷积网络即可得到整张图像和所有候选区域的特征。
FastR-CNN借鉴SPP-NET的特征金字塔,提出ROIPooling把各种尺寸的候选区域特征图映射成统一尺度的特征向量,首先,将不同大小的候选区域都切分成M×N块,再对每块都进行maxpooling得到1个值。这样,所有候选区域特征图就都统一成M×N维的特征向量了。但是,利用SS算法产生候选框对时间消耗非常大。
FasterR-CNN是先用CNN骨干网提取图像特征,由RPN网络和后续的检测器共享,特征图进入RPN网络后,对每个特征点预设9个不同尺度和形状的锚盒,计算锚盒和真实目标框的交并比和偏移量,判断该位置是否存在目标,将预定义的锚盒分为前景或背景,再根据偏差损失训练RPN网络,进行位置回归,修正ROI的位置,最后将修正的ROI传入后续网络。但是,在检测过程中,RPN网络需要对目标进行一次回归筛选以区分前景和背景目标,后续检测网络对RPN输出的ROI再一次进行细分类和位置回归,两次计算导致模型参数量大。
MaskR-CNN在FasterR-CNN中加了并行的mask分支,对每个ROI生成一个像素级别的二进制掩码。在FasterR-CNN中,采用ROIPooling产生统一尺度的特征图,这样再映射回原图时就会产生错位,使像素之间不能精准对齐。这对目标检测产生的影响相对较小,但对于像素级的分割任务,误差就不容忽视了。MaskR-CNN中用双线性插值解决像素点不能精准对齐的问题。但是,由于继承两阶段算法,实时性仍不理想。
一阶算法在整个卷积网络中进行特征提取、目标分类和位置回归,通过一次反向计算得到目标位置和类别,在识别精度稍弱于两阶段目标检测算法的前提下,速度有了极大的提升。
YOLOv1把输入图像统一缩放到448×448×3,再划分为7×7个网格,每格负责预测两个边界框bbox的位置和置信度。这两个b-box对应同一个类别,一个预测大目标,一个预测小目标。bbox的位置不需要初始化,而是由YOLO模型在权重初始化后计算出来的,模型在训练时随着网络权重的更新,调整b-box的预测位置。但是,该算法对小目标检测不佳,每个网格只能预测一个类别。
YOLOv2把原始图像划分为13×13个网格,通过聚类分析,确定每个网格设置5个锚盒,每个锚盒预测1个类别,通过预测锚盒和网格之间的偏移量进行目标位置回归。
SSD保留了网格划分方法,但从基础网络的不同卷积层提取特征。随着卷积层数的递增,锚盒尺寸设置由小到大,以此提升SSD对多尺度目标的检测精度。
YOLOv3通过聚类分析,每个网格预设3个锚盒,只用darknet前52层,并大量使用残差层。使用降采样降低池化对梯度下降的负面效果。YOLOv3通过上采样提取深层特征,使其与将要融合的浅层特征维度相同,但通道数不同,在通道维度上进行拼接实现特征融合,融合了13×13×255、26×26×255和52×52×255共3个尺度的特征图,对应的检测头也都采用全卷积结构。
YOLOv4在原有YOLO目标检测架构的基础上,采用了近些年CNN领域中最优秀的优化策略,从数据处理、主干网络、网络训练、激活函数、损失函数等各个方面都进行了不同程度的优化。时至今日,已经有很多精度比较高的目标检测算法提出,包括最近视觉领域的transformer研究也一直在提高目标检测算法的精度。
总结来看,表示的选择会对机器学习算法的性能产生巨大的影响,监督学习训练的前馈网络可视为表示学习的一种形式。依此来看传统的算法如Blob分析和模板匹配都是手工设计其特征表示,而神经网络则是通过算法自动学习目标的合适特征表示,相比手工特征设计来说其更高效快捷,也无需太多的专业的特征设计知识,因此其能够识别不同场景中形状、大小、纹理等不一的目标,随着数据集的增大,检测的精度也会进一步提高。
来源:机器视觉沙龙
免责声明:本文转载于网络,转载此文目的在于传播相关技术知识,版权归原作者所有,如涉及侵权,请联系小编删除(联系邮箱:service@eetrend.com )。





