设计约束概述
设计约束就是定义编译过程中必须满足的需求,只有这样才能保证在板子上工作时功能正确。但不是全部约束在所有过程中都会使用,比如物理约束只用在布局和布线过程中。Vivado工具的综合和实现算法时时序驱动型的,因此必须创建合适的时序约束。我们必须根据应用需求选择合理的约束,过度约束或约束不足都会造成问题。
老版的ISE开发工具使用UCF(User Constraints File)文件进行约束;新的Vivado开发工具使用XDC(Xilinx Design Constraints)进行约束。在描述设计约束方面,标准SDC(Synopsys Design Constraints)格式已经发展超过了20年,且应用最为广泛。XDC约束正是基于SDC格式,再加入Xilinx的一些物理约束。
XDC约束可以用一个或多个XDC文件,也可以用Tcl脚本实现。XDC文件或Tcl脚本都要加入到工程的某个约束集(set)中。虽然一个约束集可以同时添加两种类型约束,但是Tcl脚本不受Vivado工具管理,因此无法修改其中的约束。
管理约束
Vivado支持使用一个或多个约束文件。对于大型设计来说,仅使用一个约束文件往往不便于维护。最好的做法是将时序约束和物理约束分别保存到不同的文件中。或者某些特定模块使用一个单独的约束文件。
约束文件(XDC文件或Tcl脚本)需要添加到约束集中。一个工程可以包含多个约束集,一个文件也可以添加到多个约束集中。如下图所示:
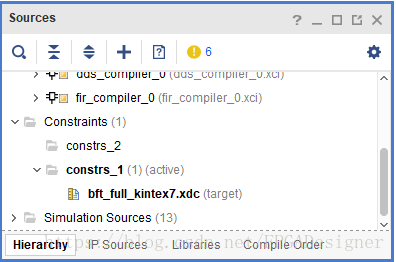
另外注意,生成IP核时,IP核的约束文件不会显示在上图列表中,只会显示在IP Sources窗口中。
默认情况下,所有的XDC约束文件会同时应用于综合和实现过程中。在XDC文件的属性窗口中修改如下图中选项,可以选择XDC文件的使用阶段,对应的属性为USED_IN_SYNTHESIS和USED_IN_IMPLEMENTATION:
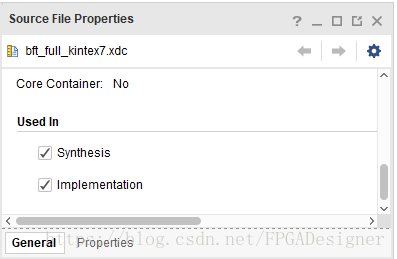
但是DONT_TOUCH属性不受上述设置的限制。比如在综合XDC中使用了DONT_TOUCH属性,即使Used In没有选中Implementation,该属性仍会传递到实现过程中。
排列约束的顺序
XDC约束会遵循一套优先级规则,按顺序应用于设计中。当多个物理约束之间产生矛盾时,顺序靠后的约束会覆盖之前的约束。比如一个I/O端口前后绑定了两个管脚位置,则顺序上靠后的约束会起作用。推荐的约束顺序如下:
约束应该以时钟定义开始,因为时钟必须在被其它约束引用之前定义好。如果在定义之前便引用了时钟,会导致错误发生,该约束将被忽略掉。约束文件的顺序相当重要,设计者应该确保每一个文件中的约束不依赖于其它文件中的约束。如果这种情况发生,应该考虑合并两个文件,或者按照更合理地方式重新组织约束文件。
所有新的约束都会保存到标记为target的XDC文件的末尾。如果约束集中有多个XDC文件,大多数情况下target文件不是最后一个XDC文件,这就导致保存到磁盘上的约束顺序和内存中的约束顺序并不相同(内存中执行相当于在最后插入一个新约束,而存储到磁盘中确是在中间插入了一个新约束),因此设计者需要验证最终存储的约束顺序可以正确工作。
每个约束文件都有PROCESSING_ORDER属性,属性值可以是:EARLY,必须首先被读取;NORMAL,默认;LATE:必须最后被读取。下面分两类文件讨论一下约束的读取顺序:
属性值为LATE的IP核XDC文件名称为

如果PROCESSING_ORDER属性相同,用户XDC文件可以通过拖拽移动来修改读取顺序,但IP核XDC文件的读取顺序无法直接修改。当然也有特殊方法可以实现,但基本不会使用,因此不做介绍。
约束方法
完成约束有两种方法:(1).直接编辑XDC文件;(2).打开某一阶段的设计,Elaborated设计、综合后设计或实现后设计,直接对某对象进行约束。采用第2种方法,在编辑约束时,Tcl控制台中会显示等价的XDC命令。该命令是存储在内存中的,在综合或实现前,必须点击Save Constraints保存约束。如果是新的约束,则会添加到标记为target的约束文件中;如果是对已存在的约束进行修改,则会修改XDC文件中原来位置的命令。
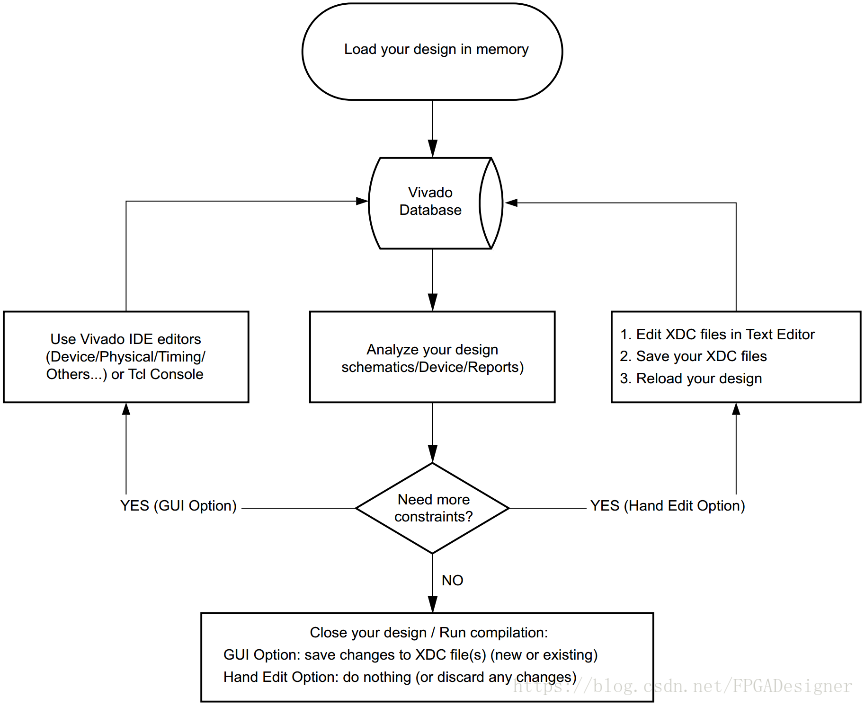
上述两种约束方法最好不要同时使用,否则容易混淆导致约束没有起作用。如果需要在两种约束方法之间切换,要确保保存了当前约束,或者重新导入一下设计。下图给出了约束的流程图:
管脚赋值与平面规划
本节介绍两种使用GUI完成约束的方法。第一种是创建与编辑顶层端口位置,即通常所说的管脚赋值(Pin Assignment)。打开某一阶段设计后,将视图切换为“I/O Planning”,如下图:
切换到该视图后会自动打开如下4个窗口:
另一种是平面规划(Floorplanning),主要是创建和编辑Pblock来限制某些对象的布局范围。打开某一阶段设计后,将视图切换为“Floorplanning”,如上图。切换到该视图后会自动打开如下3个窗口:
在Netlist窗口中选择某些单元,将其拖动到Device窗口的目标位置中,即可将单元位置约束到某一特定的BEL或SITE。这两个部分都可以称作“物理约束”,另外还有“时序约束”,需要借助时序约束向导,比较复杂,单独放在第30篇讲述。
创建综合约束
Vivado综合引擎将设计的RTL描述转换为一个工艺映射网表,在这个阶段可以使用约束来指导综合引擎解决设计需求。涉及到的约束包括4个方面:
注意上面之所以这样描述,是因为一些RTL名称再Elaborated设计中会被修改或删除,因此不能直接使用RTL设计中的对象名称。部分对象,如顶层端口、实例化原语再RTL和Elaborated设计中总是相同的,下面给出一些名称会发生变化的例子,需要特别注意:
总而言之,就是要明确约束的对象,否则很容易造成约束没有按设计者意图进行。比如不要对层次接口的管脚做约束,因为这些管脚仅仅起到了连接各个层次的作用;也不要对与组合逻辑运算符相连的网络做约束,因为组合逻辑运算会采用查找表方式实现,导致该网络并不会出现在综合网表中。
创建实现约束
综合过后,将综合网表和XDC文件(或Tcl脚本)一同导入到内存中,用于实现过程。导入时必须观察Vivado报告的消息,据此来验证和修改那些没有应用成功的约束。正如综合约束使用的Elaborated设计对象名称会和RTL中名称不同,实现约束使用的综合网表对象名称也可能会和Elaborated设计中的名称不同。如果发生上述情况,则必须重新创建某些约束,并仅作用于实现阶段。
前文也说过物理和配置约束仅会在实现阶段起作用,因此也最好存储到一个单独的XDC文件中,设置为仅作用于实现阶段。综合过程中可能会复制某些寄存器,以提高设计性能,必须使用get_cells/get_pins -include_replicated_objects命令获取对象,才能确保XDC约束也作用于复制出来的寄存器。我们当然很难直接感觉到哪个对象需要像上述这样做,幸好在Vivado中运行Methodology检查时,相关信息会报告在XDCV-1和XDCV-2检查信息中,供设计者参考。
约束作用域
一个特定的XDC文件中的约束可以选择仅作用于一个特定的模块,或设计中的特定单元。这种约束方式可称作块级约束,实现机制称作约束作用域机制。默认情况下,IP Catalog中导出的所有IP核都采用这种约束方式。该机制通过设置XDC文件的两个属性实现:
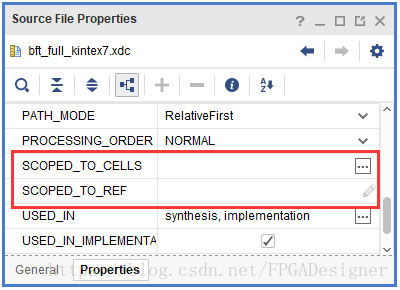
导出IP核时,输出的XDC文件会自动完成上述两个属性的设置。如果设计中需要为某个子模块进行单独约束,也可以通过手动设置上述两个属性实现。
约束效率
编写时序约束时,首要目标是让约束变得简单,仅为相关的网表对象设置约束,即为约束提供尽可能少的作用对象,以便精确并安全地覆盖到预期的时序路径。没有效率地约束会导致更长的运行时间、更大的内存占用率,最坏的情况是覆盖到比预期更多的路径从而与其它约束产生冲突,导致设计出现时序异常。
Vivado中Methodology检查的XDCB-1会报告涉及到超过1000个对象的时序约束,以防止出现时序异常情况。此外,还可以打开某一阶段设计后,使用如下命令查看相关报告:
时序异常的具体内容在本系列第32篇中介绍。下面给出几种改善约束运行时间的方法:
1.优化管脚查询方式
使用get_pins代替get_cells会对运行时间有明显的影响。如果需要从设计的所有管脚中查找一个管脚列表,不要直接根据管脚名字查询,最好是先用get_cells定位管脚所在的单元,再从该单元中查找管脚。示例如下:
get_pins –hier * -filter {NAME=~xx*/yy*} //不推荐的方式
get_pins –filter {REF_PIN_NAME=~yy*} –of [get_cells –hier xx*] //最佳方式
尤其对于大型设计,采用推荐方式进行约束可以显著改善查询时间。
2.不要使用all_registers查询
尽可能地将对all_registers的查询代替为对cells、pins的查询,因为使用all_registers会在大量对象中进行搜索。示例如下:
set_multicycle_path –from [all_inputs] –to [all_registers –clock clk1]
set_multicycle_path –from [all_inputs] –to [get_clocks clk1]
这两条约束是等价的,但第二种方式的效率比第一种要高很多。