来源:内容由半导体行业观察(ID:icbank)编译自pcwatch,谢谢。
这是一个有点老的故事了,但去年(2023年)11月14日,CXL联盟发布了“CXL 3.1规范”。
首先,CXL 1.0 于 2019 年 3 月发布,此后大约每年都会发布新版本,从 1.1 → 2.0 → 3.0 → 3.1,但 CXL 2.0 → 3.0 的方向,我感觉这在 3.1 中加速了(图 1)。

在我看来,我们正在朝着一个可以称为“CXL Gen-Z”的方向前进。
CXL推出回顾
CXL(Computer Express Link)是英特尔内部开发的专有链接标准,最初名为 IAL(Intel Accelerator Link),但后来更名为并向公众发布。发布时,英特尔成立了 CXL 联盟,将所有 IAL 协议捐赠给 CXL 联盟,并宣布 CXL 将是开放运营。
其实这段时间CXL联盟发生了很多事情。首先,2022 年 2 月,Gen-Z 联盟实际上并入了 CXL 联盟。然后,2022 年 8 月,OpenCAPI 并入 CXL 联盟。OpenCAPI 合并宣布的第二天,CXL 3.0 的规范就公布了。在这一系列事件中,CXL的目的似乎已经明显发生了变化。
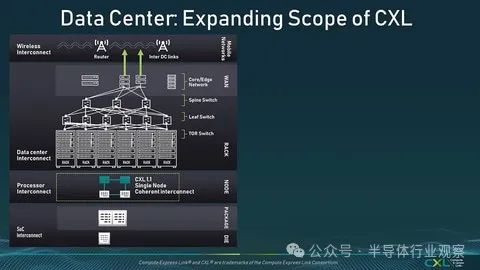
我认为如果您想象在节点之间构建内存/存储池网络并将计算集群连接到此,则更容易理解 Gen-Z。
这已经是一个老故事了,但在 2013 年左右,英特尔提出了一种称为“机架规模架构”的概念(图 2)。Gen-Z的目标是通过根据需求动态分配或指派,将“未来”中出现的计算/内存/存储/IO的使用付诸实践。

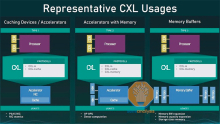
Gen-Z 并入 CXL 后发生了什么?图 3 是第一个 CLX 1.0/1.1 的图像。加速器和存储/内存设备连接到一个计算节点,并且可以使用缓存一致性进行连接。嗯,这正是Intel在制定IAL时所设想的用法。CXL 2.0 中定义的下一个产品是 CXL 2.0 交换机(图 4)。该 CXL 2.0 交换机是:
1. 连接多个计算节点和多个加速器/内存/存储 1:1
2. 在多个计算节点之间共享连接到 CXL 2.0 交换机的加速器/内存/存储资源
现在两者皆有可能。

但CXL 2.0交换机之间并不相互配合;计算节点侧是主机,CXL 2.0交换机接收来自多个主机的请求并分配连接的CXL设备(从而将请求分配给特定主机)。交换机分配资源还是共享资源首先取决于CXL设备是否配置为共享资源,因此不能由CXL 2.0交换机单独决定。
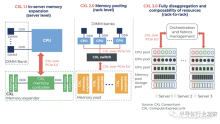
那么 CXL 3.0/3.1 又如何呢?它已经有了进一步的发展(图 5)。现在可以将 CXL 交换机相互链接,从而可以跨多个交换机使用它。
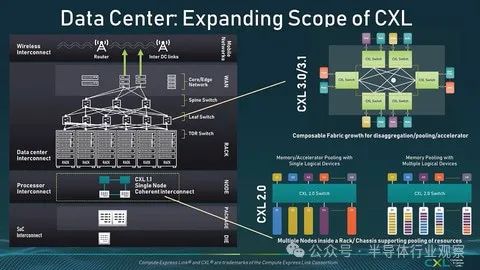
这使得可以在交换机之外使用未直接连接到主机的 CXL 设备。CXL 1.1支持按节点连接,CXL 2.0支持按机架连接,但CXL 3.0/3.1支持Inter-Rack或Leaf交换机范围内的互连。
CXL 3.1 中发生了哪些变化?
现在,借助 CXL 3.0,机架间连接成为可能,但本文的主题是 CXL 3.1 中的这种变化。在 CXL 3.1 中:
1. 除了 HBR(基于层次结构的路由)之外,CXL 交换机之间的连接还支持 PBR(基于端口的路由)。
2. 添加了对 GIM(全局互连内存)的支持。
3. TEE(基于信任的路由) ).增加与执行环境兼容的安全协议
4. 内存扩展增强
这四项被列为附加项目。
首先,对于(1),除了2.0之前只有树形结构(USB是一个典型例子)的结构外,现在还支持交换机之间的点对点连接(图6)。这在构建大规模CXL交换网络时尤其有效。
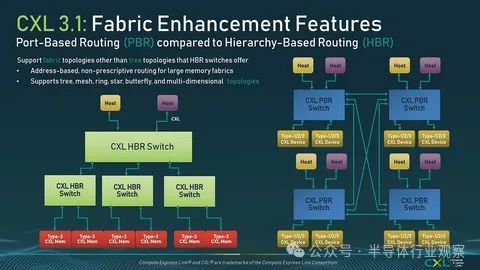
顺便说一句,可以混合 HBR 交换机和 PBR 交换机,并且它还支持链路聚合,通过在交换机之间创建多个链路来增加带宽,因此可以使用胖树而不是简单的树。(有没有意义是另一回事)。
接下来,关于(2),这可以被视为等同于通过CXL结构和FAM(结构附加存储器)附加到主机侧的存储器。在 CXL 3.0 之前,在连接到单个 CXL 交换机的两个主机之间共享内存的唯一方法是在两个主机之间共享 CXL 内存池(此处为 FAM)。不过,这一次,两台主机的本地内存(这里是GIM)可以直接共享,不需要FAM。
顺便说一句,为了加速这种内存共享,添加了一个名为 FAST(Fabric Address Segment Table)的新功能,它可以更轻松地访问。
与此相关,例如,当通过CXL从一台主机访问另一台主机的GIM时,“理论上”可以添加事务控制或保护功能,但事实并非如此。功能超出了本文的范围规格。” 我想第一步是使其易于访问。

关于(3),CXL 2.0最初包含一种称为IDE(完整性和数据加密)的机制,作为主机和设备之间的安全功能(图8)。CXL 3.1 通过允许将受信任的虚拟机与其他虚拟机流量分开处理来扩展此功能。在正常进行所谓的机密计算时,通常需要对物理资源进行划分,这就是与之相对应的一种形式。

最后(4)有几项。其中之一是直接 P2P(图 10)。首先,由于 CXL 是非对称配置的 I/F,因此 CXL 设备无法自行访问外部存储器(尽管可以从主机访问它们)。然而,在 CXL 3.1 中,通过使用 Direct P2P,现在可以访问连接到同一 CXL 交换机的 DSP(下游端口)的 CXL 内存。


我想你可以称之为 RDNA 的本地版本。以前在 CXL 中,加速器只能处理它们本地拥有的内存,但将来它们将能够使用外部内存池。
其他功能包括Memory Expander的扩展(例如,在CXL 3.0之前,元数据为2位,但在3.1中添加了对EMD的支持:扩展元数据,使得可以使用最多32位)和RAS功能的扩展。在CXL 3.1中被列为内存扩展增强项。
CXL 开关也不断发展
顺便说一下,如果要扩展这么多,当然CXL交换机端需要做很多工作。Fabric Manager 对此进行管理,并且添加了一个新的 API 来使用该 Fabric Manager(图 11)。

图12总结了CXL各个版本的规格差异,可以看出数量大幅增加,或者说系统互连自3.0左右以来已经发生了演变。
顺便说一下,CXL 3.0 或 3.1 兼容设备将在 PCI Express 6.0 推出的同时出现。就时序而言,还有很长的路要走,对于Intel来说,它将是在Granite Rapids等使用的LGA7529之后,对于AMD来说也是如此,它将是继Socket SP5(SP6?)。
预览最早可能会在 2025 年出现,但实际发货要到 2026 年才会发生。届时,PCI Express 7.0的标准化将指日可待,并且很可能会有更多有关支持它的CXL 4.0的活动。那么接下来会增加哪些功能呢?

原文链接:https://pc.watch.impress.co.jp/docs/column/tidbit/1571410.html