Vivado版本:2019.2 Modelsim版本:Modelsim SE-64 10.7
说到 FPGA ,不得不提的是存储器,当我们做相关项目时,经常会遇到存储数据的问题,数据量过大时,我们可以将其存储在 FPGA 芯片的外设存储器上,比如 sdram、ddr sdram、ddr3 sdram等,然而访问外设存储器相对比较麻烦,因此当数据量较小时,我们可以直接使用 FPGA 芯片内部自带的 ram 的 IP 核。
Ram是random access memory的简称,即随机存储器的意思,Ram可以按照所需进行随机读/写。我们可以通过调用FPGA内部的IP核生成一个ram,并通过编写Verilog HDL代码控制该ram。
打开vivado软件,新建一个工程,配置芯片为xc7a75tfgg484-2:

进入工程,选择IP Catalog:

在IP Catalog界面搜索框中输入RAM,在Memories & storage Elements选项下有两种IP,一种是DRAM(Distributed Memory Generator),一种是BRAM(Block Memory Generator):
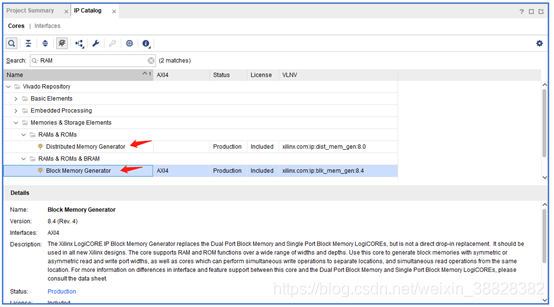
这里的DRAM并不是动态存储器,而是分布式存储器,与BRAM区别在于,DRAM通过FPGA中的查找表拼凑形成,而BRAM是FPGA中整块双口RAM资源。
这里学习BRAM的使用,双击Block Memory Generator。学习一个IP核,先看IP的官方手册,点击Documentation,在选项中选择Product Guide:

注意IP核的版本为8.4,按照IP核的设置找每个配置的含义:
IP名字保持默认;
Interface Type:支持AXI4 和AXI4Lite,默认为Native。
Memory Type:IP核支持生成5种类型的存储:
Single-port RAM
Simple Dual-port RAM
Ture Dual-port RAM
Single-port ROM
Dual-port ROM
Single-port RAM(单口RAM),通过单组接口读写一块存储空间,接口如下:

Simple Dual-port RAM(简单双口RAM),有A和B两组接口,其中A接口用来写RAM,B接口用来读RAM,接口如下:
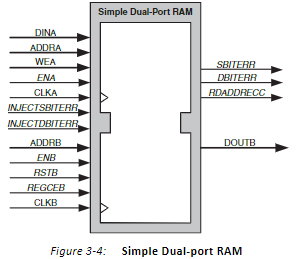
Ture Dual-port RAM(真双口RAM),有A和B两组接口,每一组接口都可以完成读和写操作,接口如下:

Single-port ROM(单口ROM),有单个接口读取存储空间,接口如下:
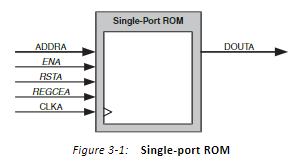
Dual-port ROM(双口ROM),有两组读取接口,接口如下:

ECC Options:只有Simple Dual-port RAM时,该选项才可用,IP核支持内置的汉明纠错功能(Built-in Hamming Error Correction Capability(BuiltIn ECC)),且支持数据位宽小于64位的软汉明纠错(soft ECC)。
Write Enable:设置是否启用字节写入,启用时,字节位宽可选为8位(无奇偶校验位)和9位(有奇偶校验位),此时数据位宽应是字节位宽的倍数,默认情况下不启用。
Algorithm Options:选择实现的内存算法。
Minimum Area Algorithm:使用最少数量的原语生成IP核;
Low Power Algorithm:低功耗算法,在读或写操作期间启用最小数量的块RAM原语;
Fixed Primitive Algorithm:固定单元算法,连接一个基本内存单元来生成IP核,在下拉列表中选择要使用的单元类型。
各芯片片内RAM资源如下:

这里选用Single-port RAM,其余保持默认。

配置端口A:
Write Width:写入位宽
Read Width:读出位宽,读写位宽可以不一致,IP核支持的读写位宽比例有:1:32、1:16、1:8、1:4、1:2、1:1、2:1、4:1、8:1、16:1、32:1。
Write Depth:写入深度
Read Depth:读出深度
Operating Mode:选项有Write First、Read First和No Change三种模式。
Enable Port Type:端口使能控制,可以使用ENA引脚控制,也可以选择always Enabled
Port A Optional Output Rregisters:选择是否在输出端添加寄存器
Port A Output Reset Options:配置复位信号
READ Address Change A:这个功能只在UltraScale设备上使用。
RAM写优先(Write First)时序如下,在ENA信号拉高后,在时钟上升沿检测ADDRA地址为aa,而WEA写使能为低,DOUTA就输出地址aa对应的数据;在第二个时钟上升沿,ENA为高,WEA信号为高,执行写操作,地址为bb,就将DINA上的数据1111写入存储中,并把DINA上的数据送到DOUTA上进行输出;在第三个时钟上升沿依然如此,将DINA数据写入存储同时将数据送到DOUTA上进行输出;第四个上升沿,ENA为高,WEA为低,执行读操作,地址为dd,就读取存储器地址dd中的数据送到DOUTA上进行输出。

RAM读优先时序如下:在ENA和WEA同时为高时,输出的数据是存储器存储的数据,同时,也会把新写入的数据替换掉存储器中的对应地址的数据。

RAM No Change模式:在ENA和WEA同时为高时,只进行写操作,不进行读操作,也就是说DOUTA保持前一拍数据,直到WEA为低。

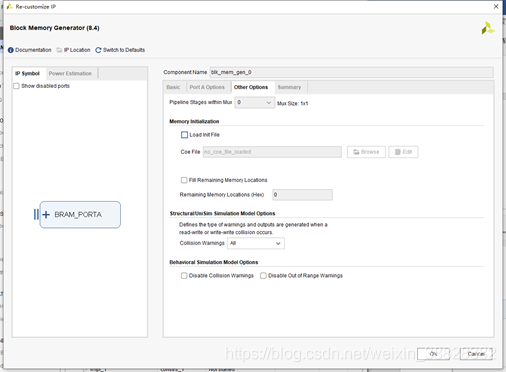
Pipeline Stages within Mux:输出端Mux流水线级数
Memory Initialization:选择是否使用本地初始化.coe文件初始化存储空间。以及是否使用默认值初始化内存。
Structural/UNISIM Simulation Model Options:选择发生碰撞时由结构仿真模型生成的警告消息和输出的类型。

点击OK生成IP核。
根据读写时序,编写tb测试激励文件来仿真这几种模式。
(1) 首先将RAM中的内存赋初值,为0到255循环递增数据。
(2) 然后在将地址设置为0,并修改之后的10个数据,观察时序,是否为写优先。

初始化内存 初始化为递增数据

将地址0到9的数据替换为随机数,与手册中写优先时序一致
(3) 在生成一个RAM,同样的位宽与深度,配置为读优先模式:
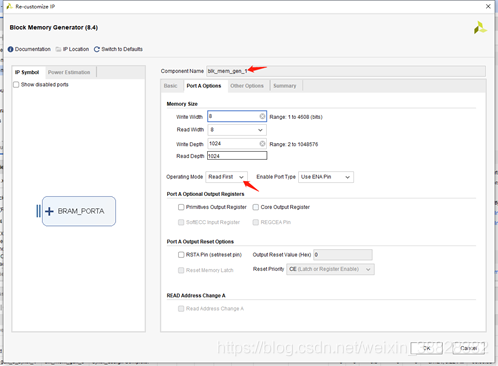
同样的数据下,读优先模式,数据输出内存中的旧数据,同时把新数据写入相应地址中,与读优先时序一致。

(4) No Change模式不再展示
(5) 双RAM读写冲突,如果一个端口写入数据,另一个端口读取相同地址,此时内
存中的数据可以被写入,但读出的数据取决于写入端口的操作模式,如果是读优先,则可以正常输出旧的数据,如果是写优先或不改变模式,则输出数据无效。
再生成一个RAM,Memory Type选择True Dual-port Ram
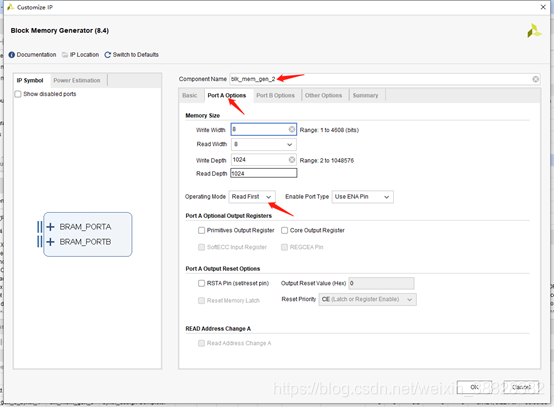
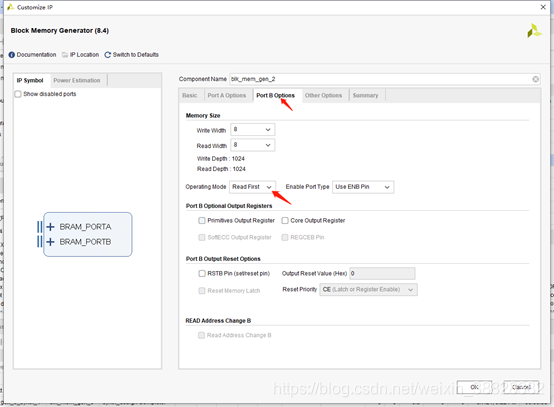
两个端口都选用读优先模式,然后通过A口写入数据,同时通过B口读取数据,查看读取内容。
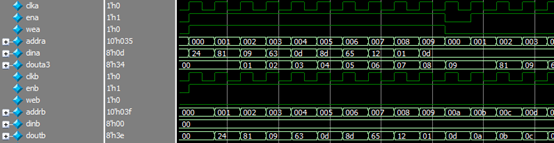
可以看到同步时钟下,通过A口写入的数据,在A口读出旧的数据,通过B口读出,则为新写入的数据。
(6) 使用异步时钟时,在一个端口往某个地址写数据时,另一个端口在指定时间内不能读或写该地址,在器件手册中定义了此置位时间。
(7) 数据位宽问题
读写位宽可以不一致,IP核支持的比例有1:32、1:16、1:8、1:4、1:2、1:1、2:1、4:1、8:1、16:1、32:1。当数据位宽不一致时,地址每次偏移值需要注意。
例如:写入位宽16位,读出位宽8位,此时写入地址每次递增为2,读出地址每次递增为1,这样才能将数据完全读出。
附:tb测试激励代码
`timescale 1ns / 1ps
module tb_ram();
reg clk;
initial begin
clk = 'b0;
forever #(5) clk = ~clk;
end
// synchronous reset
reg srstb;
initial begin
srstb <= 'b0;
repeat(10)@(posedge clk);
srstb <= 'b1;
end
// (*NOTE*) replace reset, clock, others
wire clka;
reg ena = 0;
reg wea = 0;
reg [ 9:0] addra = 0;
reg [ 7:0] dina = 0;
wire [ 7:0] douta;
wire [ 7:0] douta2;
wire [ 7:0] douta3;
wire clkb;
reg enb = 0;
reg web = 0;
reg [ 9:0] addrb = 0;
reg [ 7:0] dinb = 0;
wire [ 7:0] doutb;
reg [ 3:0] state = 0;
always @(posedge clk) begin
if (srstb == 1'b0) begin // reset
state <= 0;
ena <= 0;
wea <= 0;
addra <= 0;
dina <= 0;
end
else begin
case (state)
0 :state <= 1;
1 :begin
ena <= 1;
wea <= 1;
init_mem();
end
2 :begin
ena <= 1;
wea <= 1;
addra <= 0;
gen_data();
end
3 :begin
ena <= 1;
addra <= addra + 1;
end
default:state <= 3;
endcase
end
end
assign clka = clk;
blk_mem_gen_0 test_write_first (
.clka (clka ), // input wire clka
.ena (ena ), // input wire ena
.wea (wea ), // input wire [0 : 0] wea
.addra (addra ), // input wire [9 : 0] addra
.dina (dina ), // input wire [7 : 0] dina
.douta (douta ) // output wire [7 : 0] douta
);
blk_mem_gen_1 test_read_first (
.clka (clka ), // input wire clka
.ena (ena ), // input wire ena
.wea (wea ), // input wire [0 : 0] wea
.addra (addra ), // input wire [9 : 0] addra
.dina (dina ), // input wire [7 : 0] dina
.douta (douta2 ) // output wire [7 : 0] douta
);
assign clkb = clk;
always @(posedge clk) begin
if (srstb == 1'b0) begin // reset
enb <= 0;
addrb <= 0;
end
else if (state >= 2 && ena == 1'b1) begin
enb <= 1;
end
end
always @(posedge clk) begin
if (srstb == 1'b0) begin // reset
addrb <= 0;
end
else if (enb == 1'b1) begin
addrb <= addrb + 1;
end
end
blk_mem_gen_2 test_wr_Collisions (
.clka (clka ), // input wire clka
.ena (ena ), // input wire ena
.wea (wea ), // input wire [0 : 0] wea
.addra (addra ), // input wire [9 : 0] addra
.dina (dina ), // input wire [7 : 0] dina
.douta (douta3 ), // output wire [7 : 0] douta
.clkb (clkb ), // input wire clkb
.enb (enb ), // input wire enb
.web (web ), // input wire [0 : 0] web
.addrb (addrb ), // input wire [9 : 0] addrb
.dinb (dinb ), // input wire [7 : 0] dinb
.doutb (doutb ) // output wire [7 : 0] doutb
);
task init_mem;
integer i;
begin
for(i=0;i<1024;i=i+1)begin
dina <= i[7:0];
addra <= i[9:0];
@(posedge clk);
end
ena <= 0;
wea <= 0;
state <= 2;
end
endtask
task gen_data;
integer i;
begin
for(i=0;i<10;i=i+1)begin
dina <= {$random}%256;
addra <= addra + 1;
@(posedge clk);
end
ena <= 0;
wea <= 0;
addra <= 0;
state <= 3;
end
endtask
endmodule
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/weixin_38828382/article/details/116526478





